Regression Discontinuity Design
Packages
For this lab we will use the following packages:
- stargazer for nice regression tables
- dplyr for data wrangling
- pander for nice tables
library( stargazer )
library( dplyr )
library( pander )Learning objectives
- When is it appropriate to use a regression discontinuity design?
- How should you organize your data before using a regression discontinuity design?
- How do you interpret the coefficients of a regression discontinuity model?
- What are the main assumptions of a regression discontinuity model?
- Applying a discontinuity regression design to data in R
1 The key concept
“Selection” is one of the most challenging problems in evaluation. Selection occurs when participants decide whether or not to participate in the program, i.e. they select into the program. Typically this means that program participants are different from non-participants, and as a result we will commonly observe performance differences between the two groups but it is challenging to determine whether they are partly from program impact or whether they are entirely driven by other behaviors or characteristics of program participants. Selection and omitted variable bias are synonymous.
To give a concrete example, we might be interested in whether going to the gym lowers heart disease so we use survey data to identify a population that includes adults between ages of 30 and 40 that actively visit the gym each week and those that do not. We wish to compare some basic metrics of heart health to see if gym memberships might improve heart health. The problem is that most people with gym memberships embrace other healthy lifestyle choices such as eating organic or vegetarian diets and not smoking. As a result, comparing gym members to non-members was an apples to oranges comparison before the effects of membership were realized.
The regression discontinuity model was created to deal with one very specific type of selection - cases where people have to qualify for the program, and the criteria for qualification is a measure that is highly correlated with performance. Some threshold is created and all people that score above the threshold are accepted into the program, and all people below are not allowed to participate, or vice-versa.
When a criteria is used to determine program eligibility in this way it automatically sorts the data into high performers and low performers, thus ensuring that large pre-treatment group differences are baked into the program.
For example, a standardized exam might be used to determine the roster for honors classes in a high school. It would be hard to evaluate whether honors courses improve academic performance once students metriculate in college because there are already large differences between program participants and non-participants (honors students and regular students).
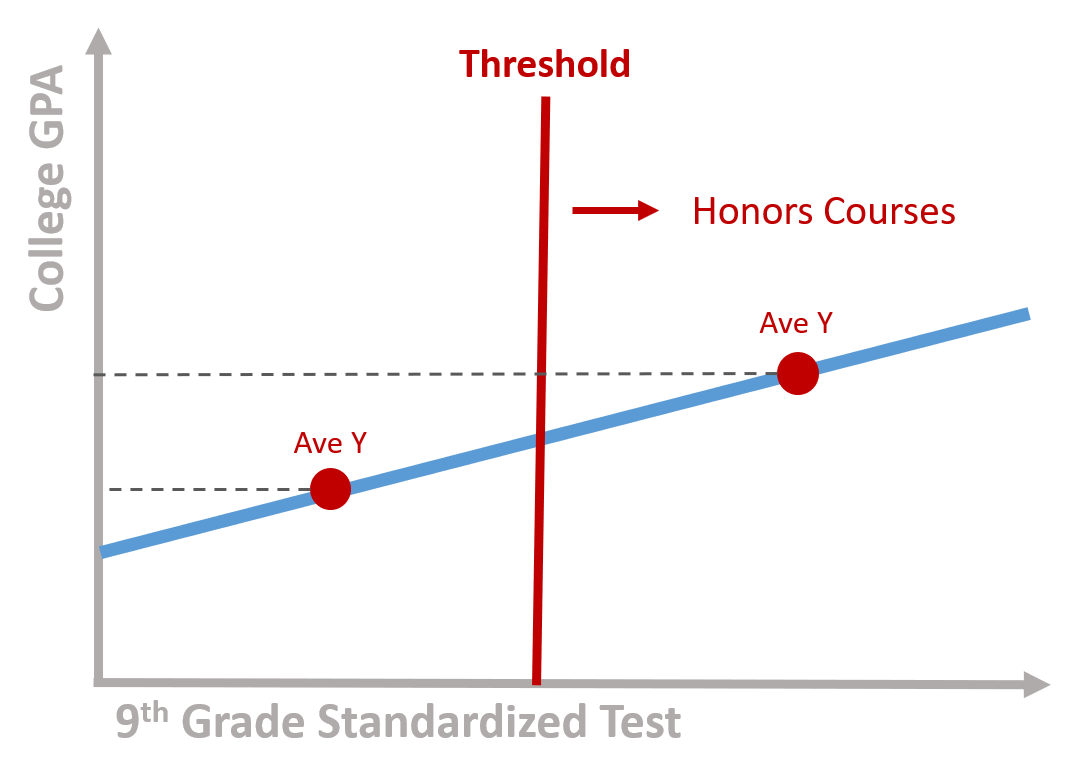
Figure 1.1: Program participants score above the threshold
Alternatively, perhaps all students that score below the threshold are required to attend remedial summer school courses. Do these expensive summer programs help close the achievement gap so students do better in college? Those in the “treatment” group will be very different from those that did not have to attend summer school, and as a result we run a risk of failing to detect achievement gains when we compare the treatment to “control” or comparison group.
