Fixed effects
Packages
Here are the packages we will use in this lecture. If you don’t remember how to install them, you can have a look at the code.
- stargazer for nice tables
- car and gplots for graphs
- plm for fixed effect model
install.packages( stargazer )
library( "stargazer" )
install.packages( car )
library( "car" )
install.packages( gplots )
library( "gplots" )
install.packages( plm )
library( "plm" )What you will learn
- What is the scope of fixed effects?
- Which data structure do you need to run a fixed effect model?
- What is the difference between an OLS, fixed, and random effect model?
- How do you interpret the effect of X on Y in a fixed effect model? And in a random effect model?
- Apply a fixed effect model to data in R
- Compare a fixed effect model vs an OLS vs a random model
1 The key concept
We will start with a very simple example to illustrate the idea of within and between variation, which is key to fixed effect models.
Let’s imagine to have data about three different countries. We want to understand the relationship between international aid funding received by the country (policy variable) and economic growth (outcome variable).
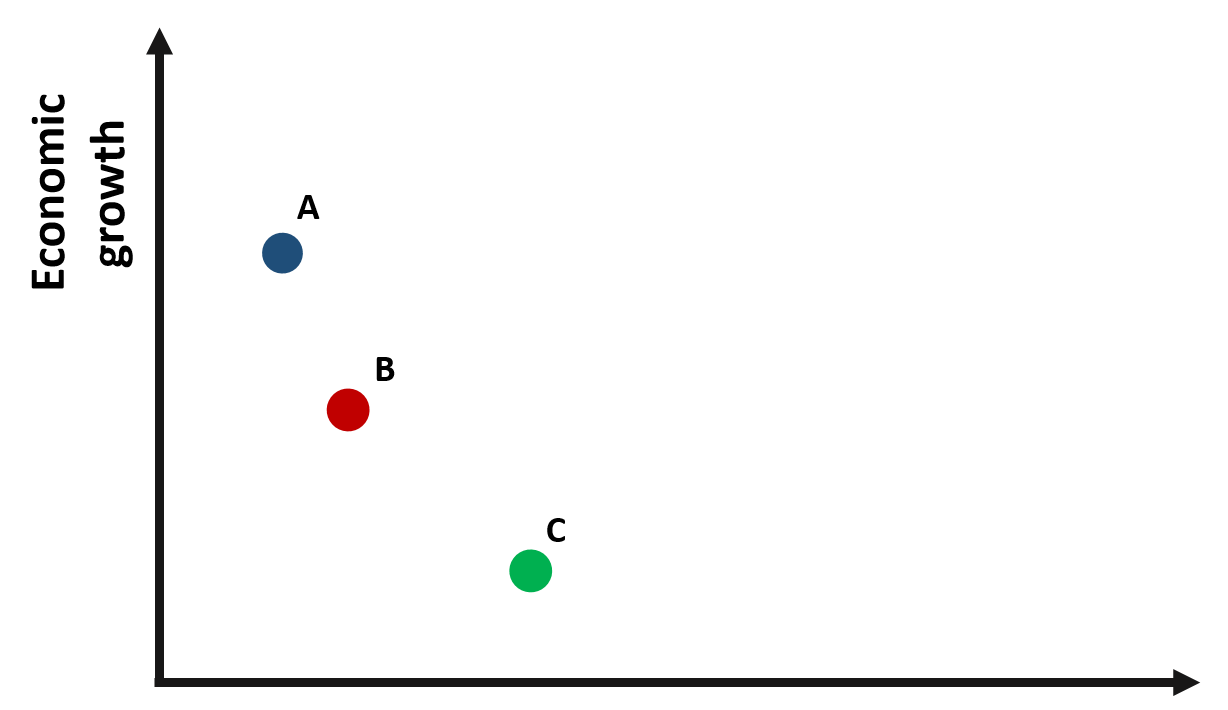
Figure 1.1: Relationship between economic growth and international aid
Based on the graph, we would expect a negative relationship between x and y: countries receiving greater international aid report a lower growth. For instance, country C receives more funding than country B but its growth it’s less than half of country B.
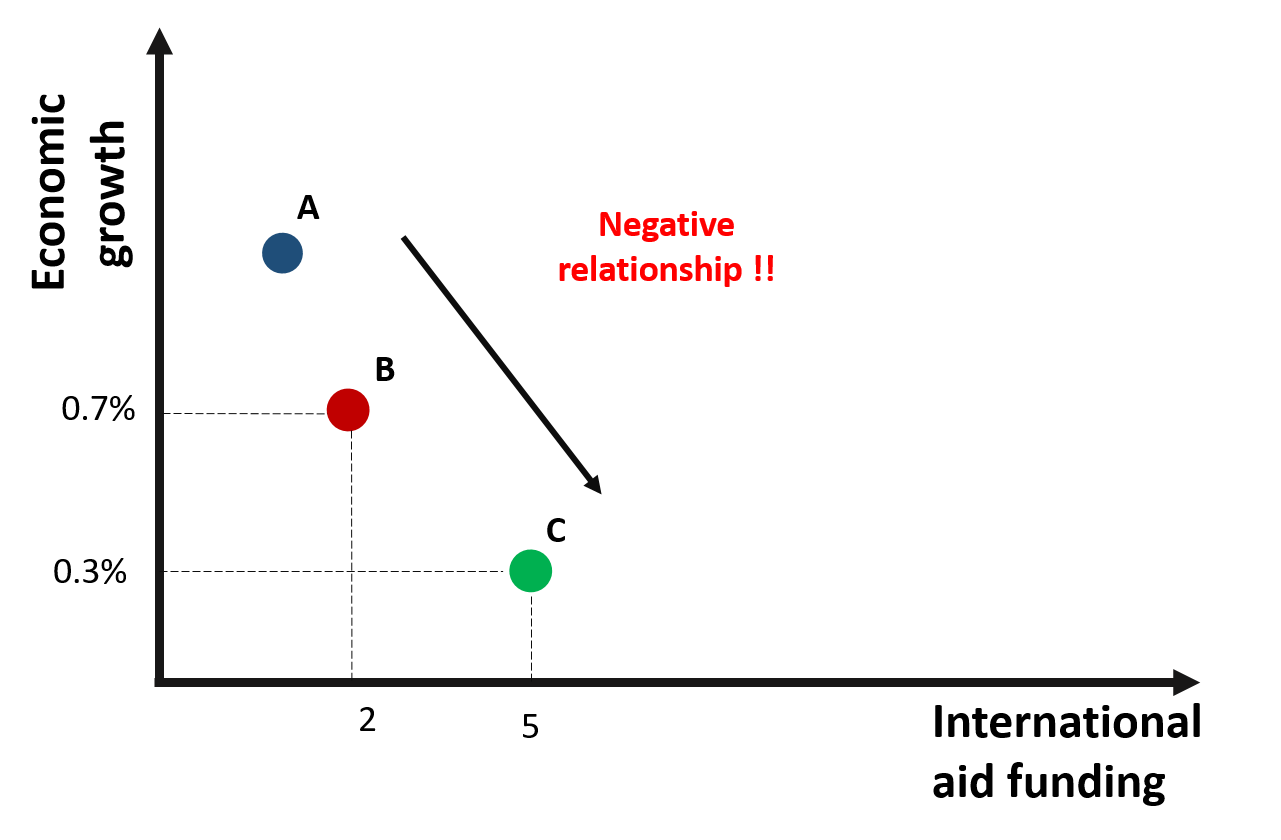
Figure 1.2: A negative relationship between growth and international aid?
Are we supposed to conclude that international aid has a negative effect on growth?
A way to confirm this result is to collect data about each country over an extended period of time. In this way, we move from cross-sectional data to panel data, where each variable in the datset is observed along a given time period.
The small “t” next to each observation indicates the time at which data were collected.
The graph 1.3 represents observations from three countries across three time periods.
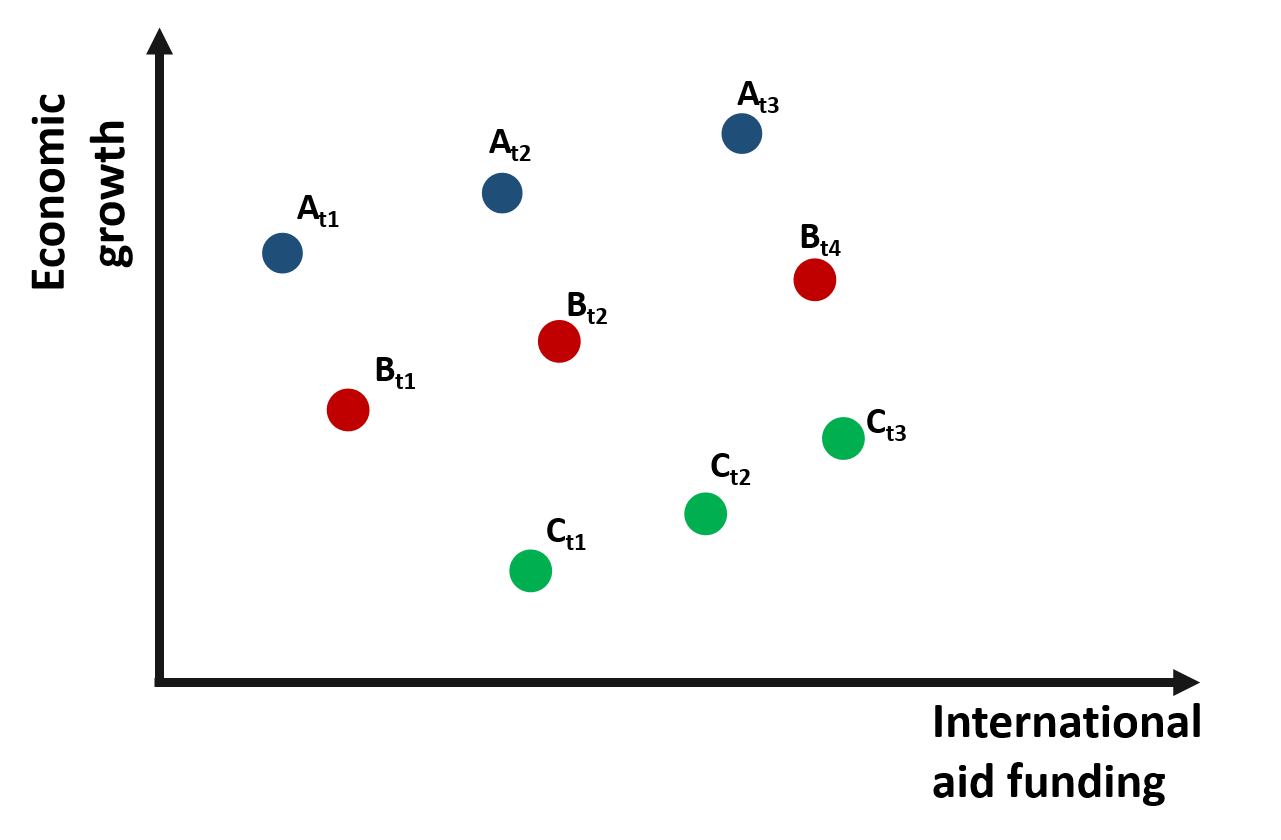
Figure 1.3: Relationship between growth and international aid: panel data
If we consider the relationship between international aid and growth within each time period and across the 3 countries, the relationship is once again negative.
