Instrumental variables
Packages
Here are the packages we will use in this lecture. If you don’t remember how to install them, you can have a look at the code.
- AER for the ivreg function.
- stargazer for nice tables
# install.packages( AER )
# install.packages( stargazer )
library( "AER" ) # To use the ivreg function. Make sure to install it beforehand (install.packages)
library( "stargazer" )What you should know after this lecture
- Under what circumstances do you need to use an instrumental variable? Why?
- What are the main characteristics of a valid instrumental variable?
- Understanding key mechanisms behind an instrumental variable model
1 The key concept
We use instrumental variables to address omitted variable bias. As you might remember, omitted variables are variables significantly correlated with an outcome variable (Y) but that cannot be observed or measured. Omitted variables are problematic when they are significantly correlated with both the outcome variable and a policy variable (X1) of interest because they can cause bias in the estimation of the coefficient.
Figure 1.1 illustrates the covariance structure of a model with an omitted variable correlated with both Y and X1:
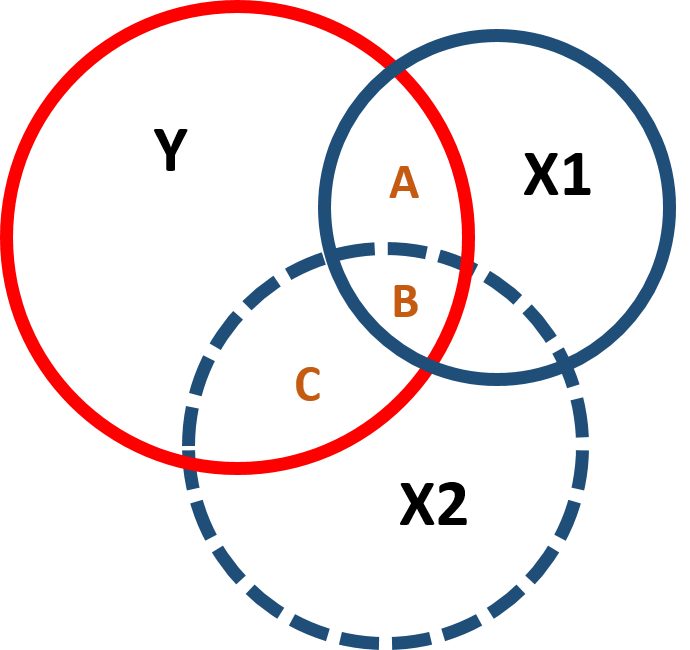
Figure 1.1: Covariance structure of an omitted variable model
In the illustrated case, the “full model” would include all variables, such as:
\[\begin{equation} Y=\beta_0 + \beta_1X_1 + \beta_2X_2 \tag{1.1} \end{equation}\]
In reality, the omitted variable cannot be observed nor measured, so we end up with a “naive model” where the omitted variable is excluded:
\[\begin{equation}
Y=\text{b}_0 + \text{b}_1X_1
\tag{1.2}
\end{equation}\]
When we omit a variable that is correlated with the policy and the outcome variable, it affects both the slope and the standard error of the model - you can observe this in figure 1.2. Including or excluding Ability significantly changes the covariance between Y and X1 (the intersection between Y and X1) and the residual of Y (the part of Y which does not intersect with X1 or X2).
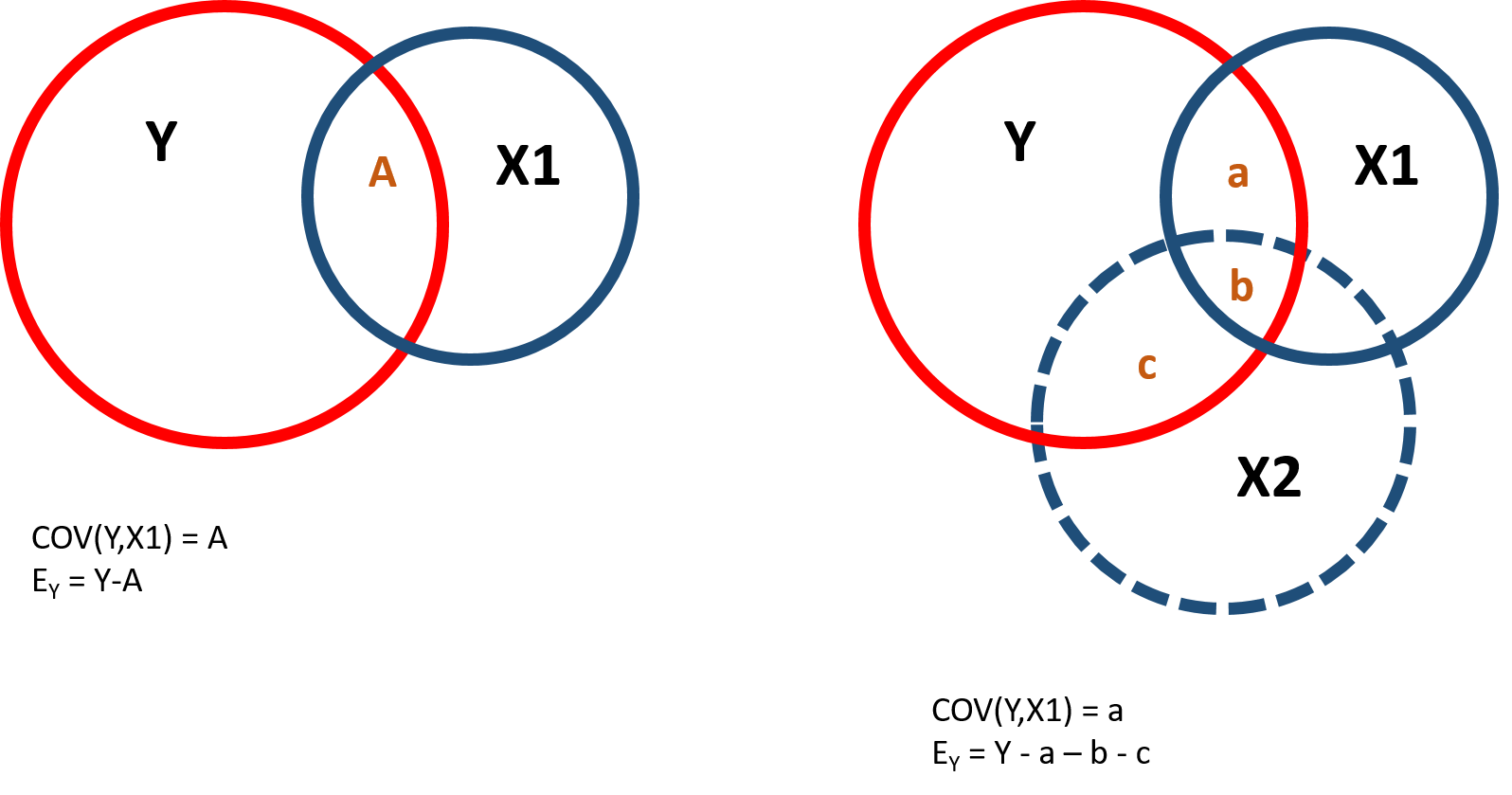
Figure 1.2: Covariance structure and residuals
Instrumental variables are helpful to reduce the omitted variable bias and get a more precise estimate of the effect of X1 on Y. An instrumental variable is a variable correlated with the policy variable, so that it can be a good “substitute” for it, but not correlated with the omitted variable, so as to reduce its interference in estimating the effect of Y. Figure 1.3 represents the covariance structure:
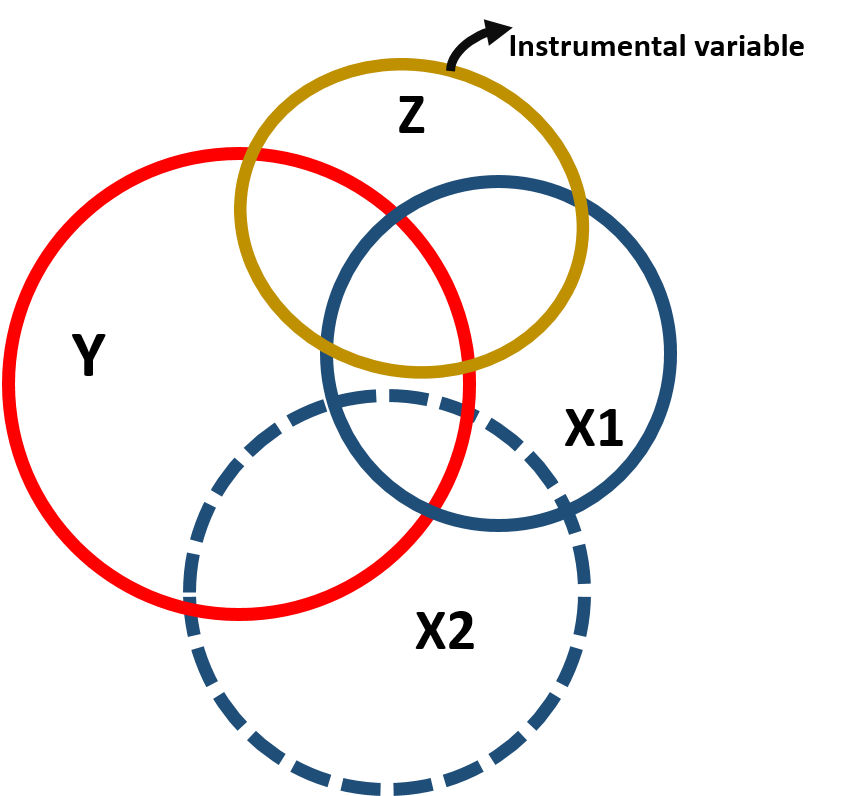
Figure 1.3: Instrumental variable modeal, covariance structure
Note that because the instrumental variable is correlated to the policy variable, it is also correlated with the outcome variable (figure 1.3). However, this correlation only occurs through X1 as illustrated in the path diagram.