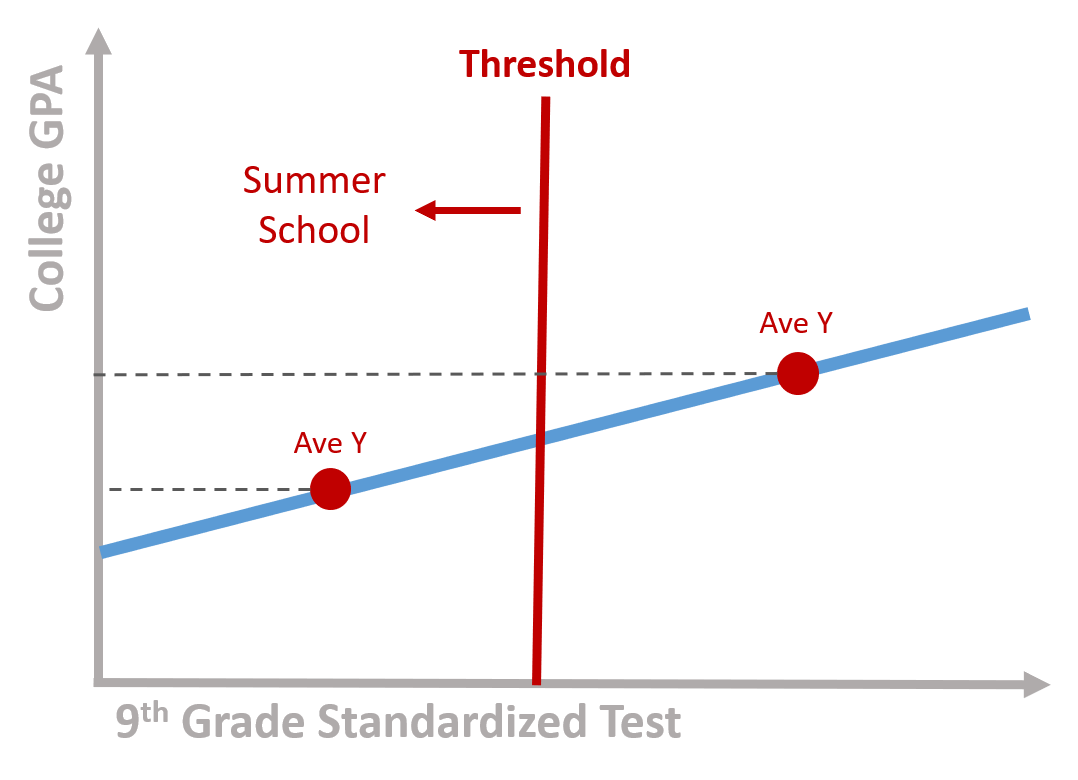
Figure 1.2: Program participants score below the threshold
If you have performance data for both groups before and after the program occurs then you can use a difference-in-difference framework to compare gains across the two groups and parse out program impact. If you are using post-program administrative data, or if it is impossible to measure performance prior to program completion (there is no pre-program college GPA for the exmaple above, for example), then regression discontinuity is appropriate.