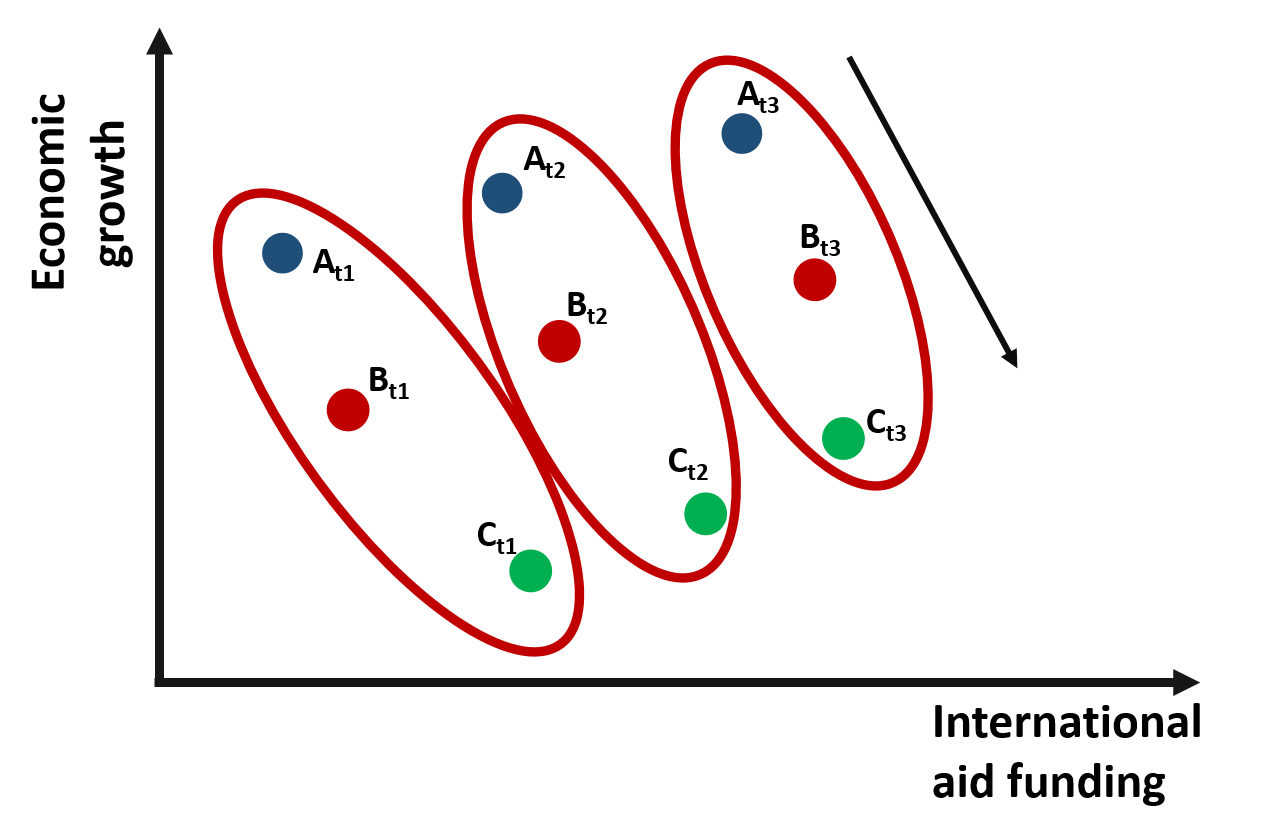
Figure 1.4: Relationship between growth and international aid: Across countries variation
However, if we change the way we look at the data and consider the relationship between international aid and growth within one single country and across time, we would observe a positive relationship.
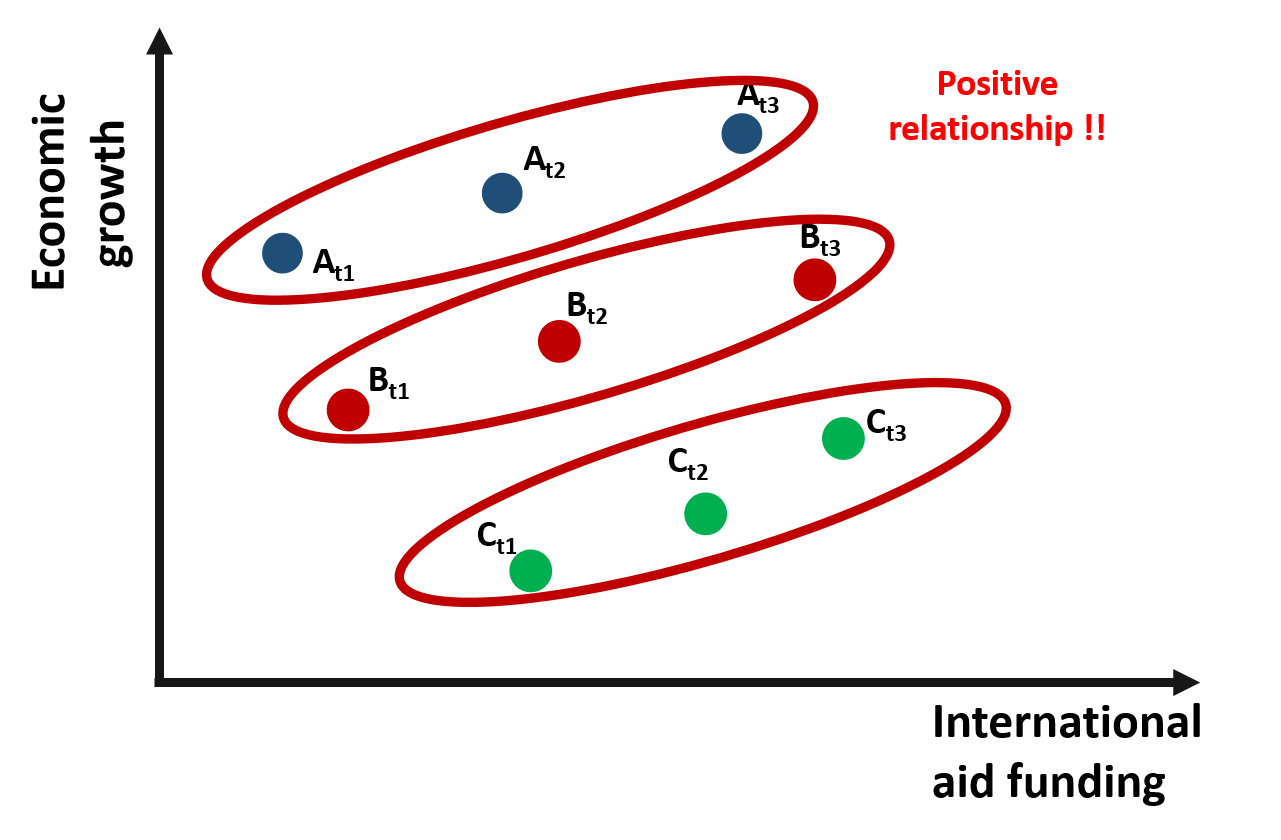
Figure 1.5: Relationship between growth and international aid: Within countries variation
Why does the relationship change so much?
One possible explanation is that country C is poorer and, because of that, it receives more funding than the other countries. However, when we compare country C against other countries, its growth is still limited. As results, across countries variation is negative. The trend is positive only if we compare growth over time within each country. As country C receives more funding, its economic growth improves.
This statistical phenomenon is known as the Simpson’s Paradox, where trends are different depeding on whether data are observed by groups or at the aggregate level (you can read more about the Simpson’s paradox here and here).
As we will see in the remain of the lecture, fixed effect wil enable us to consider differences across groups so that we can estimated the within effect of the policy intervention.
1.1 OLS, demeaning, and fixed effects.
We will continue our example and look at some numbers to better understand differences between OLS and fixed effects.
Let’s take a look at a simulated dataset that replicates the example illustrated in figure 1.3. We plot the observations on a graph. We have three countries (A, B, C) and we observe the relationship between international aid and economic growth at three points in time.
palette( c( "steelblue", "darkred", "darkgreen" ) )
plot(x, y, ylim = c(-8,10), xlim = c(0,8), lwd = 5, col = as.factor(data$g), ylab = "Economic growth (%)", xlab = "International aid ($M)")
text(data$x[1], data$y[1]+1, "A t1")
text(data$x[2], data$y[2]+1, "A t2")
text(data$x[3], data$y[3]+1, "A t3")
text(data$x[4], data$y[4]+1, "B t1")
text(data$x[5], data$y[5]+1, "B t2")
text(data$x[6], data$y[6]+1, "B t3")
text(data$x[7], data$y[7]+1, "C t1")
text(data$x[8], data$y[8]+1, "C t2")
text(data$x[9], data$y[9]+1, "C t3")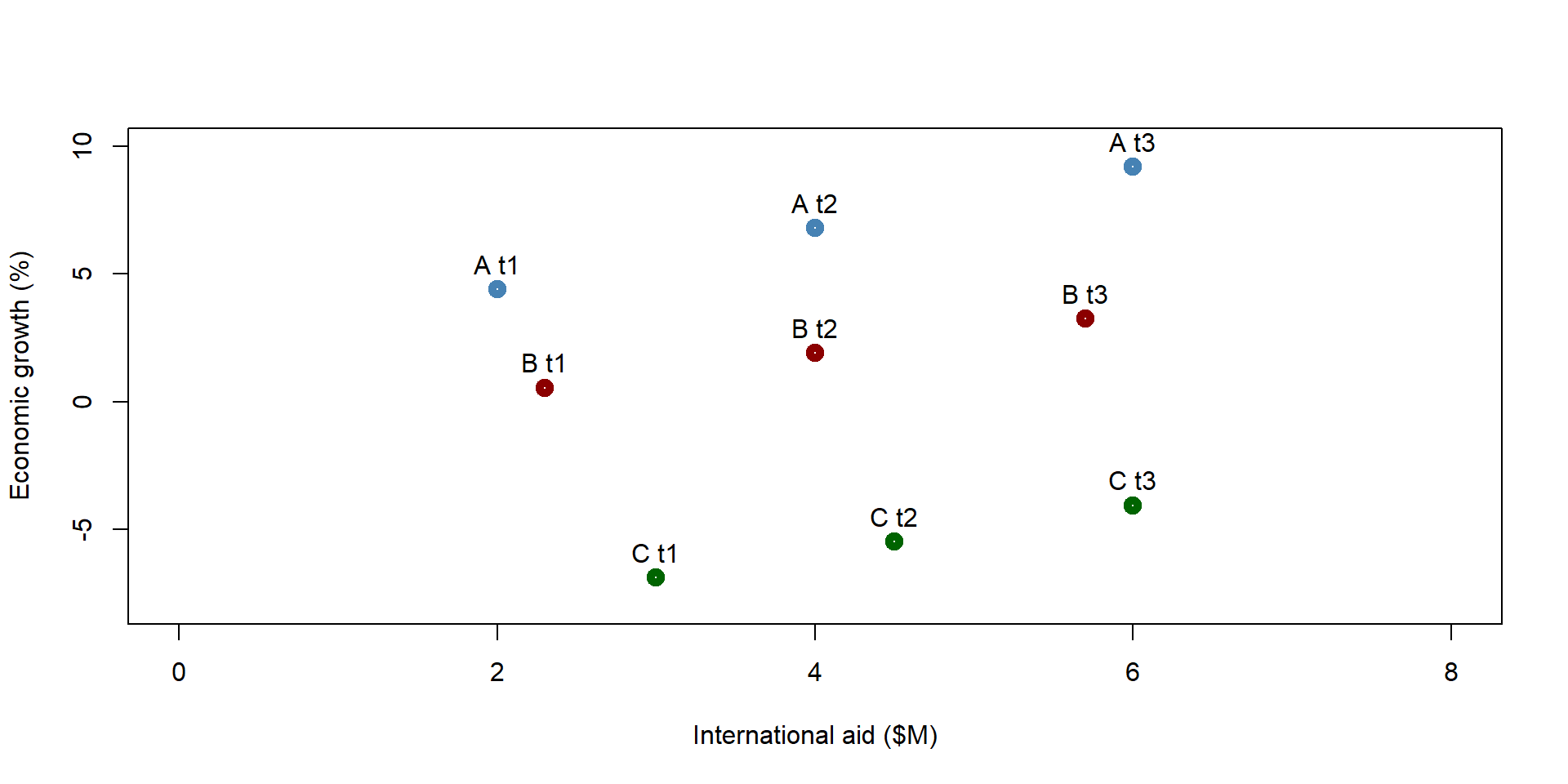
Figure 1.6: Simulated dataset: Economic growth and international aid
1.1.1 OLS model
First, we estimate the relationship between x and y considering only one year of data (cross-sectional dataset as in figure 1.2). We can use an OLS model.