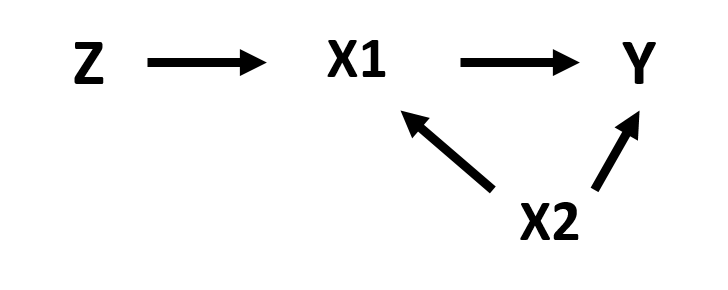
Figure 1.4: Path diagram of the instrumental variable model
We use the instrumental variable to partition the variance of the policy variable into 2 parts. One part (A) that is highly correlated with the instrumental variable and will be used to predict the outcome variable and one part (B+C) that is uncorrelated with the instrumental variable but it is correlated with the omitted variable and will be excluded from the model:
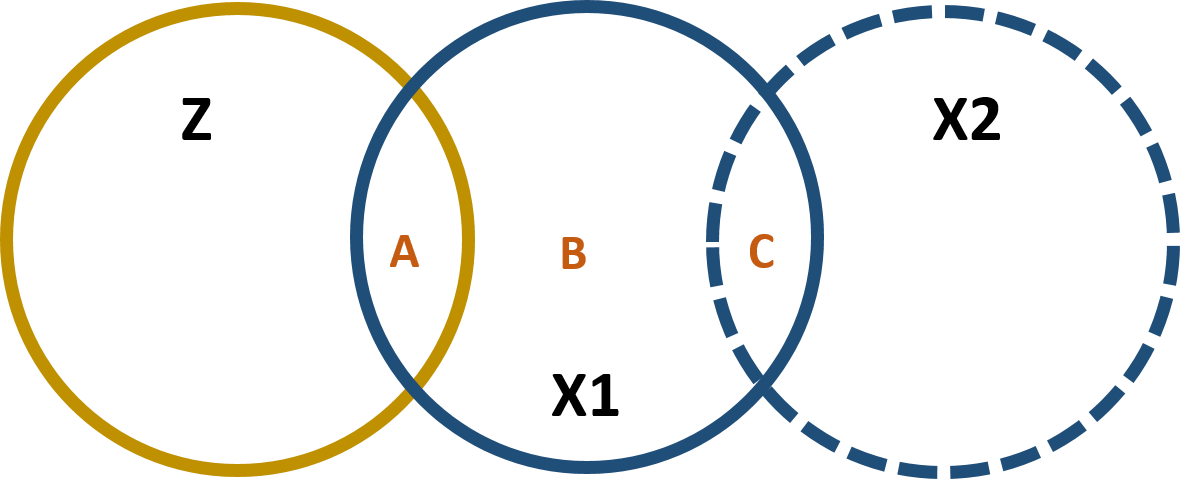
Figure 1.5: Partitioning the variance of X1
1.1 The statistical model
We can express this in formula, where we first predict X1 using Z:
\[\begin{equation} \text{X}_1 = \text{b}_0 + \text{b}_1 \text{Z}_1 + \text{e}_x \tag{1.3} \end{equation}\]
And then use the predicted value of X1 (the A section in figure 1.5) to predict Y. In this way we remove from the model the correlation between X1 and X2 (which is part of error term \(\text{e}_x\))
\[\begin{equation} \text{Y}_1 = \text{b}_0 + \text{b}_1 \text{X}_1 + \text{e}_y \tag{1.4} \end{equation}\]
2 An instrumental variable model

In the following working example, we will look at the correlation between hourly wage and education. The discussion regarding “more education, more income” gets continuous attention in the media and in the policy world (see for instance the New York Times). We ask: how much does your salary (Y) increase for any additional year of education? In other words, we are interested in estimating \(\beta_1\).
\[\begin{equation} Y=\beta_0 + \beta_1Education \tag{2.1} \end{equation}\]
2.1 Data
Data contain the following variables:
| Variable nameb | Description |
|---|---|
| wage | Wage |
| educ | Education |
| ability | Ability (omitted variable) |
| experience | Experience |
| fathereduc | Father’s education |
Our dependent variable represents an individual’s hourly wage in a given year in the United States. Our policy variable is the number of years that individuals have spent in school. We can look at some key summary statistics.
stargazer( dat,
type = "html",
omit = c("ability", "experience", "fathereduc"),
omit.summary.stat = c("p25", "p75"),
covariate.labels = c("Wage", "Education"),
digits = 2 )| Statistic | N | Mean | St. Dev. | Min | Max |
| Wage | 1,000 | 148.07 | 44.82 | 7.75 | 300.00 |
| Education | 1,000 | 16.35 | 2.29 | 10.00 | 23.00 |
When estimating the relationship between wage and education, scholars have encountered issues in dealing with the so-called “ability bias”: individuals who have higher ability are more likely both to stay longer in school and get a more highly paid job. We can represent these relationships in this diagram:
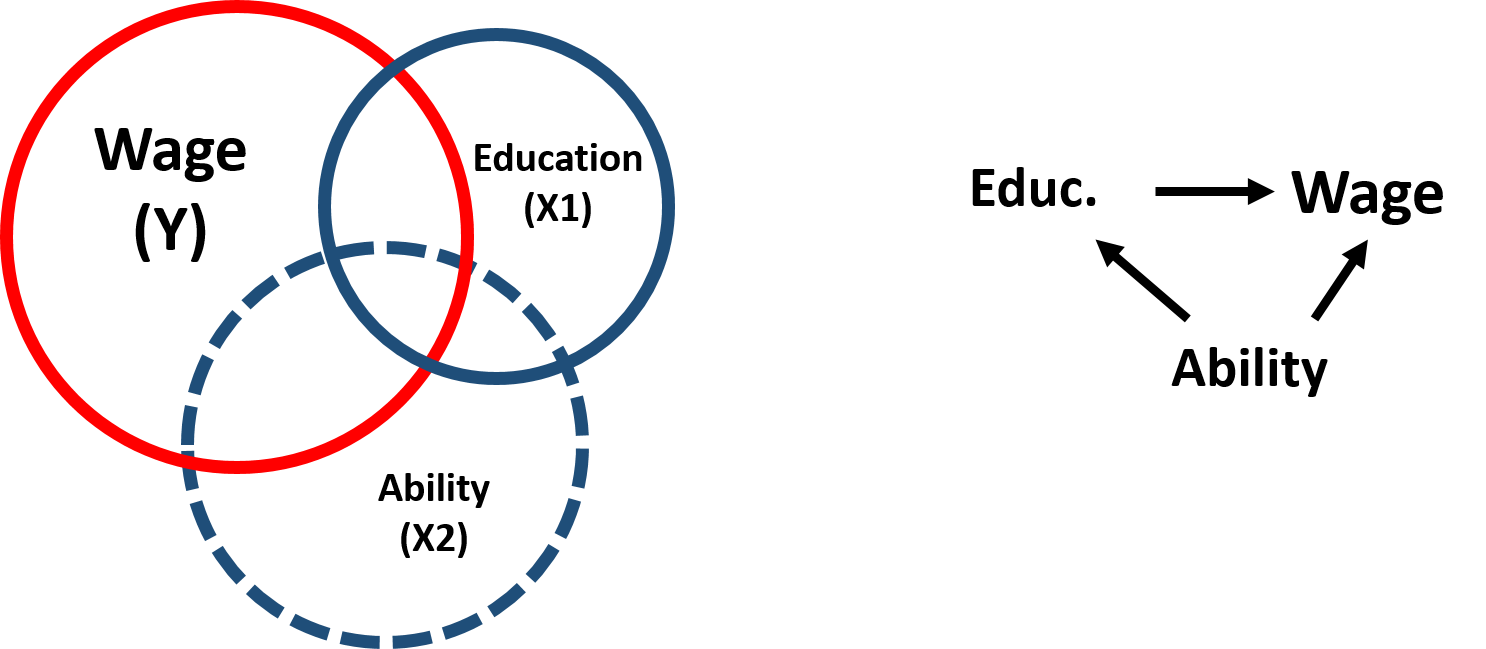
Figure 2.1: Ability bias
Ability, however, is difficult to measure and cannot be included in the model. It is an omitted variable, which is correlated with both our outcome variable and our policy variable. Excluding “ability” from the analysis creates a bias in the estimation of \(\beta_1\).