It turns out that a lot of programs and public policies have some criteria for participation that create these inferential challenges.
- A tutoring program designed to improve reading skills of students who perform poorly on a reading test. Students with an average score of 50/100 participate in the tutoring program (treatment group), while students with a score above 50 are not included in the tutorial sessions (control group);
- A government program (such as Medicare) where individuals can enroll only after a certain age. Individuals who are older are enrolled (treatment group) while individuals who are yourger are not enrolled (control group);
- A house subsidy program to support low-income populations paying rent. Only individuals with a income below a certain level will receive the subside (treatment group) while others will not (control group);
- A law that faciliates admission to college for the top 10% students from low-ranked high schools; students in the top 10% will be part of the program (treatment group), while students below the top 10% will not (control group)
The key problem is the endogeneity between the outcome and the assignment of the treatment. Scholarships are a classical example. For instance, let’s imagine a scholarship which is offered to low income students to attend college. You can see a representation of the model in figure 1.3. The x axis is the family income based on which we assign students to the treatment or control group. We call it the rating variable. The y axis is the likelihood to enroll into college. It is our outcome variable. There is a positive relationship between the two: students from higher income families are more likely to enroll to college.
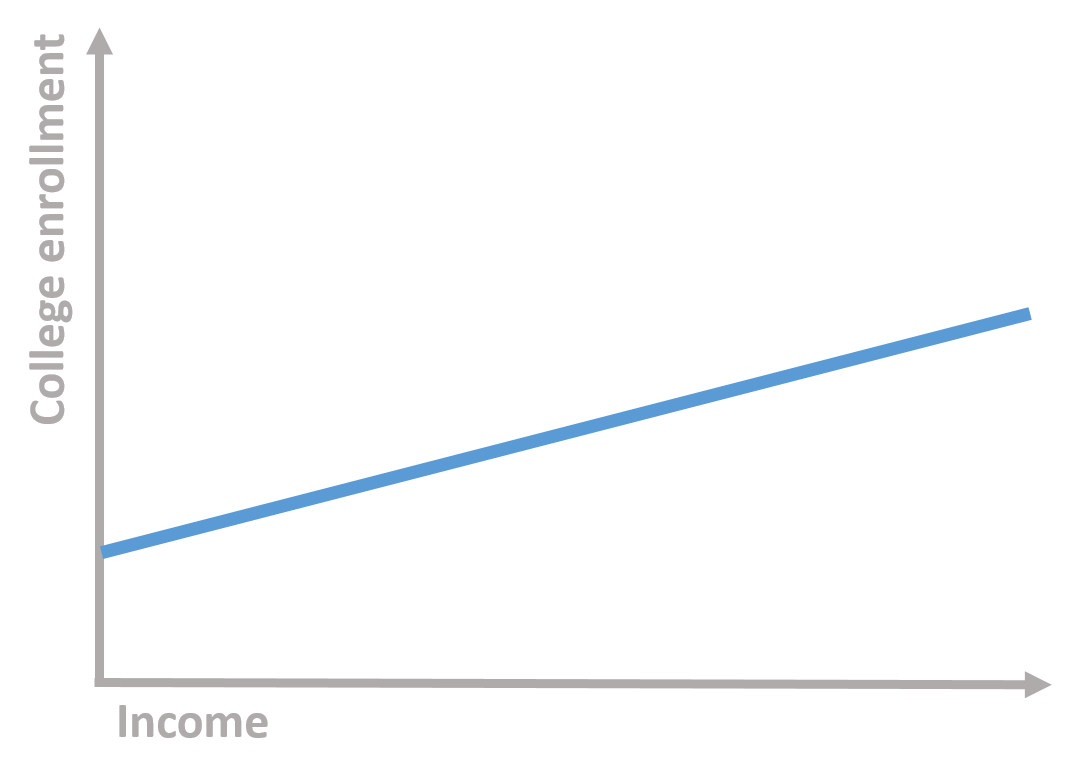
Figure 1.3: Students’ family income and college enrollment
We establish to give a scholarship to students below a given level of income (the cutoff). We have two groups: one group receive the scholarship (treatment group) while the other does not (control group).