The OLS results show that the coefficient of International Aid is significantly and negatively correlated with Economic Growth. It suggests that for each additional milion received in international aid funding, economic growth decreases by 11%.
palette( c( "steelblue", "darkred", "darkgreen" ) )
plot(x[data$t ==1], y[data$t==1], ylim = c(-8,10), xlim = c(0,8), col = as.factor(data$g), lwd = 5, ylab = "Economic growth (%)", xlab = "International aid ($M)")
abline(y[data$t == 1] ~ x[data$t == 1], col = "red")
text(data$x[1], data$y[1]+1, "A t1")
text(data$x[4], data$y[4]+1, "B t1")
text(data$x[7], data$y[7]+1, "C t1")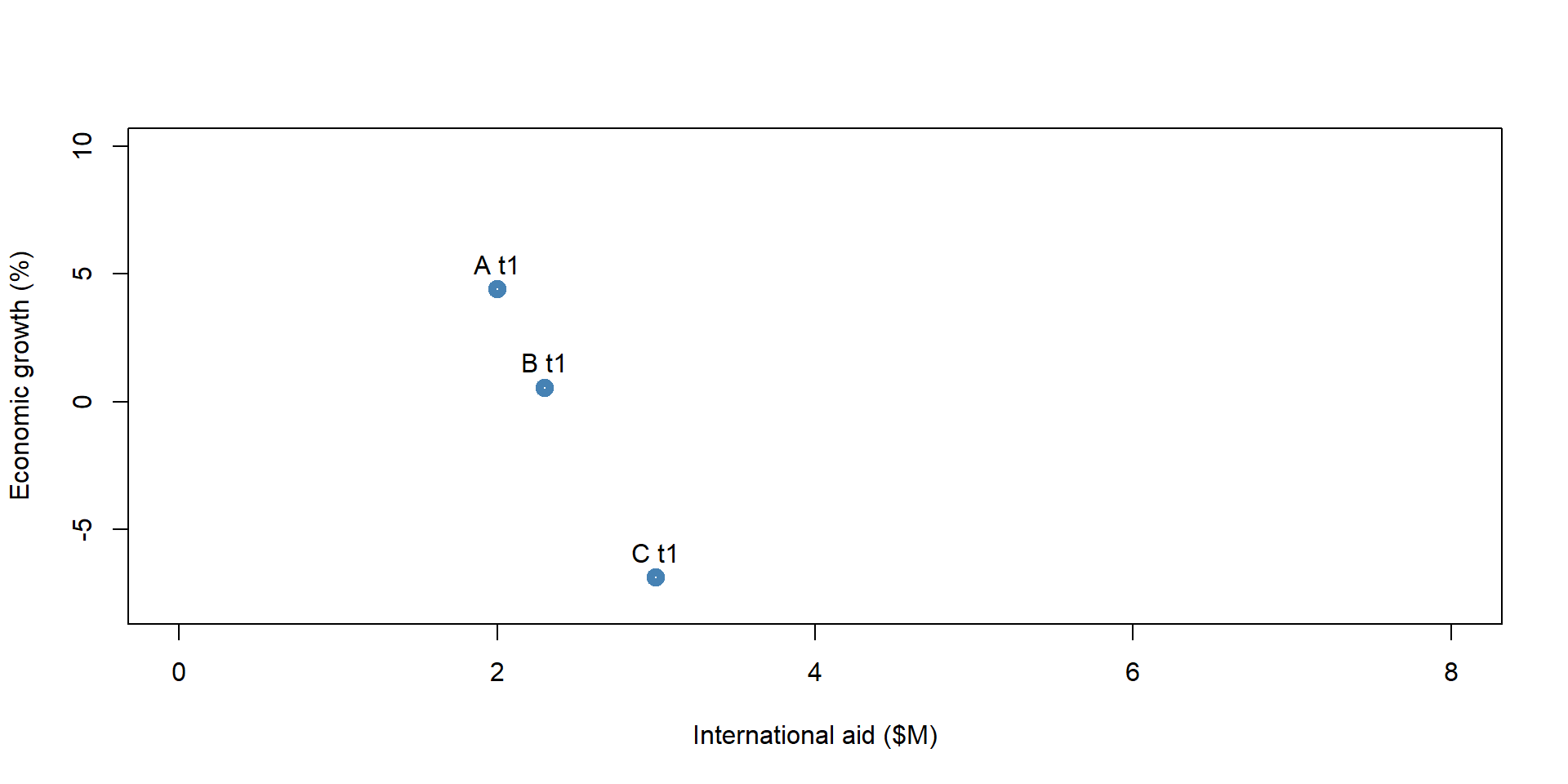
Figure 1.7: Simulated dataset: Year = 1
OLS = lm ( y[data$t == 1] ~ x[data$t == 1] )
stargazer( OLS,
type = "html",
dep.var.labels = ("Economic growth (T1)"),
column.labels = c("Cross-Sectional OLS"),
covariate.labels = c("Intercept", "International aid - Year 1"),
omit.stat = "all",
digits = 2, intercept.bottom = FALSE )| Dependent variable: | |
| Economic growth (T1) | |
| Cross-Sectional OLS | |
| Intercept | 26.60** |
| (1.26) | |
| International aid - Year 1 | -11.20** |
| (0.51) | |
| Note: | p<0.1; p<0.05; p<0.01 |
1.1.2 Pooled OLS model
Since we have data across multiple years, we can also use a pooled OLS regression, where we use all observations across years to predict Economic Growth (as in figure 1.3).
We compare results across a cross-sectional OLS and a pooled OLS model. The pooled OLS regression indicates that international aid has no effect on economic growth; the beta coefficient is not significantly different from zero.
Results are substantially different between the cross-sectional and the pooled OLS model.
palette( c( "steelblue", "darkred", "darkgreen" ) )
plot(x, y, ylim = c(-8,10), xlim = c(0,8), lwd = 5, col = as.factor(data$g), ylab = "Economic growth (%)", xlab = "International aid ($M)")
text(data$x[1], data$y[1]+1, "A t1")
text(data$x[2], data$y[2]+1, "A t2")
text(data$x[3], data$y[3]+1, "A t3")
text(data$x[4], data$y[4]+1, "B t1")
text(data$x[5], data$y[5]+1, "B t2")
text(data$x[6], data$y[6]+1, "B t3")
text(data$x[7], data$y[7]+1, "C t1")
text(data$x[8], data$y[8]+1, "C t2")
text(data$x[9], data$y[9]+1, "C t3")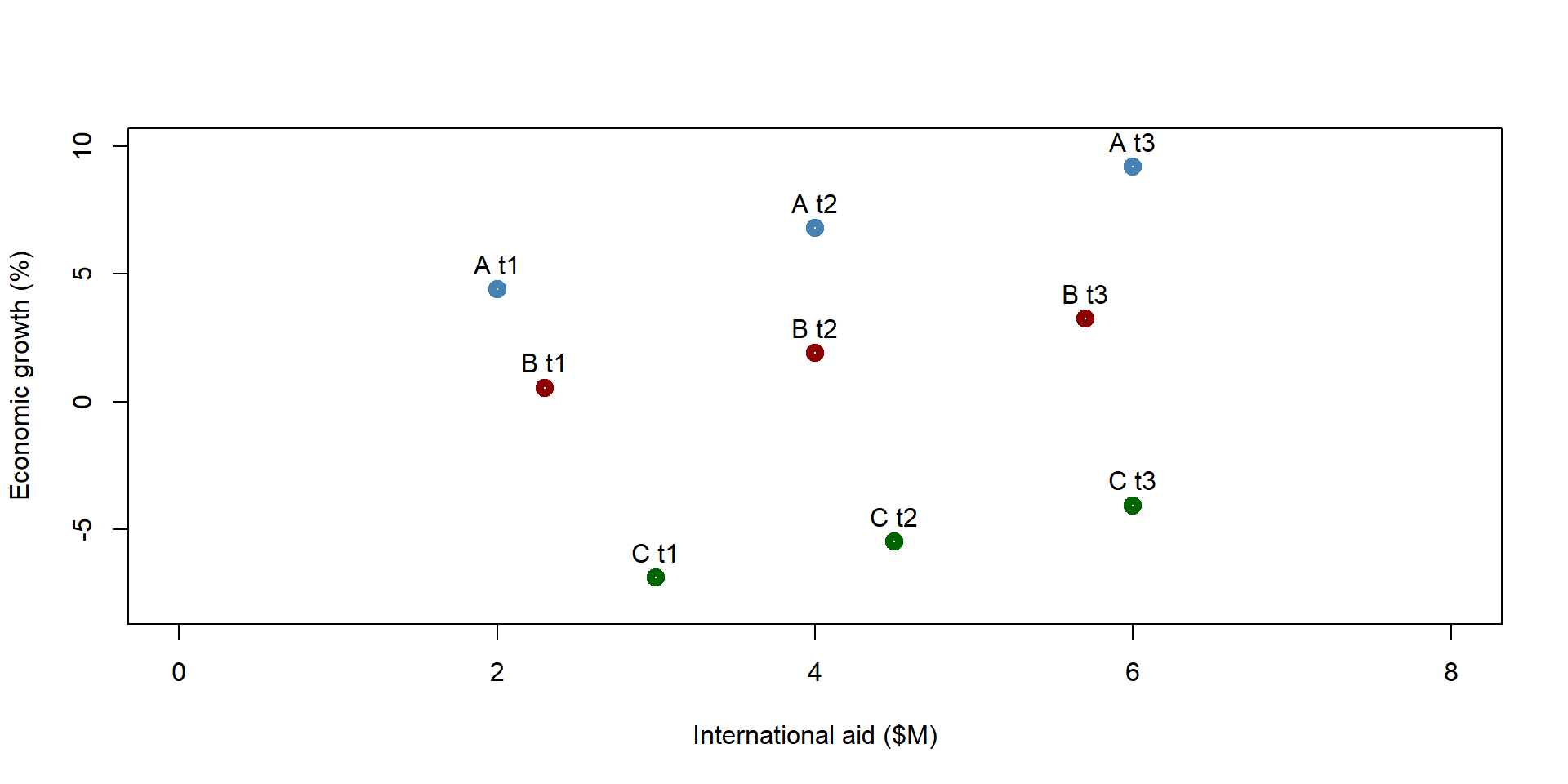
Figure 1.8: Simulated dataset: All observations
Pooled_OLS = lm ( y ~ x )
stargazer( OLS, Pooled_OLS,
type = "html",
dep.var.labels = ("Economic growth"),
column.labels = c("Cross-Sectional OLS", "Pooled OLS"),
covariate.labels = c("Intercept", "International aid - Year 1", "International aid"),
omit.stat = "all",
digits = 2, intercept.bottom = FALSE )| Dependent variable: | ||
| Economic growth | y | |
| Cross-Sectional OLS | Pooled OLS | |
| (1) | (2) | |
| Intercept | 26.60** | -0.85 |
| (1.26) | (6.02) | |
| International aid - Year 1 | -11.20** | |
| (0.51) | ||
| International aid | 0.46 | |
| (1.37) | ||
| Note: | p<0.1; p<0.05; p<0.01 | |
1.1.3 De-meaned OLS model
As we discussed before, OLS can be problematic with panel data because it takes into account across-country variation. The effect of international aid on growth is negative because the overall trend across countries is negative. Countries which receive more funding (like Country C) report a lower economic growth. To observe the true effect of international aid, we need to remove the across-country variation. We can do it by demeaning the data.
De-meaning requires you to substract the mean from each variable. In this case, we are interested in demeaning by group, so that the values of x and y are centered around each group mean. You can observe the process in table 1.5.
By demeaning the data, we remove across-country variation: the mean of each country across years is now equal to 0.
The mean value of Economic Growth in group A is 4. We substract 4 from each value of Economic Growth within group A (2, 4, 6) and obtain -2, 0, and 2. We repeat the same process for each group, and for both Economic Growth (x) and International Aid (note: you need to demean all the variables in your model, including control variables).
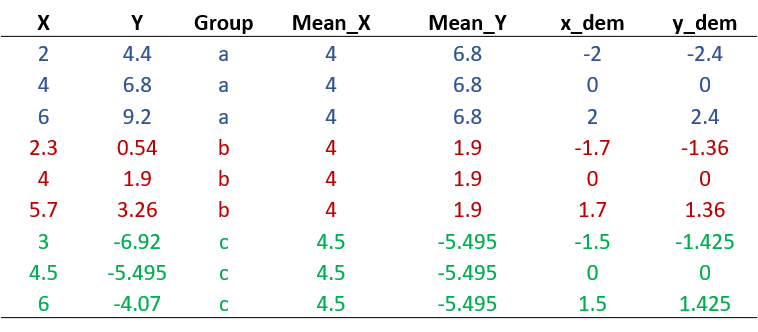
Figure 1.9: Relationship between growth and international aid: Within countries variation
data$x_dem = ifelse(
data$g == "a", data$x - mean(data$x[data$g == "a"]),
ifelse(data$g == "b", data$x - mean(data$x[data$g == "b"]),
ifelse(data$g == "c", data$x - mean(data$x[data$g == "c"]),NA)))
data$y_dem = ifelse(
data$g == "a", data$y - mean(data$y[data$g == "a"]),
ifelse(data$g == "b", data$y - mean(data$y[data$g == "b"]),
ifelse(data$g == "c", data$y - mean(data$y[data$g == "c"]),NA)))As a result, we obtain a new dataset where our observations are disposed along a line. In graph 1.10, there are no longer significant differences across the 3 countries - they all lay on the same line. We observe only within countries differences.