We can observe this bias with our simulated data. Let’s assume we can create a variable measuring ability and include it in our model (full model) based on equation (1.1) such that:
Let’s then run a more realistic model (naive model) based on equation (1.2) where the ability variable is excluded:
We can now compare the different estimates:
full.model <- lm( wage ~ educ + ability + experience ) # Full Model if we were able to measure ability
naive.model <- lm( wage ~ educ + experience ) # Naive Model where ability is excluded (omitted variable bias)
stargazer( full.model, naive.model,
type = "html",
dep.var.labels = ("Wage"),
column.labels = c("Full Model", "Naive Model"),
covariate.labels = c("Education", "Ability", "Experience"),
omit.stat = "all",
digits = 2 )| Dependent variable: | ||
| Wage | ||
| Full Model | Naive Model | |
| (1) | (2) | |
| Education | 8.76*** | 11.59*** |
| (0.32) | (0.48) | |
| Ability | 0.24*** | |
| (0.01) | ||
| Experience | 4.61*** | 4.24*** |
| (0.35) | (0.53) | |
| Constant | -97.89*** | -69.14*** |
| (5.23) | (7.83) | |
| Note: | p<0.1; p<0.05; p<0.01 | |
We note that the coefficient of the education variable is significantly different in the naive and the full model, where the naive model overestimate the effect of education on wage.
2.2 Analysis
In order to avoid the omitted variable bias we can introduce an instrumental variable. As mentioned above, the instrumental variable has these key characterististics:
- It is correlated with the policy variable.
- It is correlated to the dependent variable only through the policy variable.
- It is not correlated with the omitted variable.
While point #1 and #2 can be empirically tested, point #3 needs to be argued by theory.
We based our example on previous studies which utilize an individual’s father’s education as an instrumental variable ( Blackburn & Newmark, 1993; Hoogerheide et al. 2012 ). Individuals who come from more educated families are more likely to stay in school longer, especially when fathers are more educatedbut one’s father’s education has little to no direct effect on hourly wage.
We can empirically test these hypotheses by looking at correlations across the variables in our dataset. In the first graph, we can see that father’s education is positively correlated with education. In the second graph, there is a slight correlation between a father’s education and hourly wage. We would expect this, because education and hourly wage are correlated. However, we theoretically argue that there is no direct correlation: a father’s education increases the hourly wage only because it increases one’s education, which in turn leads to a higher salary. Finally, in the third graph, we can see that there is no correlation between father’s education and ability.
par( mfrow=c(1,3) )
plot(fathereduc, educ, xlab = "Father's education", ylab = "Education" ) # Plot
abline( lm( educ ~ fathereduc ), col = "red") # regression line
plot( fathereduc, wage, xlab = "Father's education", ylab = "Hourly wage" )
abline(lm( wage ~ fathereduc ), col = "green")
plot( fathereduc, ability, xlab = "Father's education", ylab = "Ability")
abline(lm( ability ~ fathereduc ), col = "blue")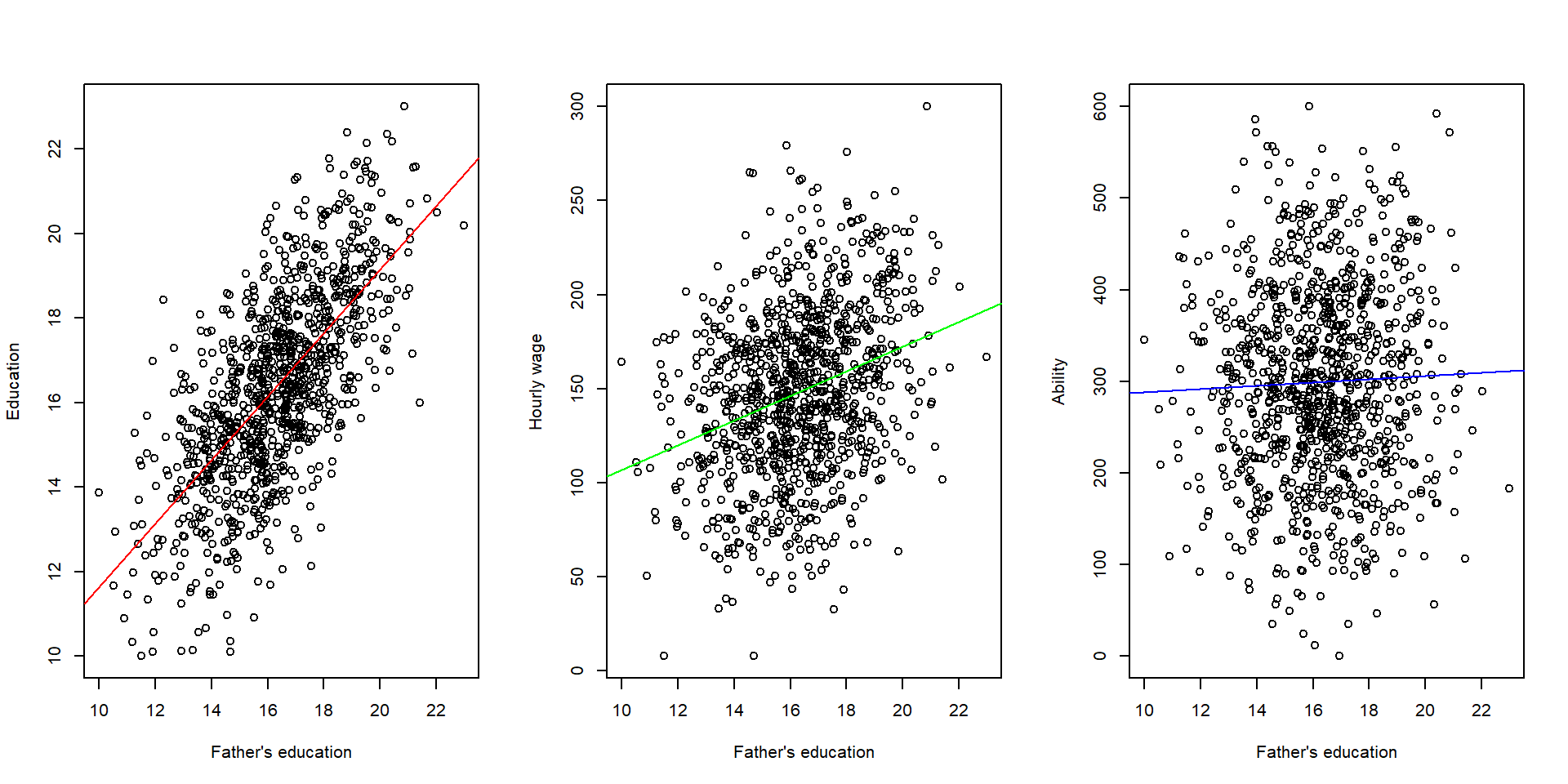
We now run the model using our instrumental variable. The model is defined in two stages: first, we estimate our policy variable based on our instrumental variable (equation (1.3)):
First stage:
first.stage <- lm( educ ~ fathereduc + experience) #Run the first stage predict the education variable
stargazer( first.stage,
type = "html",
dep.var.labels = ("Education"),
column.labels = c("First stage"),
omit.stat = c("adj.rsq", "ser"),
covariate.labels = c("Father's education", "Experience"),
digits = 2 )| Dependent variable: | |
| Education | |
| First stage | |
| Father’s education | 0.75*** |
| (0.02) | |
| Experience | 0.26*** |
| (0.02) | |
| Constant | 2.44*** |
| (0.43) | |
| Observations | 1,000 |
| R2 | 0.52 |
| F Statistic | 541.18*** (df = 2; 997) |
| Note: | p<0.1; p<0.05; p<0.01 |
Then, we estimate our dependent variable (Wage) using the predicted values of education estimated in the first model (equation (1.4)):
Second stage:
x1_hat <- fitted( first.stage )
#Saved the predicted values of education from the first stage
second.stage <- lm( wage ~ x1_hat + experience )
#Run the 2nd stage using the predicted values of education to look at the effect on income.