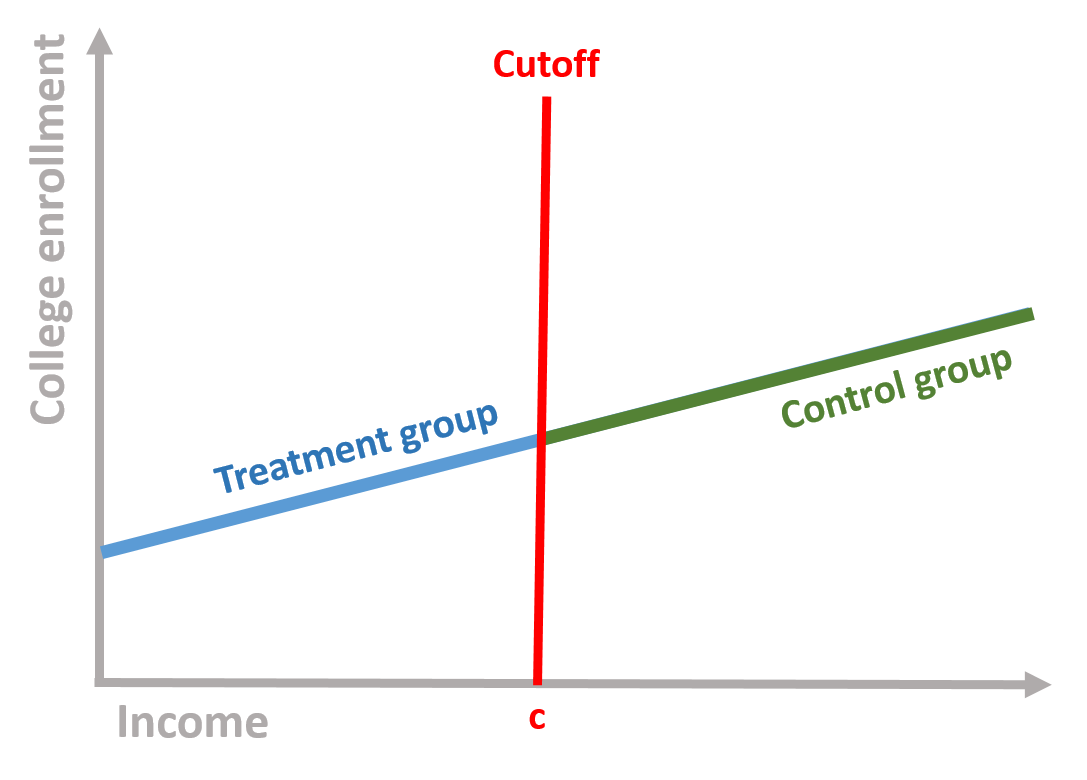
Figure 1.4: Control and treatment group based on the cutoff
Comparing these two groups, however, is problematic. Students who did not receive the scholarship (the control group) are more likely to go to college even without the scholarship because of their income. Their enrollment is likely to remain higher than the enrollment of low-income students. This does not imply that the scholarship has no effect: it might be that in the absence of the treatment (i.e., without the scholarship), low-income students would have been even less likely to enroll to college.
Regression discontinuity is used to solve this problem and assess whether or not we observe a treatment effect. It does so by accounting for the relationship between the outcome and the rating variable and then calculating the difference between the two groups.