palette( c( "steelblue", "darkred", "darkgreen" ) )
plot(data$x_dem, data$y_dem, ylim = c(-5,5), xlim = c(-3,3), lwd = 5, col = as.factor(data$g), ylab = "Economic growth (%)", xlab = "International aid ($M)")
points(2, -4, col = "steelblue", lwd = 5 )
points(2, -4.5, col = "darkred", lwd = 5 )
points(2, -5, col = "darkgreen", lwd = 5 )
text(2.4, -4, "A", col = "steelblue")
text(2.4, -4.5, "B", col = "darkred")
text(2.4, -5, "C", col = "darkgreen")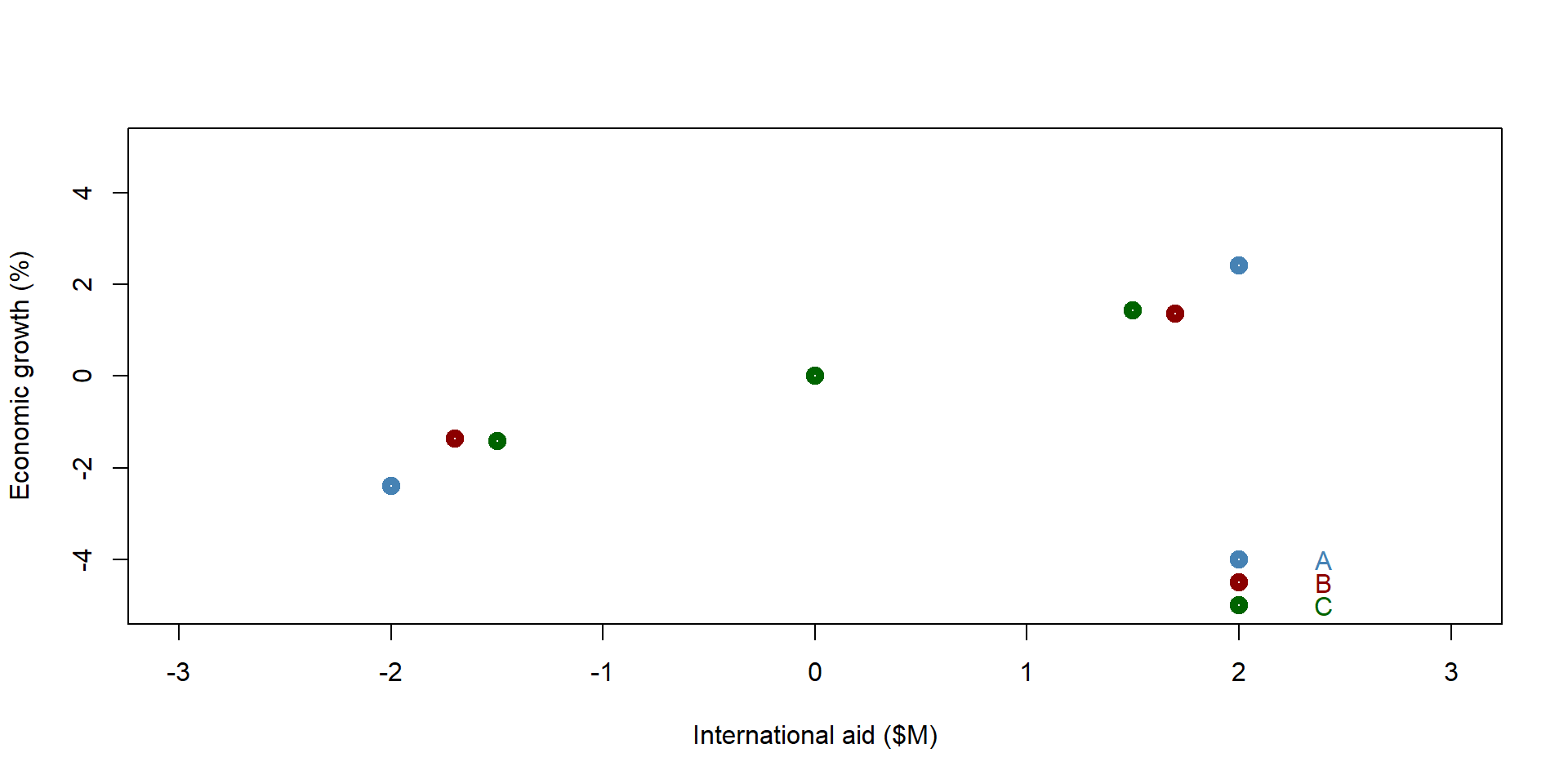
Figure 1.10: Simulated dataset: De-meaned observations
At this point, we can estimate the relationship between x and y using an OLS model. Our beta coefficient is positive and statistically significant. For each milion dollar received in funding aid, a country’s economic growth increases - on average - of 1.01 points percentage.
Note that we do not know whether a country grows more than another. We are estimating an average within country effect.
Demean_OLS = lm ( y_dem ~ x_dem, data = data )
stargazer( OLS, Pooled_OLS, Demean_OLS,
type = "html",
dep.var.labels = c("Economic growth", "Economic growth", "Economic growth (de-meaned)"),
column.labels = c("Cross-Sectional OLS", "Pooled OLS", "De-meaned OLS"),
covariate.labels = c("Constant", "International aid - Year 1", "International aid", "International aid - De-meaned OLS"),
omit.stat = "all",
digits = 2, intercept.bottom = FALSE )| Dependent variable: | |||
| Economic growth | Economic growth | Economic growth (de-meaned) | |
| Cross-Sectional OLS | Pooled OLS | De-meaned OLS | |
| (1) | (2) | (3) | |
| Constant | 26.60** | -0.85 | 0.00 |
| (1.26) | (6.02) | (0.09) | |
| International aid - Year 1 | -11.20** | ||
| (0.51) | |||
| International aid | 0.46 | ||
| (1.37) | |||
| International aid - De-meaned OLS | 1.01*** | ||
| (0.07) | |||
| Note: | p<0.1; p<0.05; p<0.01 | ||
1.1.4 Fixed-effect model
The demeaning procedure shows what happens when we use a fixed effect model.
A fixed effect model is an OLS model including a set of dummy variables for each group in your dataset. In our case, we need to include 3 dummy variable - one for each country. The model automatically excludes one to avoid multicollinearity problems.
Results for our policy variable in the fixed effect model are identical to the de-meaned OLS. The international aid coefficient represents a one-unit change in the economic growth, on average, within a country for each additional one-milion dollar received.
The fixed effect model also includes different intercepts for each country. The intercept for country A is represented by the constant. It represents the average economic growth when international aid is equal to 0. Country B intercept is 4.90 points percentage lower than Country A. Country C intercept is 12.8 points percentage lower than Country A. The coefficient of Country B and Country C indicate how much a country is different, on average, from country A (the reference category).
fixed_reg = lm ( y ~ x + as.factor(g), data = data)
stargazer( OLS, Pooled_OLS, Demean_OLS, fixed_reg,
type = "html",
dep.var.labels = c("Economic growth", "Economic growth", "Economic growth (de-meaned)"),
column.labels = c("Cross-Sectional OLS", "Pooled OLS", "De-mean OLS", "Fixed effect"),
covariate.labels = c("Constant", "International aid - Year 1", "International aid", "International aid - De-meaned OLS", "Country B", "Country C"),
omit.stat = "all",
digits = 2, intercept.bottom = FALSE )| Dependent variable: | ||||
| Economic growth | Economic growth | Economic growth (de-meaned) | y | |
| Cross-Sectional OLS | Pooled OLS | De-mean OLS | Fixed effect | |
| (1) | (2) | (3) | (4) | |
| Constant | 26.60** | -0.85 | 0.00 | 2.75*** |
| (1.26) | (6.02) | (0.09) | (0.37) | |
| International aid - Year 1 | -11.20** | |||
| (0.51) | ||||
| International aid | 0.46 | 1.01*** | ||
| (1.37) | (0.08) | |||
| International aid - De-meaned OLS | 1.01*** | |||
| (0.07) | ||||
| Country B | -4.90*** | |||
| (0.27) | ||||
| Country C | -12.80*** | |||
| (0.28) | ||||
| Note: | p<0.1; p<0.05; p<0.01 | |||
1.2 The statistical model
To summarize key conclusions from our previous example:
- We are looking panel data, where we have multiple observations over time for different entity - e.g., countries’ economic growth over time.
The dataset below is an example of a panel dataset. It contains 35 observations. Data are grouped into 7 groups and for each group we have 5 years of observation.
head(data[13:16], 10)## X Outcome G Y
## 1 35925.98 97251.81 1 2010
## 2 39491.79 113394.41 1 2011
## 3 30982.23 83029.76 1 2012
## 4 23601.33 77980.51 1 2013
## 5 23717.48 79985.21 1 2014
## 6 49275.48 150318.89 2 2010
## 7 52329.12 153086.73 2 2011
## 8 24152.64 126582.74 2 2012
## 9 20997.74 111552.96 2 2013
## 10 16147.12 102579.59 2 2014- We are interested in investigating the effect of a policy variable X on a given outcome. But because groups are different across each others (between variation), an OLS model (either a cross-sectional or a pooled model) does not approximate our data very well.
For instance, we can plot the relationship between x and y in our dataset in graph 1.11. The line represent a basic regression where X predicts Y.
plot( data$X, data$Outcome,
col=gray(0.5,0.5),
pch=19, cex=3, bty="n",
xlab="X - Policy variable", ylab="Y - Outcome" )
abline( lm( Outcome ~ X, data=data ), col="red", lwd=2 )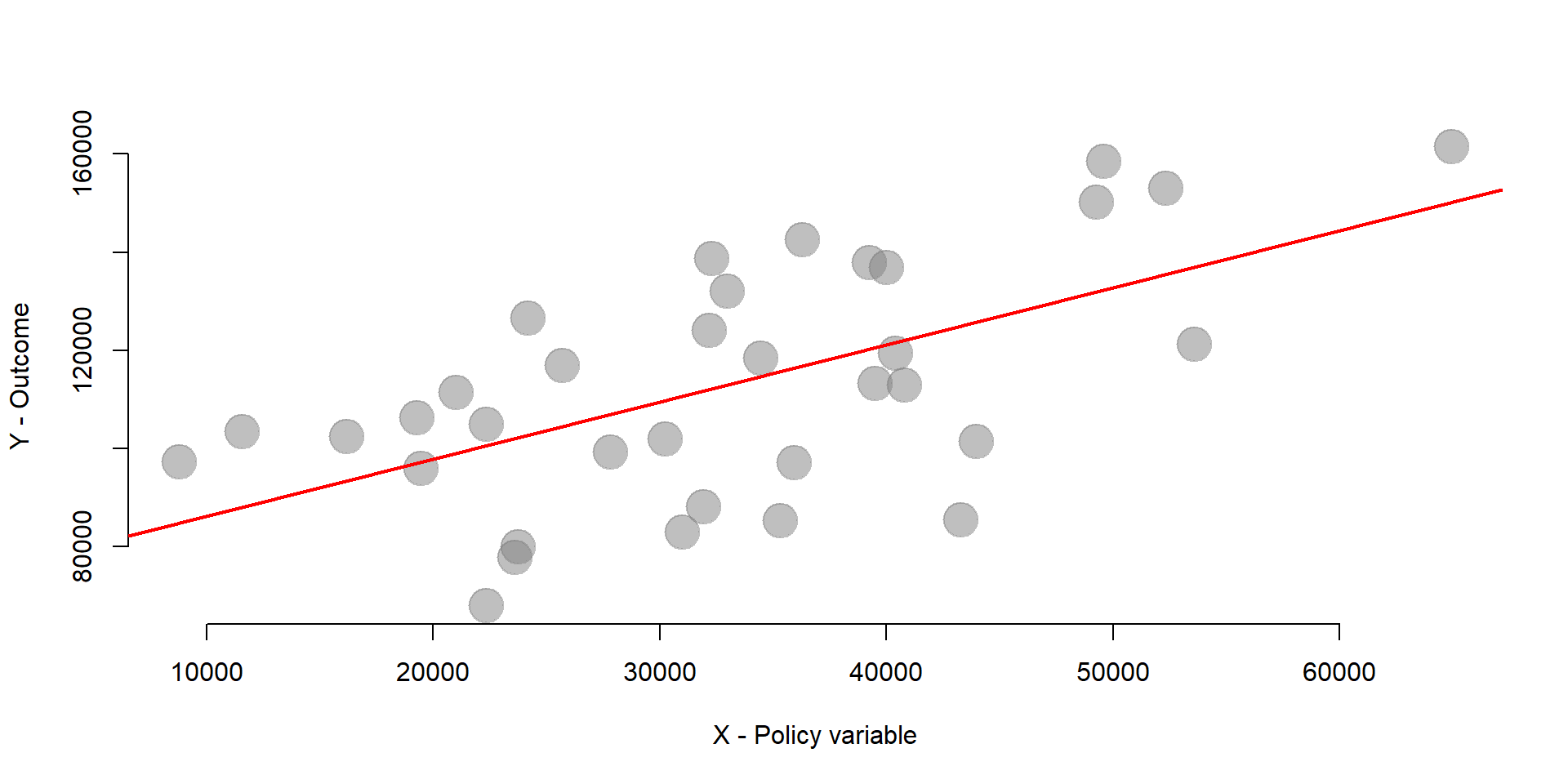
Figure 1.11: Relationship between X and Y
- Because we know that data are grouped into 7 different groups we can use fixed effets to control for between variation and estimate the average within groups effect of x on y.