stargazer( full.model, naive.model, second.stage,
type = "html",
dep.var.labels = ("Wage"),
column.labels = c("Full Model", "Naive Model", "IV model"),
omit.stat = c("adj.rsq", "ser"),
covariate.labels = c("Education", "Ability", "Predicted Education", "Experience"),
digits = 2 )| Dependent variable: | |||
| Wage | |||
| Full Model | Naive Model | IV model | |
| (1) | (2) | (3) | |
| Education | 8.76*** | 11.59*** | |
| (0.32) | (0.48) | ||
| Ability | 0.24*** | ||
| (0.01) | |||
| Predicted Education | 8.76*** | ||
| (0.81) | |||
| Experience | 4.61*** | 4.24*** | 4.96*** |
| (0.35) | (0.53) | (0.64) | |
| Constant | -97.89*** | -69.14*** | -27.56** |
| (5.23) | (7.83) | (12.62) | |
| Observations | 1,000 | 1,000 | 1,000 |
| R2 | 0.76 | 0.44 | 0.20 |
| F Statistic | 1,033.66*** (df = 3; 996) | 394.18*** (df = 2; 997) | 127.80*** (df = 2; 997) |
| Note: | p<0.1; p<0.05; p<0.01 | ||
Note that the table report the “true”" model (full model) where we include all variables, the naive model where we omit the ability variable, and the instrumental variable model where we use the predicted values of the first stage. The IV model has almost completely recovered the true slope.
2.3 Additional explanation: plotting the results
Using our simulated data, we can have a look at what is happening when we estimate the model with an instrument variable.
We know that omitted variable bias results from the correlation of our policy variable (Education) and the omitted variable (Ability).
plot(ability, educ, xlab = "Ability", ylab = "Education")
abline(lm( educ ~ ability ), col = "green")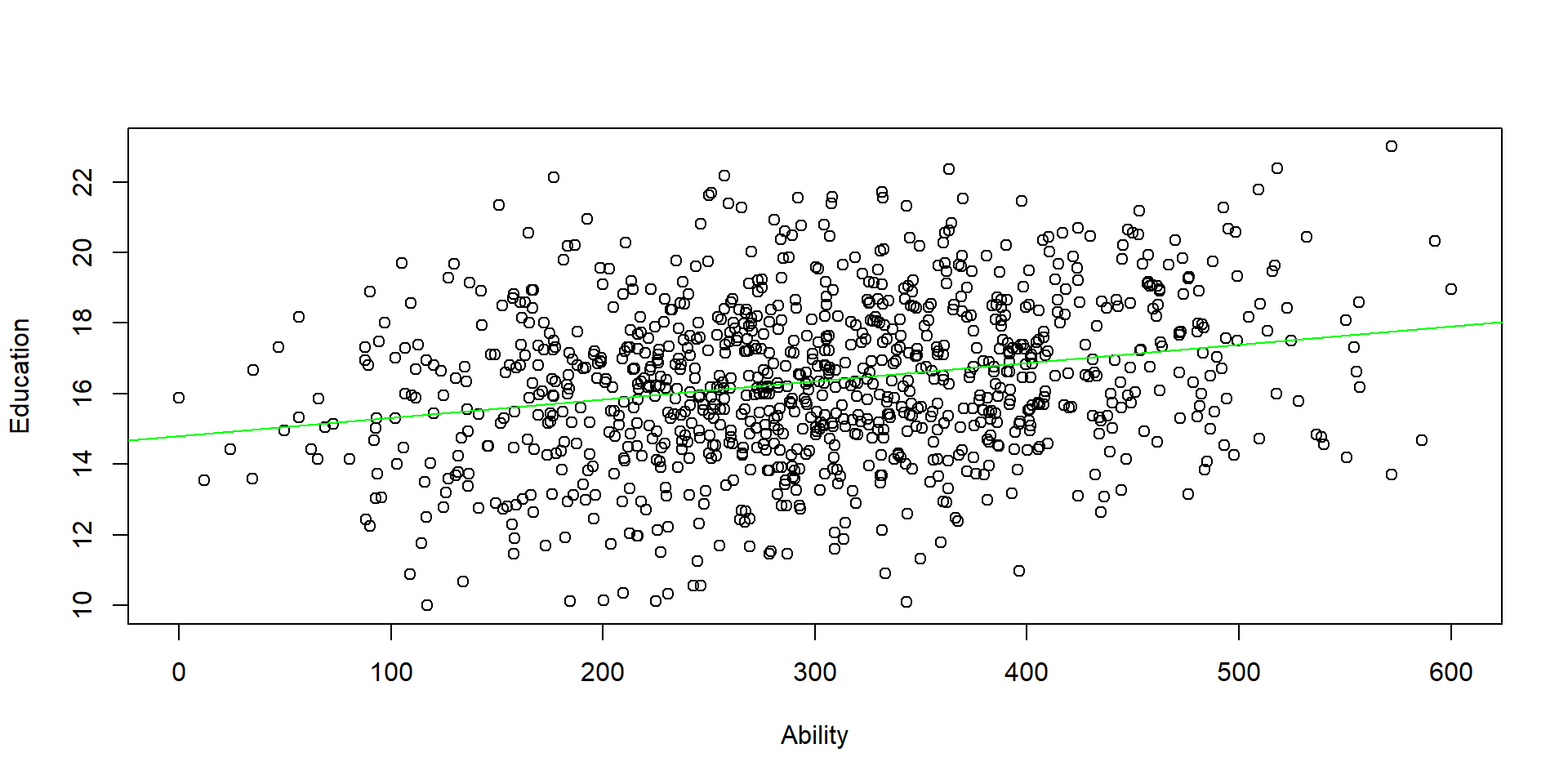
Figure 2.2: Relationship between Y and the omitted variable
The instrumental variable, however, is correlated only with the policy variable, not the omitted variable. Therefore, we can use the instrumental variable to partition the variance of education into a component that is highly correlated with ability (the residual), and a component that is uncorrelated with ability (X1-hat). Remember the figure 1.5 we discussed at the beginning of the lecture:

Figure 2.3: Instrumental variable model
To see this in practice, we can plot the predicted values (x1_hat) and the residual (e_x1) of the first stage in two graphs and look at the correlation with the omitted variable ability. You can see that there is almost no correlation between h1_hat and ability, but ability is highly correlated with the residual (e_x1).