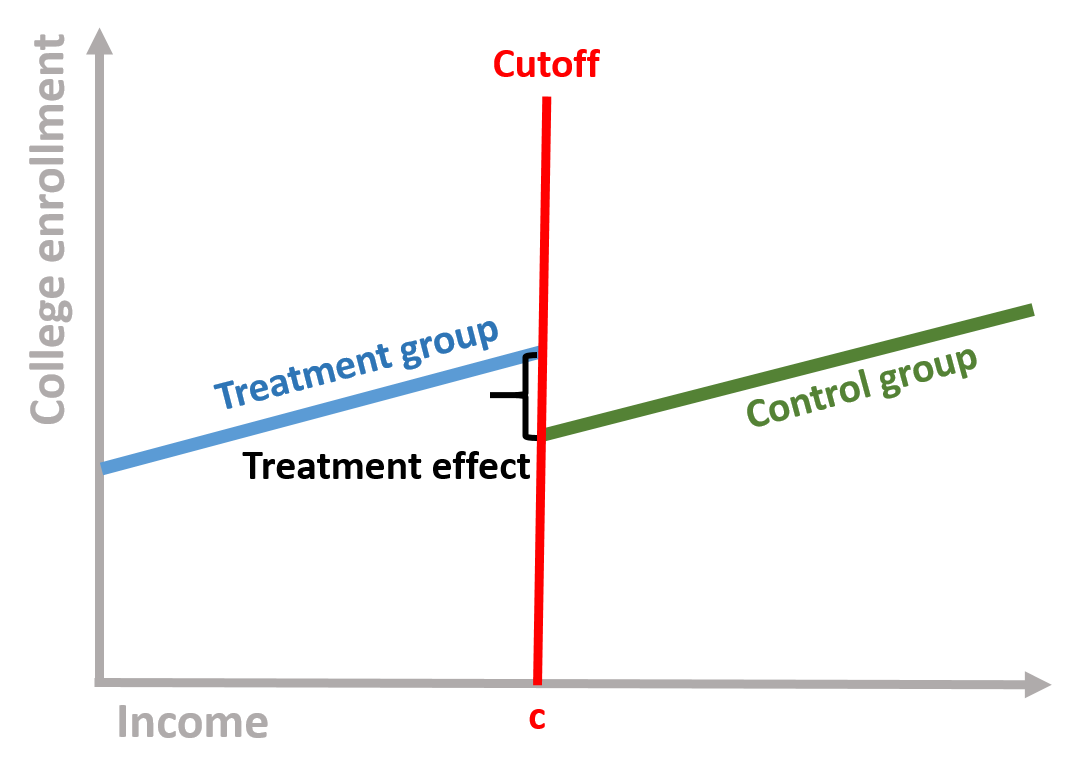
Figure 1.5: Treatment effect
The intuition behind the regression discontinuity design is the endogeneity of the outcome to the assignment of treatment, which might bias the estimation of the effect of the treatment. Low-income students might continue to enroll to college at a lower rate even with a scholarship, leading to a downward bias of the estimates. Similarly, low-income populations receiving a subsidy to pay rent might continue to have more housing issues than higher income individuals. Individuals who receive Medicare might have greater health problems because of age, and without controlling for the relationship between age and health outcomes, we might have a downward estimates of the effect of the program. The regression discontinuity model allows us to estimate the local treatment effect, comparing individuals close by the cut off points.
1.1 The statistical model
In mathematical terms, we are interested in estimating the following equation:
\[\begin{equation} \text{Y} = \beta_0 + \beta_1*Treatment + \beta_2*Rating variable_c + \text{e} \tag{1.1} \end{equation}\]
Where:
\(\text{Y}\) is our outcome variable;
\(\text{Treatment}\) is a dummy variable indicating the treatment (=1) and the control (=0) group;
\(\text{Rating variable_c}\) is the rating variable centered at the cutoff point. To center the variable, we just need to subtract the cutoff score from each individual score. The cut-off point will become the new intercept (since cut-off - cut-off = 0), which it will help to interpret the results.
Our dataset will look like this. In the figure, I reported the procedure to center the rating variable on the side for clarification purposes.