In other words, we would like to obtain a regression line for each group in our dataset, as one unique regression line is not a good approximation.
palette( c( "steelblue", "darkred", "forestgreen", "goldenrod1", "gray67", "darkorchid4", "seagreen1" )) # Set colors
plot( data$X, data$Outcome,
col=factor(data$G),
pch=19, cex=3, bty="n",
xlab="X - Policy variable", ylab="Outcome" )
abline( lm( Outcome ~ X, data=data ), col="red", lwd=2 )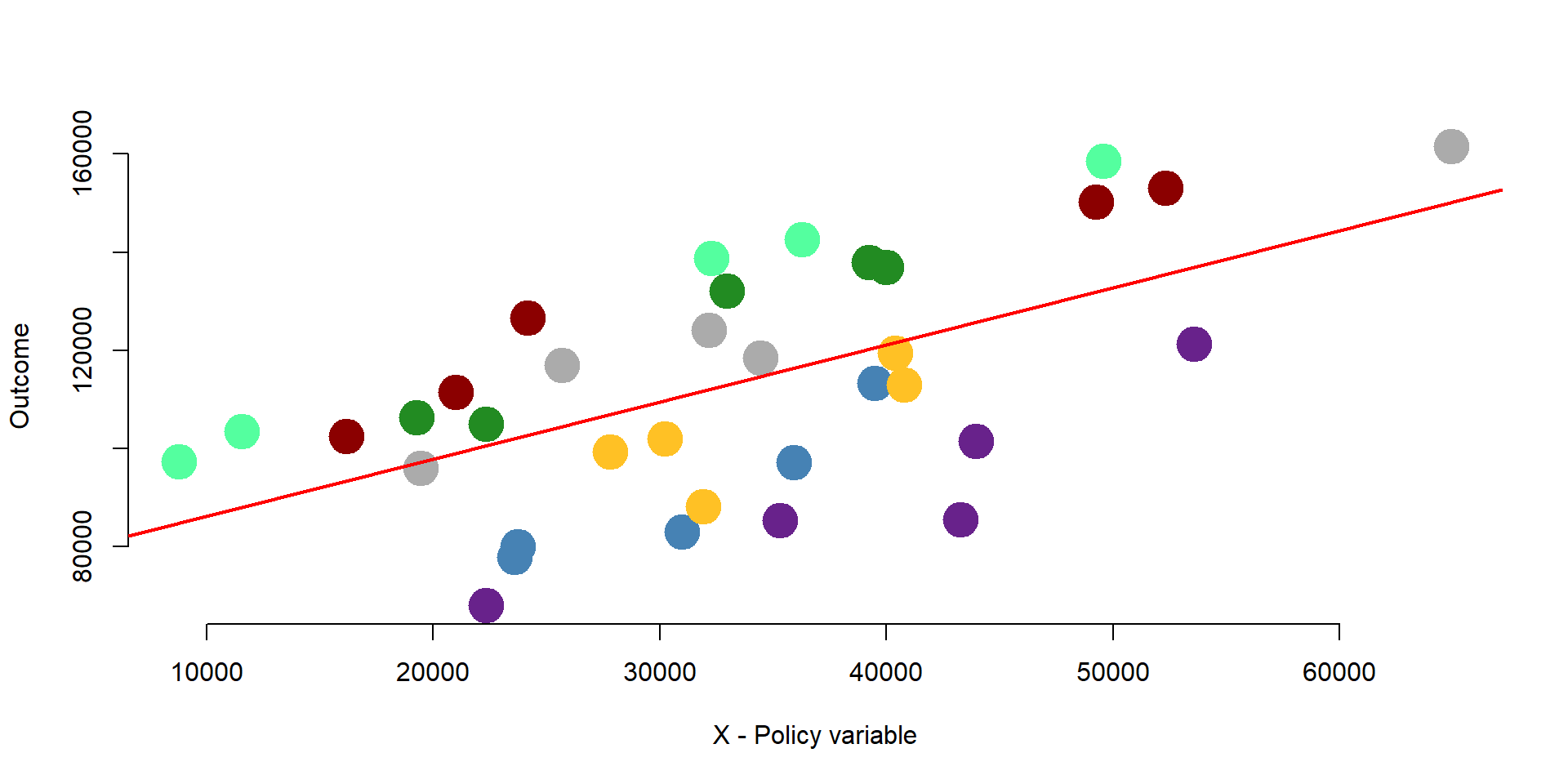
- A fixed effects includes a set of dummy variables each of which represents a group. The equation of a fixed effect model is the following:
\[\begin{equation} \text{Yit} = \beta_1*Xit + \alpha_i + \text{e} \tag{1.1} \end{equation}\]
Where:
\(\text{i}\) indicates the number of groups in the dataset;
\(\text{t}\) indicates the number of time periods in the dataset;
\(\text{Yit}\) is the outcome variable;
\(\beta_1\) is the coefficient of the policy variable; it indicates the average changes in the outcome over time within each group;
\(\alpha_i\) is a set of dummy variable for each entity;
\(\text{e}\) is the error term.
We can estimate the model as follows:
reg = lm( Outcome ~ X + factor(G) - 1, data = data )
stargazer( reg,
type = "html",
dep.var.labels = (" "),
column.labels = c(" "),
covariate.labels = c("Policy variable", "Group 1", "Group 2", "Group 3", "Group 4", "Group 5", "Group 6", "Group 7"),
omit.stat = "all",
digits = 2, intercept.bottom = FALSE )| Dependent variable: | |
| Policy variable | 1.46*** |
| (0.09) | |
| Group 1 | 45,424.04*** |
| (3,855.35) | |
| Group 2 | 81,237.27*** |
| (3,970.97) | |
| Group 3 | 78,774.94*** |
| (3,856.03) | |
| Group 4 | 54,388.96*** |
| (4,077.09) | |
| Group 5 | 71,810.91*** |
| (4,149.83) | |
| Group 6 | 34,387.68*** |
| (4,445.21) | |
| Group 7 | 87,701.40*** |
| (3,670.89) | |
| Note: | p<0.1; p<0.05; p<0.01 |
# We add factor(G) - 1 in our model to add a set of intercepts; one for each group.
fe <- lm( Outcome ~ X + factor(G) - 1, data = data )
yhat <- fe$fittedWe plot our results in graph 1.12. As you can see, the lines have the same slope, but different intercept. The slope is represented by the coefficient of international aid, the policy variable. It represents the average within-group variation across time. The intercepts represent the average of each group when international aid is equal to 0. A fixed effect model better approximates the actual strucutre of the data and controls for group-level characteristics.
Note that the group-level dummy variables control for all time-invariant characteristics of the group. But they do not control for characteristics that change over time.
plot( data$X, yhat, col=factor(data$G),
pch=19, cex=2, xlab="X", ylab="Y", bty="n" )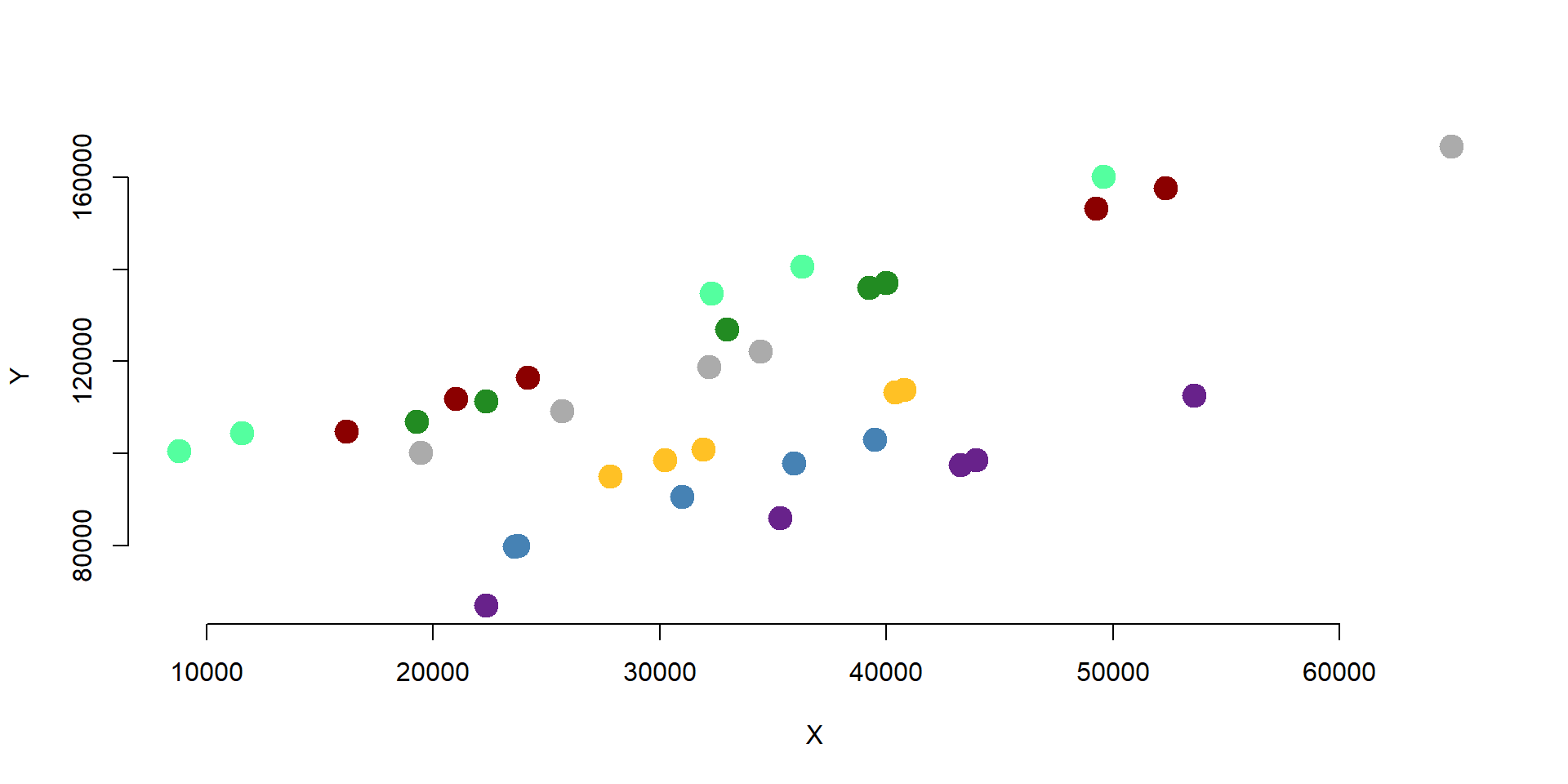
Figure 1.12: Fixed effect model
2 A fixed effect model
](FIGURE/FixEffs/labs.jpg)
Figure 2.1: Source: Wikimedia
{kind=link}
Countries strongly invest in Research & Development (R&D). The United States spend 2.7% of their GDP into research and development. One of the goals of these investments is to provide funding to companies and incentivize private investments. In this example, we want to assess the impact of public expenditure on research and development (R&D) on companies’ investments.
Data are structured in a panel dataset where we have 10 companies and observations over a five-year period. You can see here the structure of the data for Company 1, Company 10, and Company 2.
head(data[,c(1,2,18)],15)## Company Year RDPub
## 1 Company1 2010 36084.68
## 2 Company1 2011 39167.07
## 3 Company1 2012 25470.58
## 4 Company1 2013 38535.33
## 5 Company1 2014 49854.10
## 6 Company10 2010 34432.72
## 7 Company10 2011 47245.19
## 8 Company10 2012 33777.57
## 9 Company10 2013 32980.91
## 10 Company10 2014 18674.63
## 11 Company2 2010 51582.58
## 12 Company2 2011 49657.59
## 13 Company2 2012 21151.75
## 14 Company2 2013 44989.39
## 15 Company2 2014 27469.65Each company has different levels of investment in research and development. We plot each company average R&D investement in graph 2.2. Each bar represents a company. The middle dot is the average R&D investment. The bars go from the minimum level of investment to the maximum.
You can see how Company 1 has a lower average R&D investment than Company 2. Company 5 has a smaller range than the other companies, with a minimum investment that it is higher than the average outcome of company 6 and so on.