first.stage <- lm( educ ~ fathereduc + experience ) #Run again the first stage to predict education (x1)
x1_hat <- fitted( first.stage ) #Save the predicted values of education (x1_hat)
e_x1 <- residuals( first.stage ) #Save residuals of education (e_x1)
par( mfrow=c(1,2) )
#Plot the predicted values against ability
plot( ability, x1_hat, xlab = "Ability (omitted variable)", ylab = "Predicted values of Education (x1_hat)")
abline( lm( x1_hat ~ ability), col = "blue")
#Plot the residual against ability
plot( ability, e_x1, xlab = "Ability (omitted variable)", ylab = "Education - Residual (e_X1)" )
abline( lm( e_x1 ~ ability), col = "green")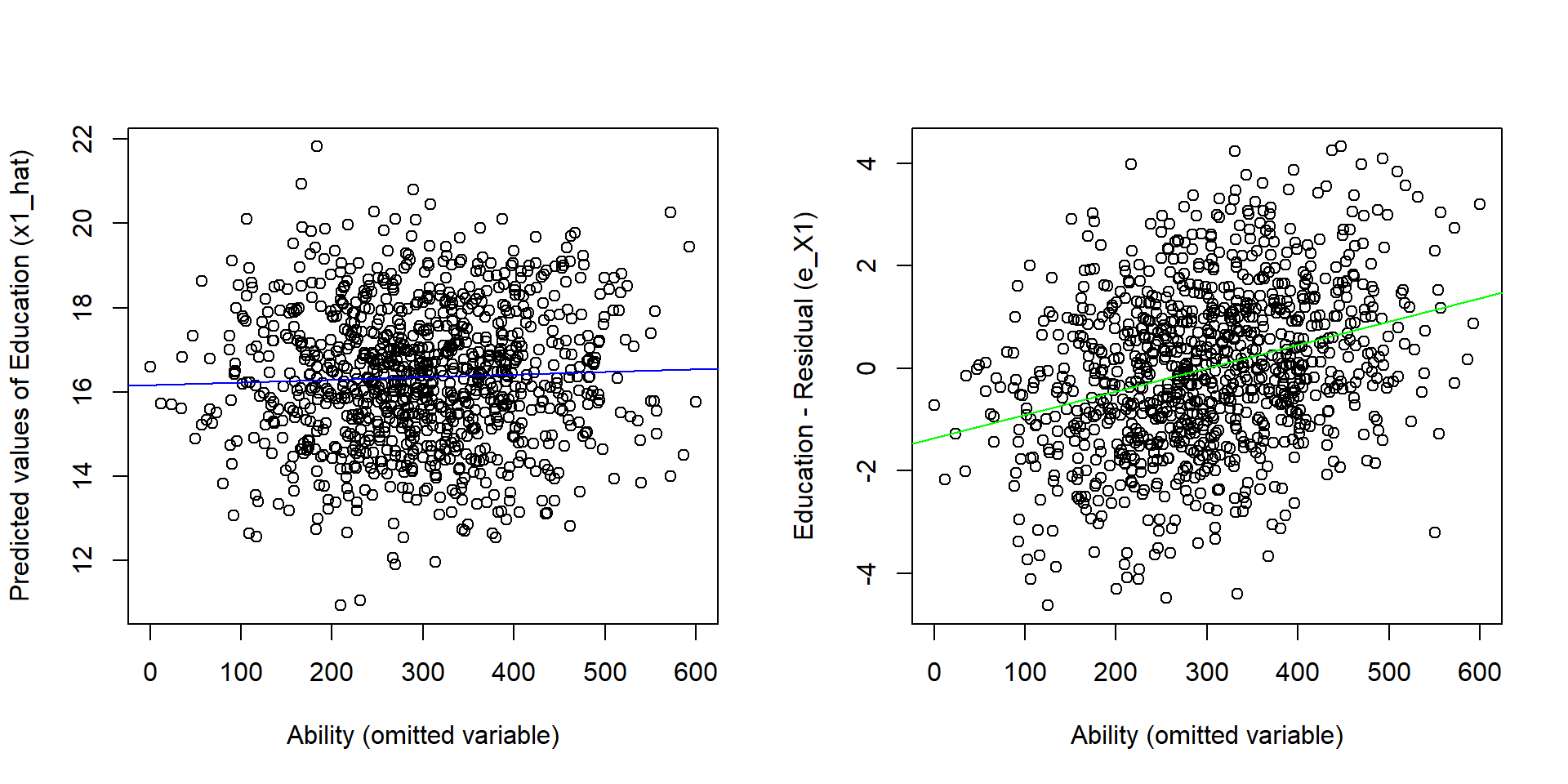
Figure 2.4: Partitioning the variance of Education
One interesting thing about the instrumental variable model is that Education will be more correlated with Wage than X1-hat, but X1-hat does a better job of recovering the true slope B1 from the full model.
par( mfrow=c(1,2) )
plot( educ, wage, xlab = "Education", ylab = "Wage" )
abline( lm( wage ~ educ), col = "red")
plot( x1_hat, wage, xlab = "Predicted values of Education (x1_hat)", ylab = "Wage" )
abline( lm( wage ~ x1_hat), col = "blue")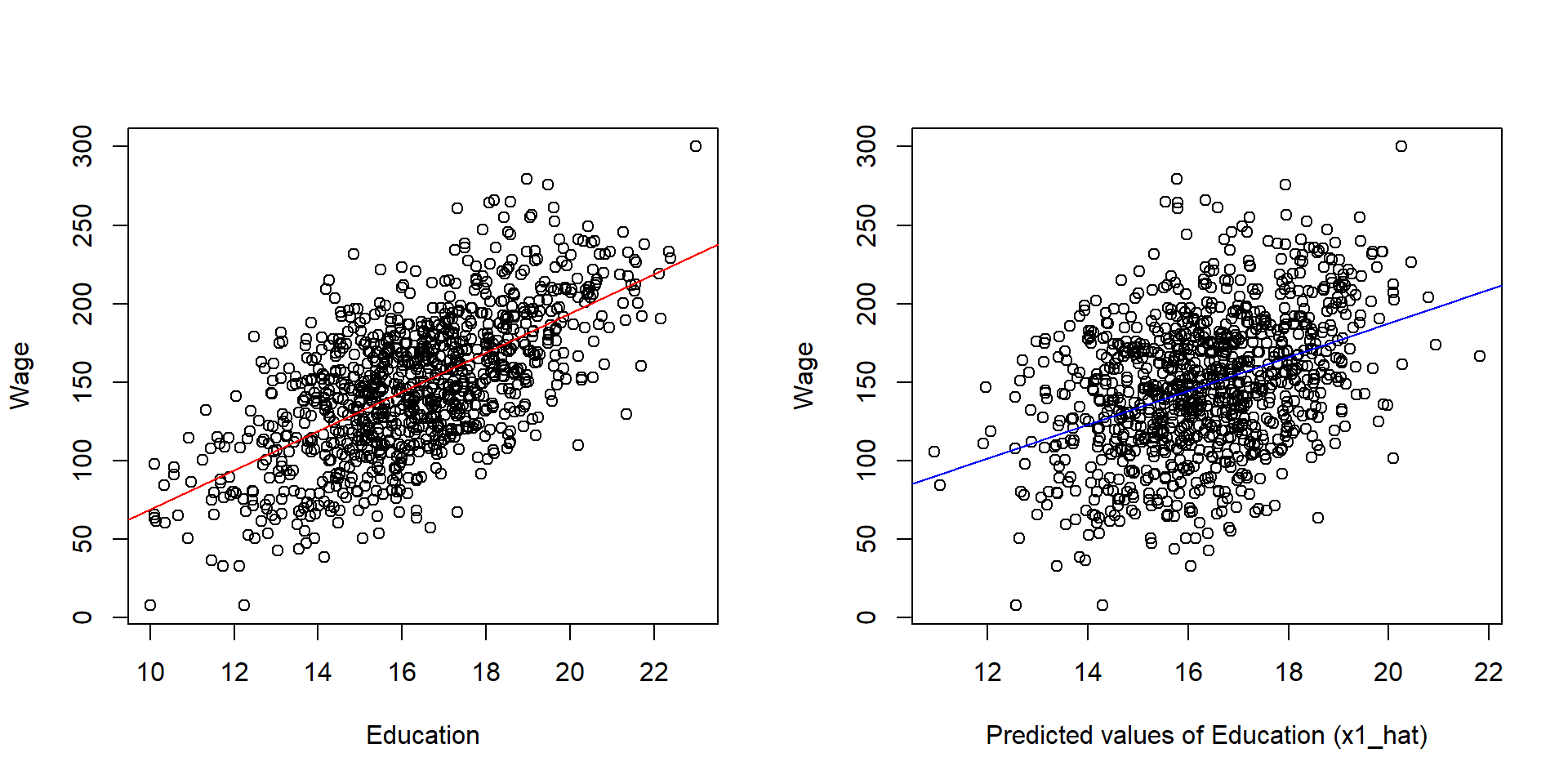
Figure 2.5: Relationship between the ‘parts’ of education and Y
2.4 Summary: How to select a valid instrumental variable
Some things you should keep in mind about instrumental variables and how to select a valid one.