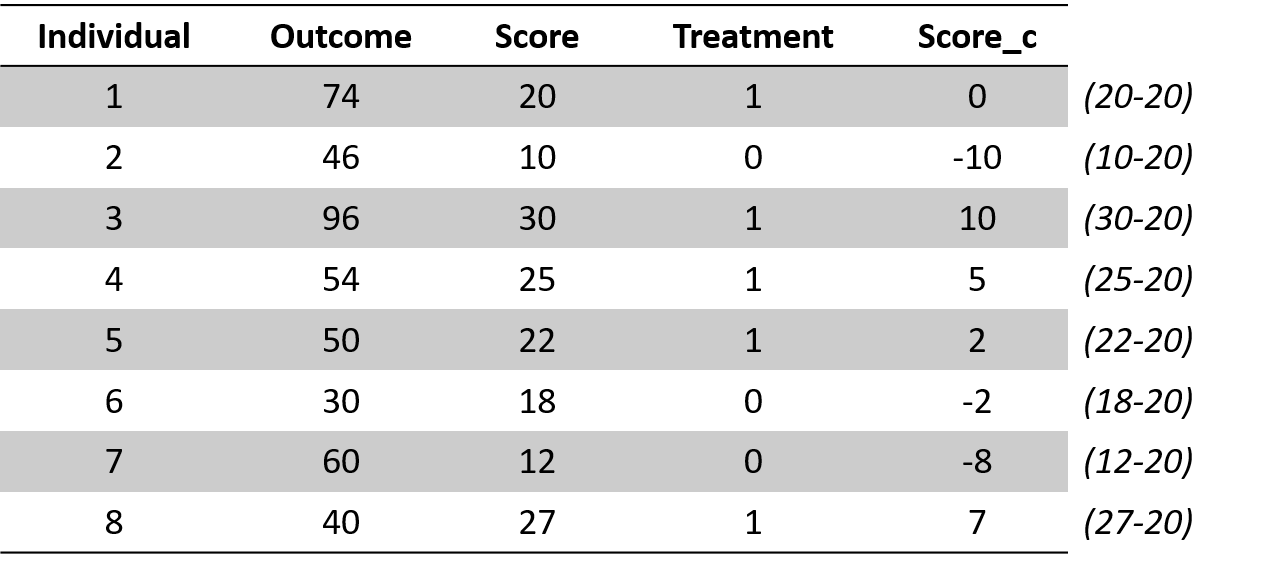
Figure 1.6: Regression discontinuity dataset
We can consider each coefficient of our equation (1.1) separately.
- \(\beta_1\) represents the difference between the treatment and the control group and assesses whether the intervention had an effect.
- \(\beta_2\) represents the relationship between the outcome variable and the rating variable. It allows us to control for endogeneity in this relationship.
1.2 The counterfactual
The counterfactual is what it would have occured to Y, had the policy intervention not happened. It is very important in regression discontinuity . For instance, in our previous regression discontinuity model, the counterfactual is the students’ likelihood to enroll, if they had not received the scholarship.