There are can be several explanation for these differences: size, different managerial practices, or business culture, among others. Note that this variable changes across organizations but not across time.
plotmeans(RD ~ Company,
xlab = "Companies", ylab = "R&D Investment",
barwidth = 2,
col =
palette( c( "steelblue", "darkred", "forestgreen", "goldenrod1", "gray67", "turquoise4", "tan1" )),
barcol =
palette( c( "steelblue", "darkred", "forestgreen", "goldenrod1", "gray67", "turquoise4", "tan1" )),
data = data)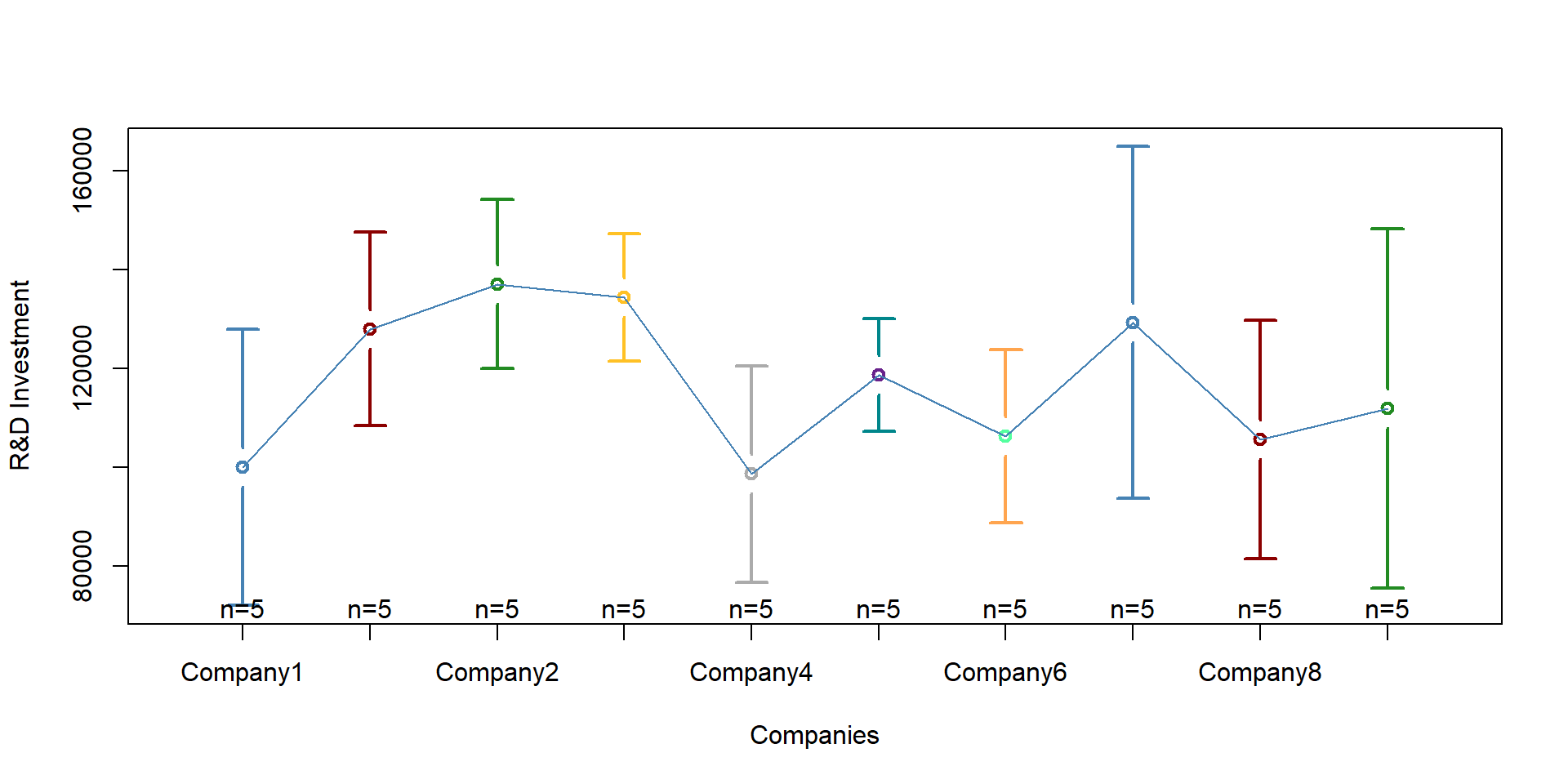
Figure 2.2: Heterogeneity across companies
Variation occurs also across years. We can plot each year in graph 2.3. Year 2014 shows great variability than year 2, for instance.
Variation across years can be explained by new national policies that get implemented, internaional agreeements, taation policies, or the economic situation. Note that these varibles vary across years but not across entities (e.g., national policies affect all companies in the dataset).
plotmeans(RD ~ Year,
main="Heterogeineity across companies",
xlab ="Years, 2010 - 2014", ylab = "R&D Investment",
data = data, barwidth = 2,
col = "gray52",
barcol = "gray52")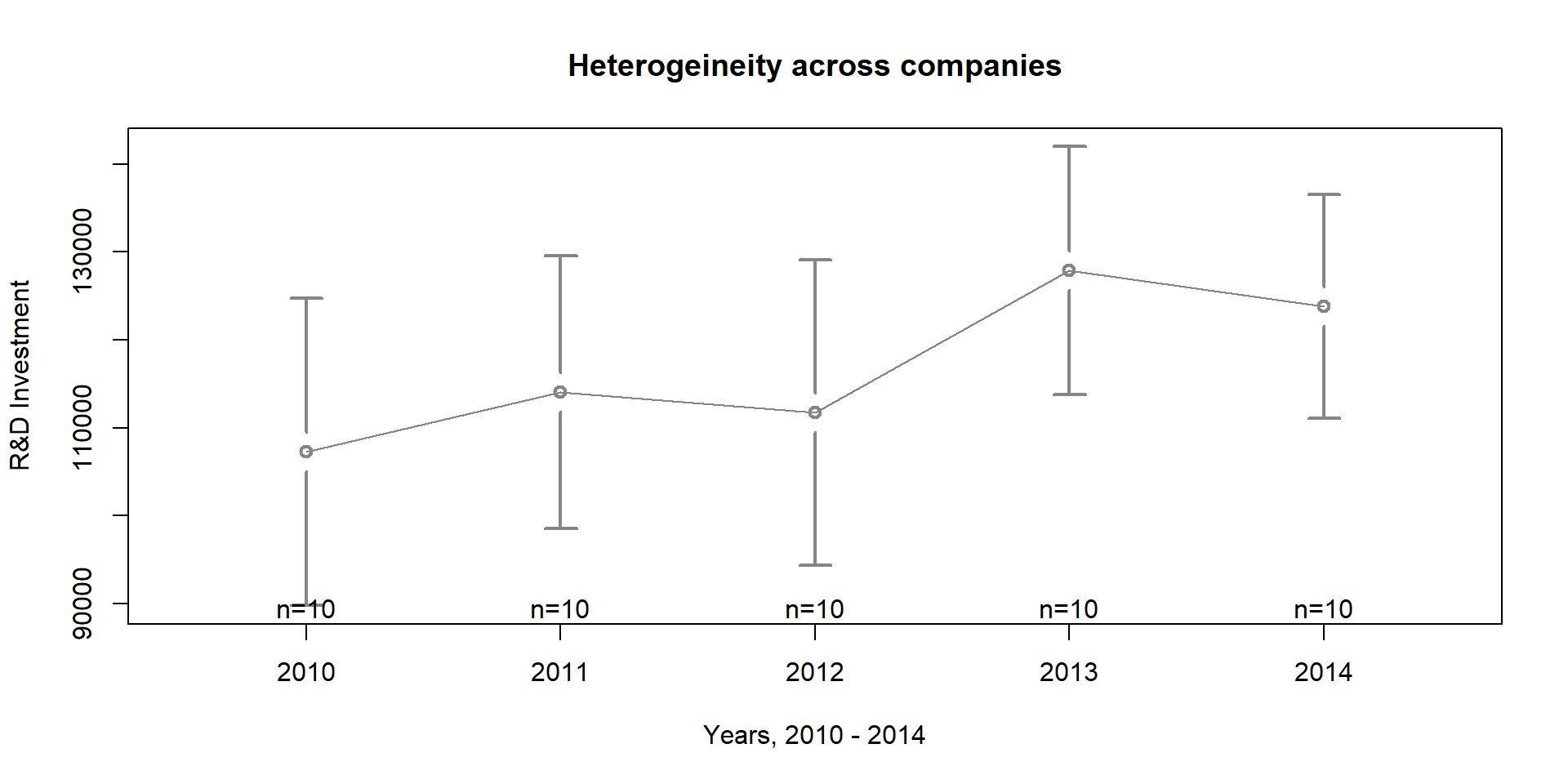
Figure 2.3: Heterogeneity across years
We can look at both company and year variation at the same time in one graph:
palette( c( "steelblue", "darkred", "forestgreen", "goldenrod1", "gray67", "turquoise4", "black"))
coplot(RD ~ as.factor(Year)|as.factor(Company),
xlab = c("Year", "Companies"), ylab = "Company R&D",
col = as.factor(Company), lwd = 2,
type="b", data=data) 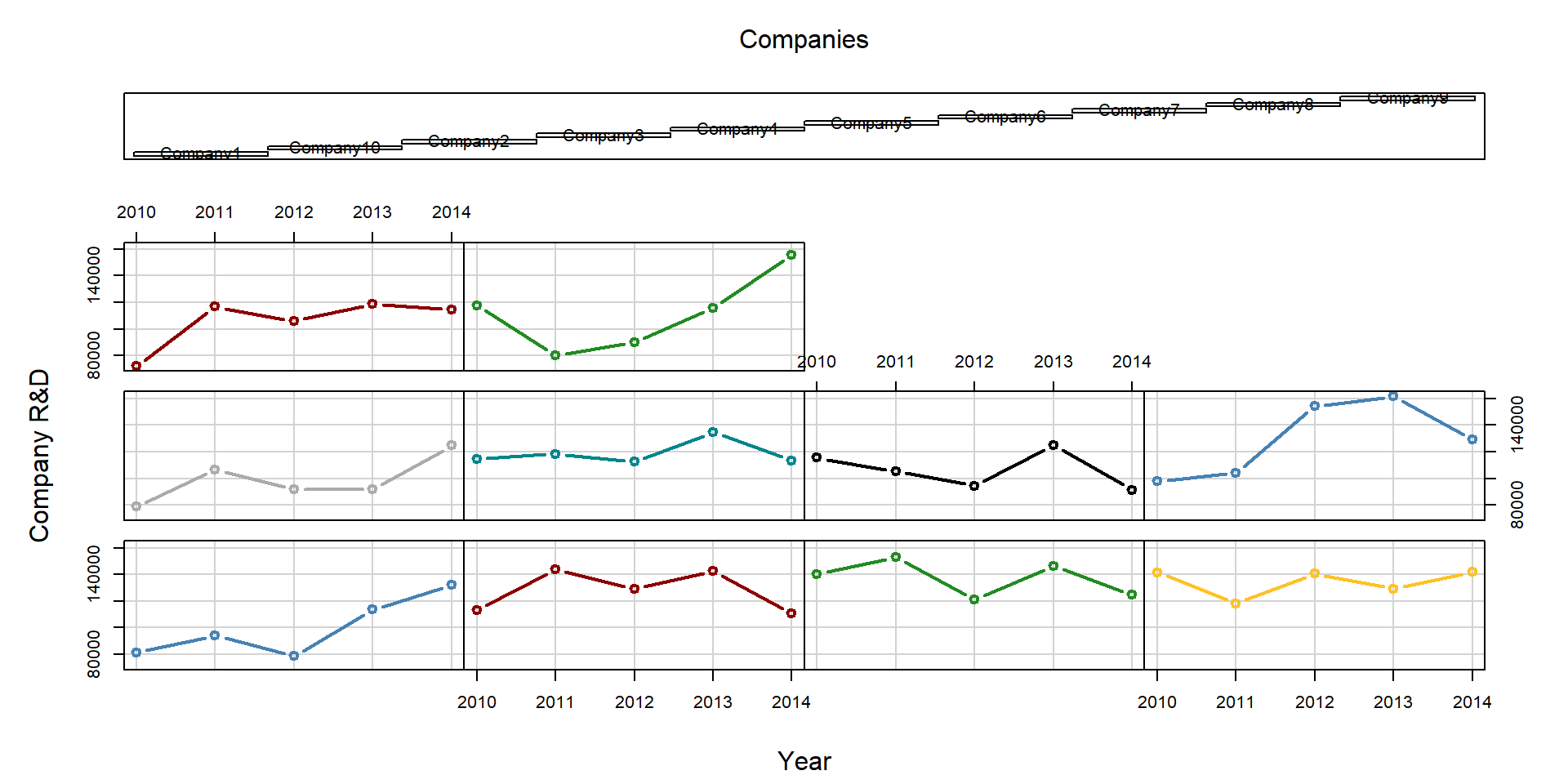
Figure 2.4: Heterogeneity across companies and years
Because of differences across companies, we want to use fixed effects to control for these unobserved characteristics that affect variation across entities (e.g., companies).
2.1 The statistical model
We can start by looking at the results that we would have if we were running the model as an OLS regression.
reg = lm(RD ~ RDPub)
stargazer( reg,
type = "html",
dep.var.labels = ("Company R&D"),
column.labels = c(" "),
covariate.labels = c("Constant", "Public R&D"),
omit.stat = "all",
digits = 2, intercept.bottom = FALSE )| Dependent variable: | |
| Company R&D | |
| Constant | 83,671.23*** |
| (9,276.31) | |
| Public R&D | 0.92*** |
| (0.25) | |
| Note: | p<0.1; p<0.05; p<0.01 |
The effect of public R&D investment on private ones is equal to 1.036, indicating that for each dollar invested by the government, private companies will invest 1.036 dollars.
We can plot our observations and the OLS results on graph 2.5. The black dots represent our observations. The red line represents OLS results.