- An instrumental variable should be strongly correlated with your policy variable; the higher the correlation, the better. You can empirically test how ‘good’ the correlation is, when running the first stage. The rule of thumb is that the first stage should have an F Statistic of at least 10 in the first stage model to avoid the weak instrument problem.`
first.stage <- lm( educ ~ fathereduc + ability )
stargazer( first.stage,
column.labels = c("First Stage"),
type="html",
covariate.labels = c("Father's education", "Experience"),
omit.stat = c("rsq","ser"),
digits = 2 )| Dependent variable: | |
| educ | |
| First Stage | |
| Father’s education | 0.74*** |
| (0.02) | |
| Experience | 0.005*** |
| (0.0005) | |
| Constant | 2.85*** |
| (0.42) | |
| Observations | 1,000 |
| Adjusted R2 | 0.51 |
| F Statistic | 529.26*** (df = 2; 997) |
| Note: | p<0.1; p<0.05; p<0.01 |
If your instrumental variable is weak, it means that it is little correlated with the policy variable, so it does a “bad” job in approximating its effect on the policy outcome. You might find no policy effect even if there is one! You need to have strong evidence that the instrumental variable does a good job in approximating the policy variable (e.g., the F test) before concluding that the policy has no effect.
- Because the instrumental variable is correlated with the policy variable and the policy variable is correlated with the outcome variable, the instrumental variable is also correlated with the outcome. See for instance the correlation between father’s education and wage.
plot( fathereduc, wage, xlab = "Father's education", ylab = "Hourly wage")
abline(lm( wage ~ fathereduc ), col = "green") 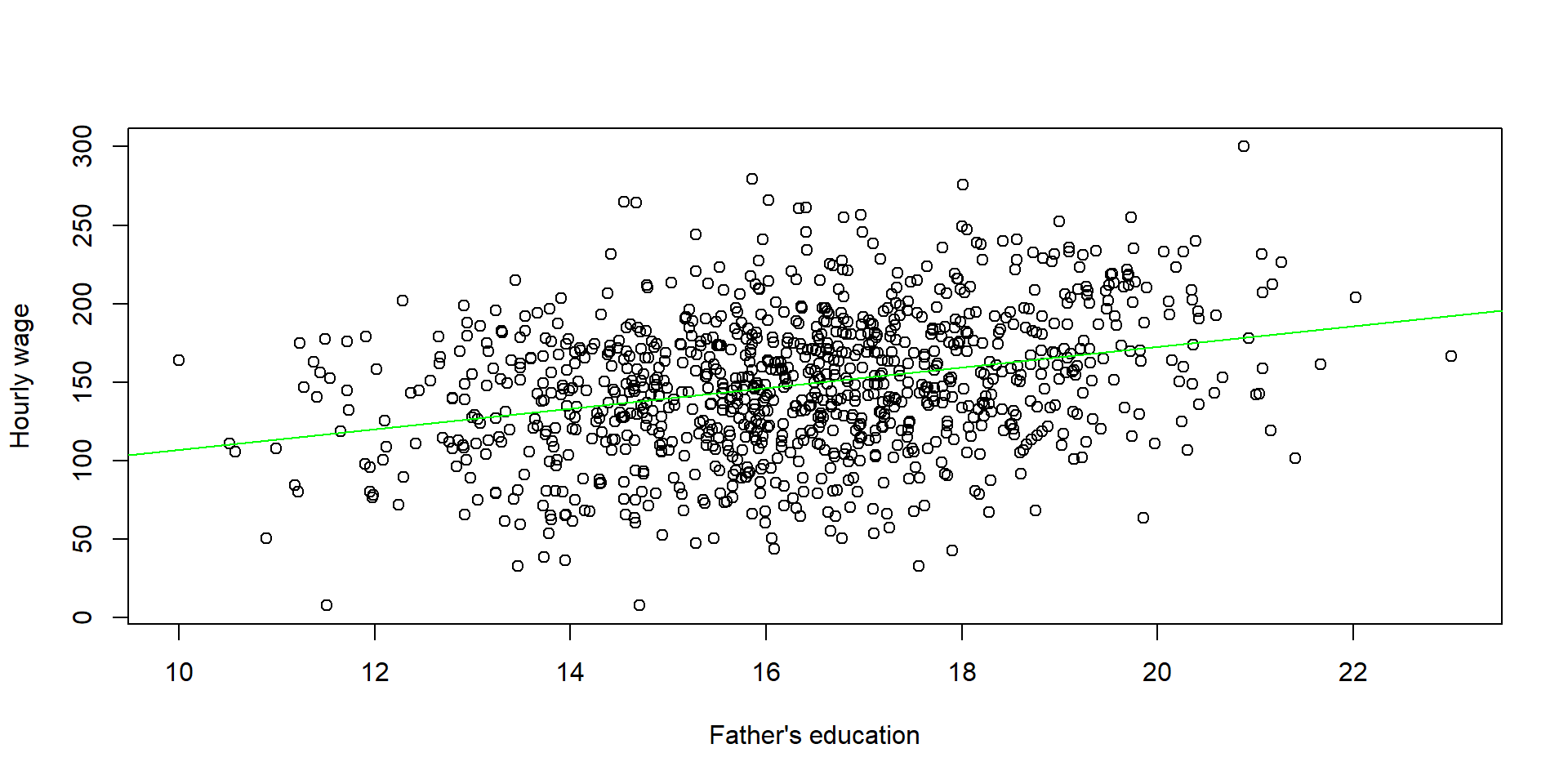
Figure 2.6: Correlation between Y and the omitted variable
However, it is important to be able to argue that such correlation occurs only through the policy variable and there is no direct correlation between the instrumental and the outcome variable.

Figure 2.7: Instrumental variable model, path diagram
In our previous example, a father’s education increases the hourly wage only if it makes an individual stays longer in school. If not, it has no effect on the wage.
The lack of direct correlation between the instrumental and the oucome variable is argued through theory and previous studies.
- To recap, the covariance structure among the variables in an omitted variable model can be summarized in the following table, where:
- Wage is the outcome variable
- Education is the policy variable
- Ability is the omitted variable
- Experience is a control variable
- Father’s education is the instrumental variable
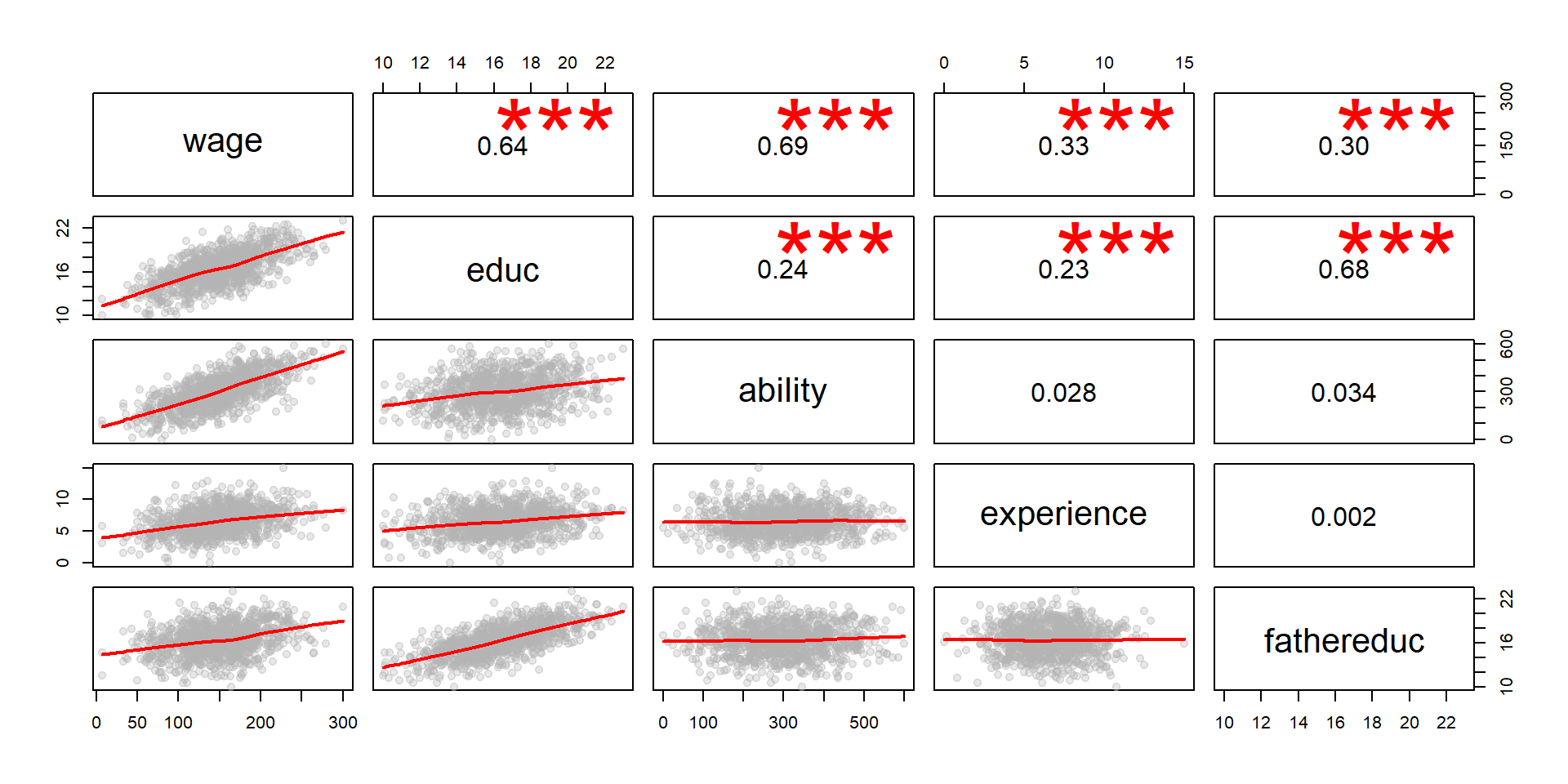
Figure 2.8: Correlation matrix structure
- Finding a valid instrumental variable is challenging, requires creativity and some review of previous studies to get ideas and preliminary assess the correlation between the model variables.