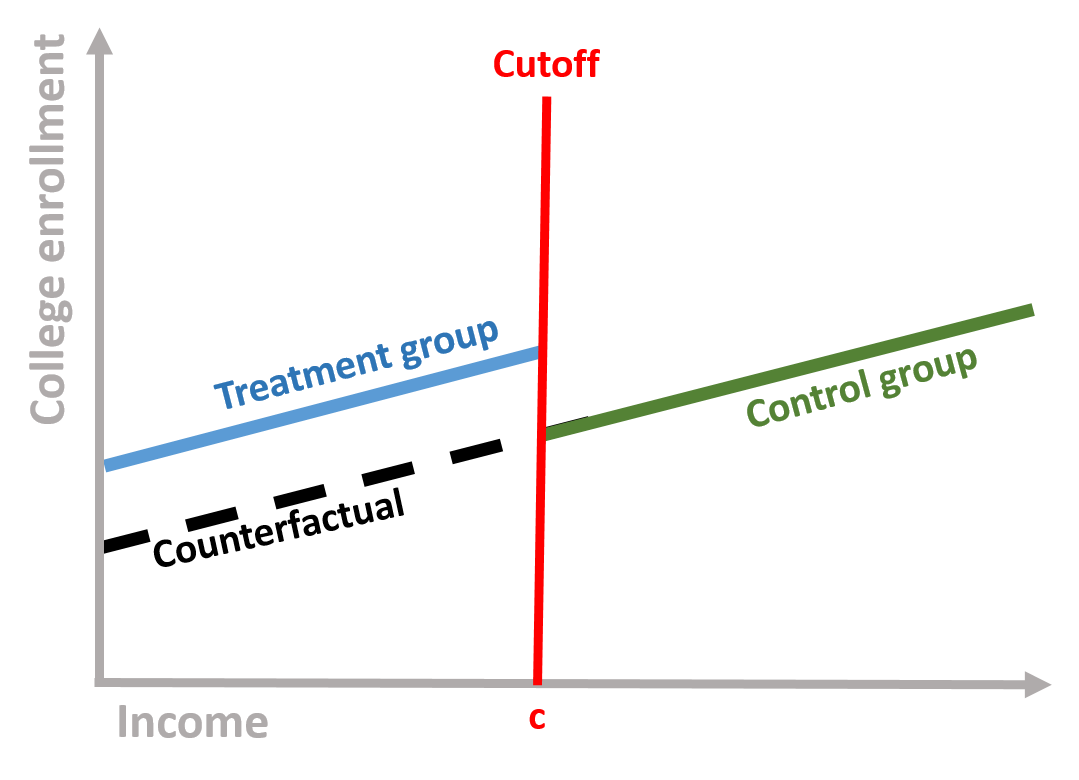
Figure 1.7: Counterfactual
If we take our equation (1.1), the counterfactual is obtained by assuming that the intervetion has not occured (Treatment = 0), so that Y is only predicted by its relationship with rating variable:
\[\begin{equation} \text{Y} = \beta_0 + \beta_1*0 + \beta_2*Score + \text{e} \tag{1.2} \end{equation}\]
2 A regression-discontinuity model

Figure 2.1: Source: https://www.pinterest.com/youthchange/classroom-posters-121-130/
We are going to look at the relationship between class attendance and students’ performance. There is a lots of research and evidence that class attendance has a positive and significant effect on student performance. Because of this, government agencies and schools aim to design policies that incentivize students not to miss school days. Examples include tangible prizes such as colorful pendants and free tickets to event, automated calls from celebrities, or class policies that mandate attendance to students.
Research has used several methods to test this relationship, from simple regression analysis to randomized experiments. In this example, we imagine to look at three classes of college students and assign students who have an attendance rate lower than the median to the treatment group, as they would be subject to a mandatory attendance policy. Students who have an attendance rate greater than the median will be the control group.
Research question: Does a mandatory attendance policy increase student final performance?
Hypothesis: A mandatory attendance policy will increase the final performance of students enrolled in the treatment.
2.1 Data
The dataset contains four variables.
| Variable name | Description |
|---|---|
| \(\text{Performance}\) | Final exam grade, from 0 to 100 |
| \(\text{Treatment}\) | Dummy variable if Treatment group (=1) or Control group (=0) |
| \(\text{Attendance}\) | Percentage of classes attended from 0% (attended no class) to 100% (attended all classes) - Rating variable |
| \(\text{Attendance_c}\) | Attendance variable centered around the cutoff. The cutoff was fixed at the median of Attendance |
head( data, 10 ) %>% pander()| Performance | Treatment | Attendance | Attendance_c |
|---|---|---|---|
| 77.7 | 0 | 88.96 | 9.704 |
| 76.43 | 0 | 88.84 | 9.583 |
| 61.51 | 1 | 62.68 | -16.58 |
| 76.47 | 0 | 83.4 | 4.142 |
| 87.26 | 0 | 94.57 | 15.31 |
| 67.51 | 1 | 73 | -6.261 |
| 64.18 | 1 | 73.59 | -5.672 |
| 70.15 | 0 | 79.77 | 0.5083 |
| 63.33 | 1 | 66.32 | -12.94 |
| 76.18 | 0 | 86.47 | 7.206 |
The problem with comparing the treatment and the control group is that students with lower attendance (treatment group) are more likely to have lower grades than students with higher attendance. Because of this, if we compare the means of the two groups we might observe no different between them.