We can see that the line only approximates the actual observations.
plot(RDPub, RD, pch=19, xlab="Public R&D Investment", ylab="Company R&D Investment")
abline(lm( RD ~ RDPub ),lwd=3, col="darkred")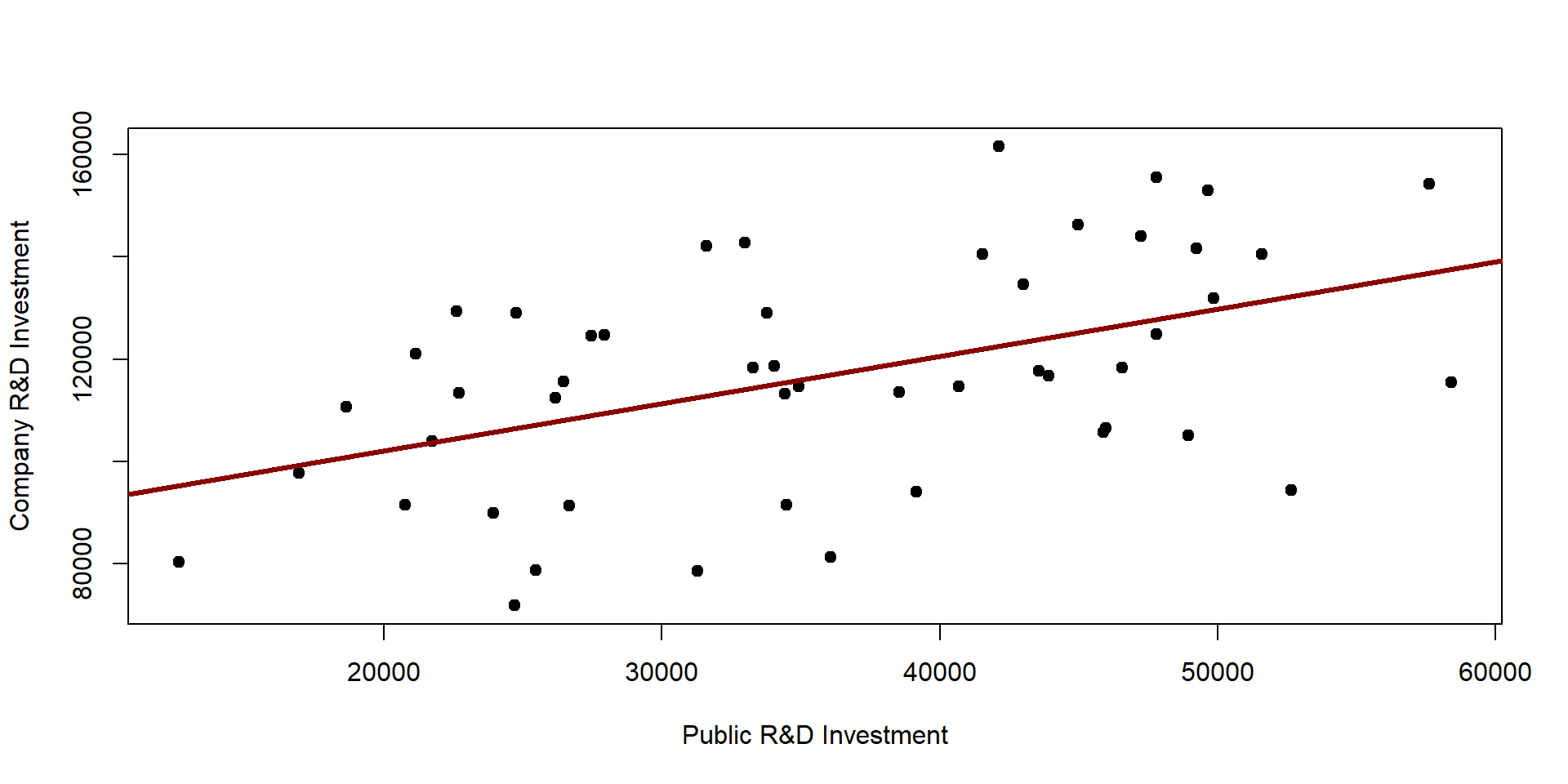
Figure 2.5: OLS results
A way to improve the results is to include a set of dummy variable for each company, so as we can control differences across companies.
Results of our variable of interest (Public R&D) change; now, for each dollar spent by the public, companies spend 0.99.
regDummy = lm ( RD ~ RDPub + as.factor(Company), data = data)
stargazer( regDummy,
type = "html",
dep.var.labels = ("Company R&D"),
column.labels = c(" "),
omit.stat = "all",
covariate.labels = c("Constant (or Company 1)", "Public R&D", "Company 10", "Company 2", "Company 3", "Company 4", "Company 5", "Company 6", "Company 7", "Company 8", "Company 9"),
digits = 2, intercept.bottom = FALSE )| Dependent variable: | |
| Company R&D | |
| Constant (or Company 1) | 56,569.91*** |
| (9,411.86) | |
| Public R&D | 1.15*** |
| (0.19) | |
| Company 10 | 33,047.18*** |
| (8,830.99) | |
| Company 2 | 35,794.77*** |
| (8,795.26) | |
| Company 3 | 36,860.79*** |
| (8,801.86) | |
| Company 4 | 5,193.58 |
| (8,857.36) | |
| Company 5 | 20,994.55** |
| (8,800.51) | |
| Company 6 | -4,121.64 |
| (8,954.31) | |
| Company 7 | 35,253.30*** |
| (8,845.63) | |
| Company 8 | 6,857.00 |
| (8,795.14) | |
| Company 9 | 19,830.50** |
| (8,887.64) | |
| Note: | p<0.1; p<0.05; p<0.01 |
We can see how the regression line varies for each company. The dark red, thicker line represent the regression results when dummies are not included.
Note that each line has a different intercept (which is predicted by our dummies) but the same slope - as \(\beta_1\) estimates the average within effect for all groups.
yhat = regDummy$fitted
colline = palette( c( "steelblue", "darkred", "forestgreen", "goldenrod1", "gray67", "turquoise4", "black" ) )
scatterplot(yhat ~ RDPub | as.factor(Company), boxplots = FALSE, xlab = "Public R&D Investment", ylab = "Predicted Company R&D Investment", smooth = FALSE, col=colline, lwd = 2, legend=c(title = "Companies"))
abline(lm( RD ~ RDPub ), lwd = 3, col = "red")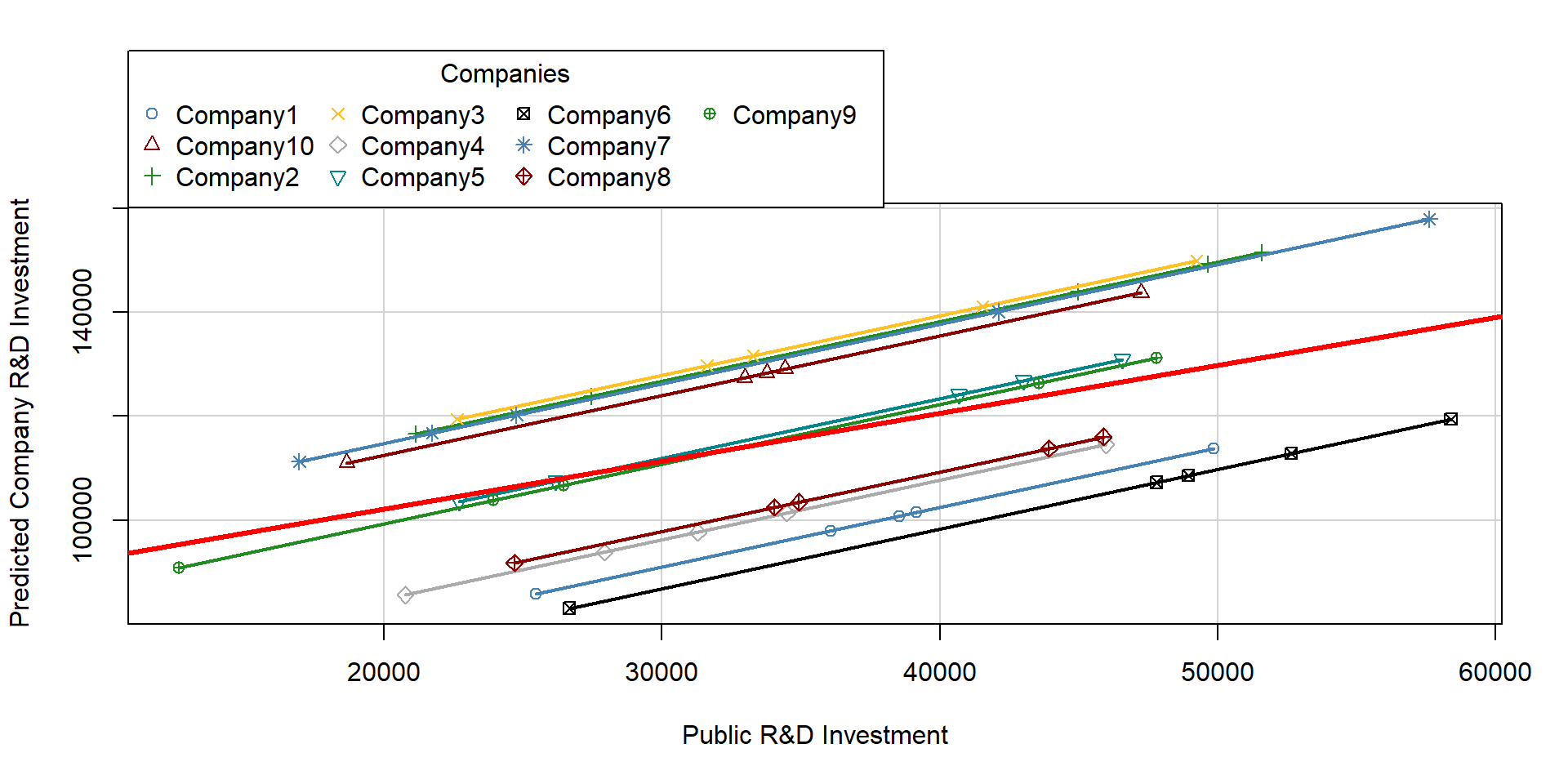
Figure 2.6: Plot of OLS with dummy variables
2.2 plm package
We can use the plm package to estimate the fixed effects model. In the output table, we compare results across the OLS, the OLS with dummies, and the fixed effect model.
fixed <- plm(RD ~ RDPub, data=data, index=c("Company"), model="within") ## The model is specified as a OLS model, but we need to indicate the "index" - i.e. the level of grouping.
stargazer( reg, regDummy, fixed,
type = "html",
dep.var.labels = ("Company R&D"),
column.labels = c("Ols", "Ols with Dummy", "Fixed"),
covariate.labels = c("Constant (or Company 1)", "Public R&D", "Company 10", "Company 2", "Company 3", "Company 4", "Company 5", "Company 6", "Company 7", "Company 8", "Company 9"),
omit.stat = "all",
digits = 2, intercept.bottom = FALSE )| Dependent variable: | |||
| Company R&D | |||
| OLS | panel | ||
| linear | |||
| Ols | Ols with Dummy | Fixed | |
| (1) | (2) | (3) | |
| Constant (or Company 1) | 83,671.23*** | 56,569.91*** | |
| (9,276.31) | (9,411.86) | ||
| Public R&D | 0.92*** | 1.15*** | 1.15*** |
| (0.25) | (0.19) | (0.19) | |
| Company 10 | 33,047.18*** | ||
| (8,830.99) | |||
| Company 2 | 35,794.77*** | ||
| (8,795.26) | |||
| Company 3 | 36,860.79*** | ||
| (8,801.86) | |||
| Company 4 | 5,193.58 | ||
| (8,857.36) | |||
| Company 5 | 20,994.55** | ||
| (8,800.51) | |||
| Company 6 | -4,121.64 | ||
| (8,954.31) | |||
| Company 7 | 35,253.30*** | ||
| (8,845.63) | |||
| Company 8 | 6,857.00 | ||
| (8,795.14) | |||
| Company 9 | 19,830.50** | ||
| (8,887.64) | |||
| Note: | p<0.1; p<0.05; p<0.01 | ||
As in the model with the dummy variables, the coefficient of the fixed effect model indicates, on average, how much the outcome (Company R&D) changes per country over time for a one unit increases of x (Public R&D).
Note that the fixed effect model estimated using plm does not have an intercept (see column #3 in the above table). When estimating the model with plm, we can retrieve each company’ intercept by using the command \(fixef\). The intercept for company A is the intercept in the dummy model (see column #2 in the above table).
fixef(fixed) ## Company1 Company10 Company2 Company3 Company4 Company5 Company6
## 56569.91 89617.09 92364.68 93430.70 61763.49 77564.46 52448.28
## Company7 Company8 Company9
## 91823.21 63426.91 76400.41The plm package also allows us to test whether the fixed effect model is a better choice compared to the OLS model with the \(pFtest\) command. If the p-value is lower than 0.05, than the fixed effect model is a better choice.
pFtest(fixed, reg) ##
## F test for individual effects
##
## data: RD ~ RDPub
## F = 6.4244, df1 = 9, df2 = 39, p-value = 1.516e-05
## alternative hypothesis: significant effects2.3 Key notes on fixed effects
Before moving to random effects, we need to point out some important features that you need to remember about fixed effect models:
- Using a fixed effect model allows us to control for all time - invariant characteristics of an entity (even characteristics that you cannot measure or observe); we assume that some characteristics of the entity we are investigating (e.g., the country or the company) affect our predictor and we need to control for it. Note that a fixed effect model control for all time invariant characterists, thus reducing omit variable bias issues.