3 Replication of a study
We now look at data that have been used by Card in 1995 for estimating a similar model. The dataset is contained in the Wooldrige package and you can download it to replicate this exercise.
install.packages( "wooldridge", repos="https://cran.cnr.berkeley.edu" )
library( "wooldridge" )3.1 Data
The dataset contains 3,010 observations collected in 1966/1976.
data( "card" ) ## we attach the data to our R working space
nrow( card ) ## To check if data were properly load, we can look if the number of obs is equal to 3010## [1] 3010For this exercise we are going to use the following variables. You can find a description of all variables here.
| Variable name | Description |
|---|---|
| lwage | Annual wage (log form) |
| educ | Years of education |
| nearc4 | Living close to college (=1) or far from college (=0) |
| smsa | Living in metropolitan area (=1) or not (=0) |
| exper | Years of experience |
| expersq | Years of experience (squared term) |
| black | Black (=1), not black (=0) |
| south | Living in the south (=1) or not (=0) |
3.2 Analysis
As we did before, Card wants to estimate the impact of education on wage. But to solve the ability bias, he utilizes a different instrumental variable: proximity to college. He provides arguments to support each of three main characteristics of a good instrumental variable:
- It is correlated with the policy variable: Individuals who live close to a 4-year college have easier access to education at a lower costs (no communiting costs and time nor accomodation costs), so they have greater incentives to pursue education.
- It is not correlated with the omitted variable: Individual ability does not depend on proximity to a college.
- It is correlated to the dependent variable only through the policy variable: Proximity to a college has no effect on your annual income, unless you decide to pursue further education because of the nearby college.
Therefore, he estimates a model where:
First stage (equation (1.3))
Second stage (equation (1.4))
We replicate the study starting by having a look at the summary statistics and distribution of the 3 key variables:
stargazer( card,
type = "html",
keep = c("lwage", "^educ$", "nearc4"),
omit.summary.stat = c("p25", "p75"),
digits = 2 )| Statistic | N | Mean | St. Dev. | Min | Max |
| nearc4 | 3,010 | 0.68 | 0.47 | 0 | 1 |
| educ | 3,010 | 13.26 | 2.68 | 1 | 18 |
| lwage | 3,010 | 6.26 | 0.44 | 4.61 | 7.78 |
#Note: the symbols ^ & $ around educ prevents the function from grabbing other variables containing educ, such as fatheduc or mothedutpar( mfrow=c(1,2) )
plot( density(card$lwage), xlab = "Wage", main = "Dependent variable", ylab = "Frequency")
plot( density(card$educ), xlab = "Education", main = "Policy variable", ylab = "Frequency")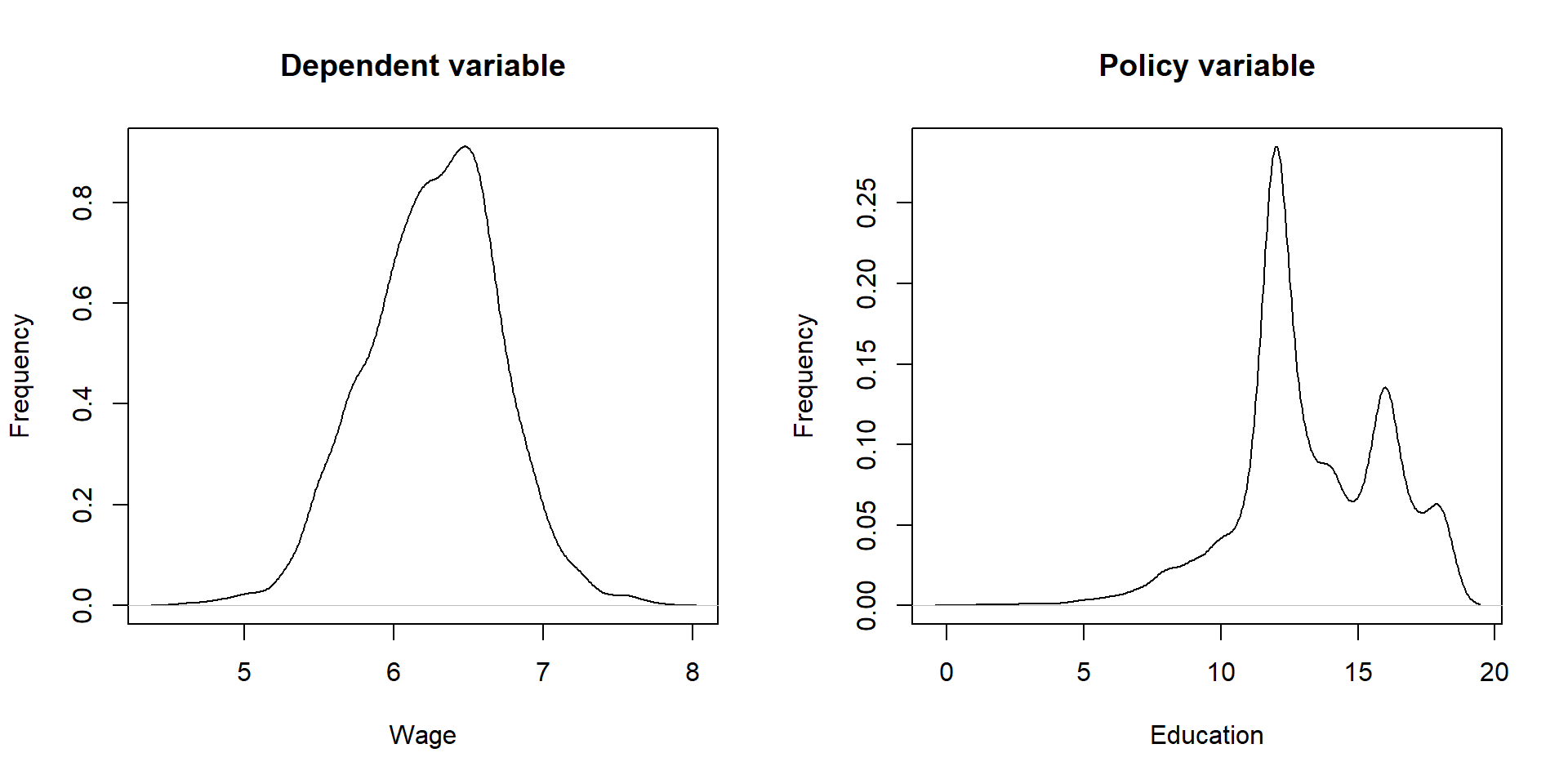
Figure 3.1: Distribution of Y, X, and Z
barplot( table(card$nearc4), xlab = "Living near a four-year college", ylab = "Frequency", main = "Instrumental variable")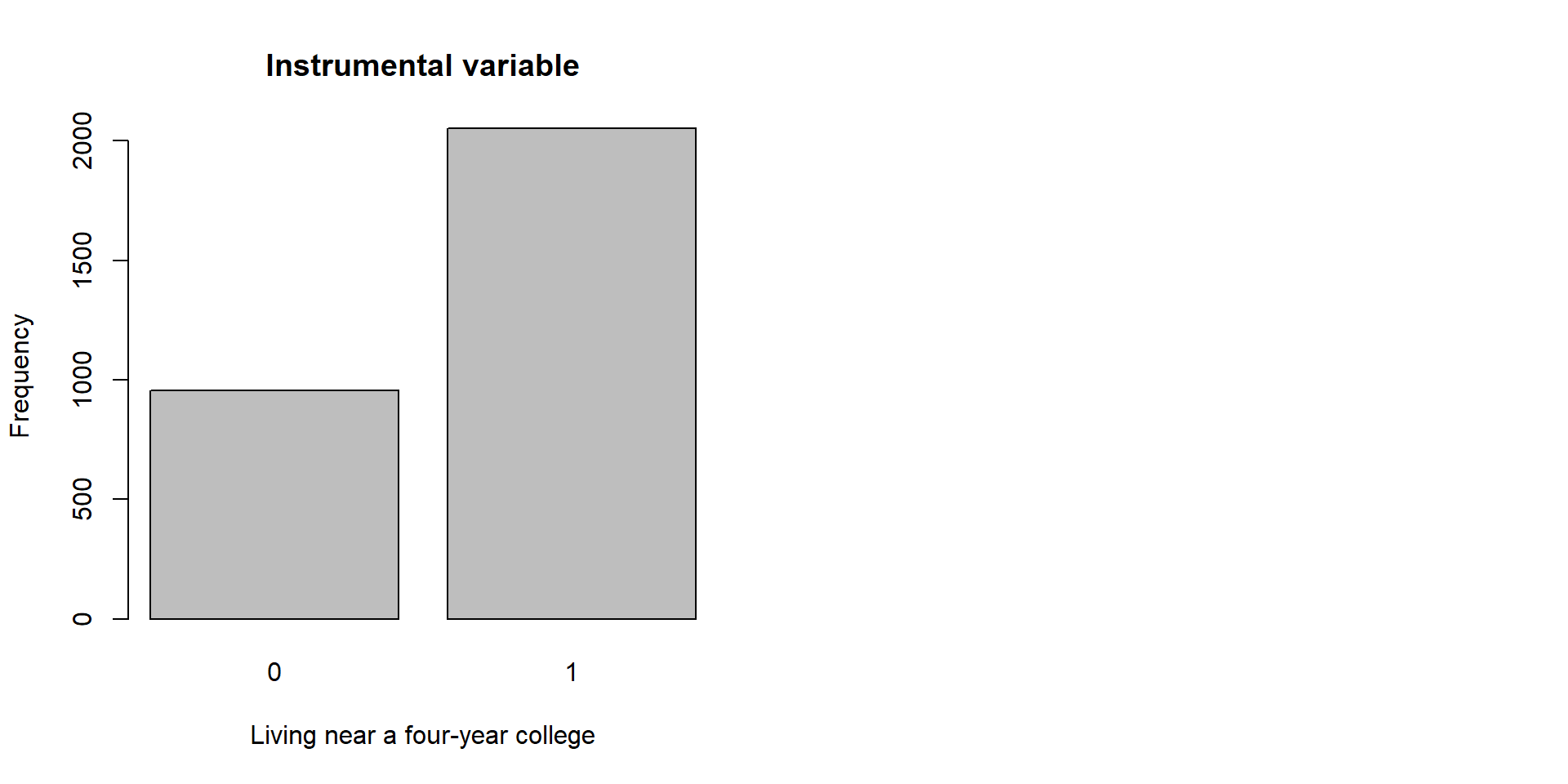
Figure 3.1: Distribution of Y, X, and Z
We then estimate the model using two stages. As before, in the first stage we estimate education using our instrumental variable; you can see that the F statistic is greater than 10, suggesting that \(\text{nearc4}\) is a valid instrumental variable. Then, we estimate the impact of education on wage using the predicted values of education.
first.stage = lm(educ ~
nearc4 +
smsa66 +
exper +
expersq +
black +
south66, data = card)
x1_hat <- fitted( first.stage ) #Save predicted values for education
second.stage <- lm(lwage ~
x1_hat +
smsa66 +
exper +
expersq +
black +
south66, data = card)
stargazer( first.stage, second.stage,
column.labels = c("First Stage", "Second Stage"),
type = "html",