- BUT you cannot investigate time-invariant characteristics using fixed effects. For instance, in the previous example, we cannot investigate the effect of a company location. As the location does not change over time, the fixed effects “absorb” this variation. Statistically, time-invariant characteristics are perfectly collinear with the dummy, so as their effect cannot be estimated in the model (you can see a practical example in section 3)
- Because of this, you need to keep in mind that fixed effects are designed to investigate time-variant characteristics within an entity.
- Finally, fixed effects assume that each entity is unique, such that the error terms and each entity’s constant are not correlated with other entities’ error terms and constant. In other words, there is independence across entities. This condition can be tested using a randome effect model and an Hausman test (see section 4).
3 Replication of a study
Figure 3.1: Deterrence Theory
As replication study we are going to look at research on deterrence theory. Deterrence theory argues that individuals refrain from engaging in deviant activities if they know they will be punished and if they know the pain will be severe, as illustrated in figure 3.1. This theory is often applied to justify more severe penalties ( such as the death penalty ) and explain why crime rates have decreased in recent years. Of course, there are mixed opinions and evidence.
We will use a panel dataset of 90 observational units (counties) from 1981 to 1987 collected by Cornwell and Trumbull in 1994 (you can find the full paper here ). Data look at whether the certainty of (1) being arrested, (2) being convicted, or (3) being sentencing to prison and (4) the severity of the pain decrease crimes within a given county.
Research question: Do certainty and severity of pain lead to lower crime?
Hypothesis: Based on deterrence theory, we argue that greater certainty or severity of pain will decrease crime in a given county.
3.1 Data
We start by uploading the data Crime from the plm package,
data(Crime)
dataCrime = CrimeYou can see te structure of the dataset and the main independent variables in the following table. Note that for each county (1 and 3 in this case), we have data from 1981 to 1987.
head(dataCrime[,1:7], 10)## county year crmrte prbarr prbconv prbpris avgsen
## 1 1 81 0.0398849 0.289696 0.402062 0.472222 5.61
## 2 1 82 0.0383449 0.338111 0.433005 0.506993 5.59
## 3 1 83 0.0303048 0.330449 0.525703 0.479705 5.80
## 4 1 84 0.0347259 0.362525 0.604706 0.520104 6.89
## 5 1 85 0.0365730 0.325395 0.578723 0.497059 6.55
## 6 1 86 0.0347524 0.326062 0.512324 0.439863 6.90
## 7 1 87 0.0356036 0.298270 0.527596 0.436170 6.71
## 8 3 81 0.0163921 0.202899 0.869048 0.465753 8.45
## 9 3 82 0.0190651 0.162218 0.772152 0.377049 5.71
## 10 3 83 0.0151492 0.181586 1.028170 0.438356 8.69These are the main independent variables that we will be investigating:
| Variable | Description |
|---|---|
| Crime | FBI index crimes to county population |
| prbarr | Ratio of offenses to arrests (probability of arrest) |
| prbconv | Ratio of convinction to arrests (probability of conviction) |
| prbpris | Ratio of prison sentences to convinctions (probability of prison sentence) |
| avgsen | Average number of days for prison sentence (severity of the pain) |
Here are some basic statistics.
stargazer( dataCrime,
type = "html",
keep = c("^crmrte", "^prbarr", "^prbconv", "^prbpris", "^avgsen"),
omit.summary.stat = c("p25", "p75"),
digits = 2 )| Statistic | N | Mean | St. Dev. | Min | Max |
| crmrte | 630 | 0.03 | 0.02 | 0.002 | 0.16 |
| prbarr | 630 | 0.31 | 0.17 | 0.06 | 2.75 |
| prbconv | 630 | 0.69 | 1.69 | 0.07 | 37.00 |
| prbpris | 630 | 0.43 | 0.09 | 0.15 | 0.68 |
| avgsen | 630 | 8.95 | 2.66 | 4.22 | 25.83 |
The average crime rate across all counties and years is 3.84%. The average probability of arrest is 30.74%. The average probability of convinction is 68.86%. The average probability of prison sentence is 42.55%. The average length of prison stay is 8.955 days.
These are the control variables that we will also include in the model:
| Variable | Description |
|---|---|
| wcon | Average wage in constuction |
| wtuc | Average wage in transportation, Utilities and Communication |
| wtrd | Average wage in retail trade |
| wfir | Average wage in finance, insurance, real estate |
| wser | Average wage in service industry |
| wmfg | Average wage in manufacturing |
| wfed | Average wage in federal government |
| wsta | Average wage in state government |
| wloc | Average wage in local government |
| smsa | Counties included in a metropolitan area |
| density | population density |
| region | County location: West, central or other |
| polpc | Police per capita |
| pctymle | Percentage male between 15 and 24 |
| pctmin | Percentage minority |
3.2 Analysis
We will estimate two models. The first model is an OLS model. The second model will include fixed effects to control for variation across years and counties.
OLS.Crime = lm(crmrte ~
prbarr +
prbconv +
prbpris +
avgsen +
polpc +
density +
region +
smsa +
pctmin +
wcon +
wtuc +
wtrd +
wfir +
wser +
wmfg +
wfed +
wsta +
wloc +
pctymle,
data = dataCrime)
Fixed.Crime = plm(crmrte ~
prbarr +
prbconv +
prbpris +
avgsen +
polpc +
density +
region +
smsa +
pctmin +
wcon +
wtuc +
wtrd +
wfir +
wser +
wmfg +
wfed +
wsta +
wloc +
pctymle, index=c("county"), data = dataCrime)
stargazer( OLS.Crime, Fixed.Crime,
type = "html",
dep.var.labels = ("Crime rates"),
column.labels = c("OLS", "Fixed effects"), intercept.bottom = FALSE,
omit.stat = "all",
digits = 2)| Dependent variable: | ||
| Crime rates | ||
| OLS | panel | |
| linear | ||
| OLS | Fixed effects | |
| (1) | (2) | |
| Constant | 0.01*** | |
| (0.005) | ||
| prbarr | -0.03*** | -0.01*** |
| (0.003) | (0.002) | |
| prbconv | -0.002*** | -0.001*** |
| (0.0003) | (0.0002) | |
| prbpris | -0.0000 | -0.001 |
| (0.005) | (0.004) | |
| avgsen | -0.0000 | 0.0002* |
| (0.0001) | (0.0001) | |
| polpc | 2.59*** | 2.15*** |
| (0.17) | (0.16) | |
| density | 0.01*** | 0.01* |
| (0.001) | (0.005) | |
| regionwest | -0.01*** | |
| (0.002) | ||
| regioncentral | -0.01*** | |
| (0.001) | ||
| smsayes | -0.002 | |
| (0.003) | ||
| pctmin | 0.0001*** | |
| (0.0000) | ||
| wcon | -0.0000 | -0.0000 |
| (0.0000) | (0.0000) | |
| wtuc | -0.0000 | -0.0000 |
| (0.0000) | (0.0000) | |
| wtrd | 0.0000 | -0.0000 |
| (0.0000) | (0.0000) | |
| wfir | -0.0000 | -0.0000 |
| (0.0000) | (0.0000) | |
| wser | -0.0000 | 0.0000 |
| (0.0000) | (0.0000) | |
| wmfg | 0.0000 | -0.0000 |
| (0.0000) | (0.0000) | |
| wfed | 0.0000*** | -0.0001*** |
| (0.0000) | (0.0000) | |
| wsta | -0.0000* | 0.0000 |
| (0.0000) | (0.0000) | |
| wloc | 0.0000 | 0.0000** |
| (0.0000) | (0.0000) | |
| pctymle | 0.08*** | -0.21 |
| (0.02) | (0.15) | |
| Note: | p<0.1; p<0.05; p<0.01 | |
Note differences across the two models:
- The fixed effect model has no intercept. We can retrieve the intercept for each county using the command \(fixef\).
fixef(Fixed.Crime) ## 1 3 5 7 9 11
## 0.06008380 0.04616095 0.04397873 0.05618387 0.03963517 0.04850172
## 13 15 17 19 21 23
## 0.06693969 0.05398029 0.05586298 0.05241807 0.05696899 0.05808010
## 25 27 33 35 37 39
## 0.05076612 0.06333701 0.04798006 0.06405122 0.05570115 0.04315078
## 41 45 47 49 51 53
## 0.05564134 0.05978015 0.06377220 0.07761934 0.08456992 0.04635910
## 55 57 59 61 63 65
## 0.08010031 0.05393594 0.04689486 0.05541325 0.07288809 0.09176798
## 67 69 71 77 79 81
## 0.03702207 0.05798697 0.06007574 0.07583131 0.04347463 0.05977589
## 83 85 87 89 91 93
## 0.06326111 0.07448984 0.06317630 0.05528267 0.06590669 0.07010747
## 97 99 101 105 107 109
## 0.06543167 0.06063011 0.06376829 0.07722246 0.07599284 0.04531503
## 111 113 115 117 119 123
## 0.04216029 0.04223970 0.02100296 0.05071326 0.06648979 0.06092552
## 125 127 129 131 133 135
## 0.05737006 0.07294416 0.06680016 0.05508579 0.09956319 0.08888891
## 137 139 141 143 145 147
## 0.04084588 0.06435933 0.07141286 0.05268857 0.06063136 0.09052899
## 149 151 153 155 157 159
## 0.04458252 0.05622279 0.06265948 0.06394358 0.05619013 0.05654222
## 161 163 165 167 169 171
## 0.05226790 0.05309409 0.07575148 0.05273969 0.04319476 0.05064528
## 173 175 179 181 183 185
## 0.03590281 0.04584681 0.05779035 0.08729171 0.06835270 0.03340218
## 187 189 191 193 195 197
## 0.06241153 0.06864923 0.05538939 0.05567039 0.07003994 0.04124668The variables that are time-invariant such as region type, location in a metropolitan area, or minority percentage are removed from the fixed-effect model.
We can compare OLS and fixed effect results using the \(pFtest\) command. Remember if the p-value < 0.05, the fixed effect model is a better choice than the OLS model.
pFtest(Fixed.Crime, OLS.Crime) ##
## F test for individual effects
##
## data: crmrte ~ prbarr + prbconv + prbpris + avgsen + polpc + density + ...
## F = 12.181, df1 = 85, df2 = 524, p-value < 2.2e-16
## alternative hypothesis: significant effects4 Random effects
As mentioned in section 2.3, fixed effects assume that there is no correlation across entities’ error term and constants - i.e., that each entity is independent from others.
This assumption can be tested by using a random effects model, where we assume that differences across entities influence our dependent variable, and there is correlation across entities’ error terms and constants.
We use our previous example about R&D investment to illustrate a random effect model. The model can be estimated using the \(plm\) function and specifying \(model = "random"\).
random <- plm(RD ~ RDPub, data=data, index=c("Company", "Year"), model="random")
stargazer( random,
type = "html",
dep.var.labels = ("Company R&D"),
column.labels = c(""),
covariate.labels = c("Constant", "Public R&D"),
omit.stat = "all",
digits = 2, intercept.bottom = FALSE )| Dependent variable: | |
| Company R&D | |
| Constant | 77,087.49*** |
| (8,281.97) | |
| Public R&D | 1.10*** |
| (0.19) | |
| Note: | p<0.1; p<0.05; p<0.01 |
Interpretation of the coefficients is tricky since they include both the within-entity and between-entity effects. It represents the average effect of X over Y, when X changes across time and between countries by one unit.
There are tests that you can run to chose between fixed and random effects. For instance, the Hausmann test compare a fixed and a random effect model. If the p-value is < 0.05 then fixed effects is a better choice.
phtest(fixed, random)##
## Hausman Test
##
## data: RD ~ RDPub
## chisq = 5.2567, df = 1, p-value = 0.02186
## alternative hypothesis: one model is inconsistent4.1 Notes on random vs fixed effects
- Random effects allows you to include time-invariant characteristics of your entities because it assumes that the error terms of the entity are not correlated with the predictor.
- Random effects is affected by the omitted variable bias problem. Since we are not including dummy variables that account for all time-invariant characteristics of an entity, we need to carefully specify our control variables.
- The choice between random and fixed effects is not random! You need to perform the Hausman test to decide which model is a better fit. Fixed effects is generally a better model (Berry, 2011)
5 Additional resources
Some examples and graphs discussed in this lecture are inspired by “Panel Data Analysis Fixed and Random Effects using Stata” designed by Oscar Torres-Reyna (2007).
Another good presentation of fixed effects and research designed is Christopher Berry (2011).