omit.stat = c("rsq","ser"),
digits = 2 )| Dependent variable: | ||
| educ | lwage | |
| First Stage | Second Stage | |
| (1) | (2) | |
| nearc4 | 0.33*** | |
| (0.09) | ||
| x1_hat | 0.16*** | |
| (0.05) | ||
| smsa66 | 0.25*** | 0.08*** |
| (0.08) | (0.03) | |
| exper | -0.41*** | 0.12*** |
| (0.03) | (0.02) | |
| expersq | 0.0005 | -0.002*** |
| (0.002) | (0.0003) | |
| black | -0.92*** | -0.10* |
| (0.09) | (0.05) | |
| south66 | -0.35*** | -0.06** |
| (0.08) | (0.03) | |
| Constant | 16.81*** | 3.36*** |
| (0.17) | (0.93) | |
| Observations | 3,010 | 3,010 |
| Adjusted R2 | 0.47 | 0.16 |
| F Statistic (df = 6; 3003) | 448.71*** | 95.16*** |
| Note: | p<0.1; p<0.05; p<0.01 | |
As you can see, our policy variable has a different estimate in the two models.
naive.model <- lm(lwage ~
educ +
smsa66 +
exper +
expersq +
black +
south66, data = card)
stargazer( naive.model, second.stage,
model.numbers = F,
type = "html",
omit.stat = "all",
digits = 2, keep = c("educ", "x1_hat") )| Dependent variable: | ||
| lwage | ||
| educ | 0.08*** | |
| (0.004) | ||
| x1_hat | 0.16*** | |
| (0.05) | ||
| Note: | p<0.1; p<0.05; p<0.01 | |
4 Additional notes
4.1 ivreg function
If you like to explore new R functions, you can use the ivreg function from the package AER to calculate your instrumental variable model. See the example below using the same data as in the Card’s example.
Note the syntax for using the ivreg function.
simple.model <- lm(
lwage ~
educ +
smsa66 +
exper +
expersq +
black +
south66, data = card)
ivreg.model <-
ivreg( ## Call the ivreg function
lwage ~ ## Dependent variable of the second stage
educ + ## Education, as estimated in the first stage below
smsa66 + ## Control variable - Living in a metropolitan area
exper + ## Control variable - Expertise
expersq + ## Control variable - Squared term of the expertise variable
black + ## Control variable - If race is black = 1, otherwise = 0
south66 ## Control variable - If living in the south = 1, otherwise = 0
| ## Separate first and second stage
.-educ + ## we include all variable of the first stage, minus the education variable that is estimated
nearc4, ## The instrumental variable is included only here, in the first stage
data = card ) ## Set the dataset
stargazer( simple.model, ivreg.model,
column.labels = c("No IV model", "IV model"),
type="html",
omit.stat = c("rsq","ser"),
digits=2 )| Dependent variable: | ||
| lwage | ||
| OLS | instrumental | |
| variable | ||
| No IV model | IV model | |
| (1) | (2) | |
| educ | 0.08*** | 0.16*** |
| (0.004) | (0.06) | |
| smsa66 | 0.11*** | 0.08*** |
| (0.02) | (0.03) | |
| exper | 0.09*** | 0.12*** |
| (0.01) | (0.02) | |
| expersq | -0.002*** | -0.002*** |
| (0.0003) | (0.0003) | |
| black | -0.18*** | -0.10* |
| (0.02) | (0.05) | |
| south66 | -0.10*** | -0.06** |
| (0.02) | (0.03) | |
| Constant | 4.73*** | 3.36*** |
| (0.07) | (0.94) | |
| Observations | 3,010 | 3,010 |
| Adjusted R2 | 0.27 | 0.14 |
| F Statistic | 184.61*** (df = 6; 3003) | |
| Note: | p<0.1; p<0.05; p<0.01 | |
4.2 Additional examples
Several studies have used instrumental variables to solve omitted variable issues. Here are some examples:
| Outcome variable | Policy variable | Omitted variable | Instrumental variable |
|---|---|---|---|
| Health | Smoking cigarettes | Other negative health behaviors | Tobacco taxes |
| Crime rate | Patrol hours | # of criminals | Election cycles |
| Income | Education | Ability | Father’s education |
| Distance to college | |||
| Military draft | |||
| Crime | Incarceration rate | Simultaneous causality | Overcrowding litigations |
| Election outcomes | Federal spending in a district | Political vulnerability | Federal spending in the rest of the state |
| Conflicts | Economic growth | Simultaneous causality | Rainfall |