We can empirically see this:
mean( data$Performance[ data$Treatment==1 ] )## [1] 57.93795mean( data$Performance[ data$Treatment==0 ] )## [1] 76.67116Students who did not receive the treatment have a higher mean than students who did receive the treatment. If we were just to look at these results, we would conclude that the treatment had no effect.
2.2 Analysis
Our model is based on the equation (1.1):
reg <- lm( Performance ~ Treatment +
Attendance_c, data = data )
stargazer( reg,
type = "html",
dep.var.labels = ("Final exam grade"),
column.labels = c(""),
covariate.labels = c("Treatment", "Attendance"),
omit.stat = "all",
digits = 2 )| Dependent variable: | |
| Final exam grade | |
| Treatment | 7.03*** |
| (0.59) | |
| Attendance | 1.16*** |
| (0.02) | |
| Constant | 66.41*** |
| (0.32) | |
| Note: | p<0.1; p<0.05; p<0.01 |
We interpret each coefficients:
\(\beta_0\) represents the Performance of a student exactly at the cut-off point
\(\beta_1\) is positive and significantly different from zero. This indicates that the Treatment had an effect and students in the treatment group saw their grade increased of 7 points.
\(\beta_2\) is positive and significantly different from zero. This indicates a positive relationship between attendance and the final exam grade.
It’s common practice to center the score (rating) variable. Because our rating variable is centered, the intercept is located at the cutoff point and represents the average final score of a student with a median attendance. It’s possible to run the same model without centering the score variable. However, the interpretation of our intercept would change. It would be the final score of a student with 0 attendance. Centering the score variable simplying our interpretation of the results and more precisely estimate the average treatment effect right after and right before the cutoff point.
We can see this by running the model with an uncentered rating variable. The coefficient of Treatment and Attendance do not change but the intercept significantly change.
reg <- lm( Performance ~ Treatment + Attendance, data = data )
stargazer( reg,
type = "html",
dep.var.labels = ("Final exam grade"),
column.labels = c(""),
covariate.labels = c("Treatment", "Attendance"),
omit.stat = "all",
digits = 2 )| Dependent variable: | |
| Final exam grade | |
| Treatment | 7.03*** |
| (0.59) | |
| Attendance | 1.16*** |
| (0.02) | |
| Constant | -25.22*** |
| (1.89) | |
| Note: | p<0.1; p<0.05; p<0.01 |
2.3 Plotting the results
We can visually observe the discontinuity in the following plot. The black line indicating the predicted value changes at the cutoff line. The control group (blue) is in a higher position than the treatment group, suggesting that students who had mandatory attendance performed better than we would have expected without the policy.
# We first predict the final exam grades based on our regression discontinuity model.
predfit <- predict( reg, data )
# We set colors for the graph
palette( c( adjustcolor( "steelblue", alpha.f=0.3), adjustcolor( "darkred", alpha.f=0.3) ) )
# To differently color the treatment and control group we need to create a new Treatment variable that where the Control group = 2.
data$Treatment2 <- ifelse( data$Treatment==0, 2, 1 )
# Plot our observed value
plot( Attendance_c, Performance, cex=2,
col=data$Treatment2, pch=19, bty="n",
xlab="Attendance Rate (centered)",
ylab="Final exam grade")
# Plot a line at the cutoff point
abline( v=0, col="red", lwd=2, lty=2 )
# Plot our predicted values
points( Attendance_c, predfit, col="black", cex=0.8, pch = 19 )
## Add a legend
points( 10, 26, col="steelblue", pch=19, cex=2 )
text( 10, 26, "Treatment group", col="steelblue", pos=4 )
points( 10, 20, col="darkred", pch=19, cex=2 )
text( 10, 20, "Control group", col="darkred", pos=4 )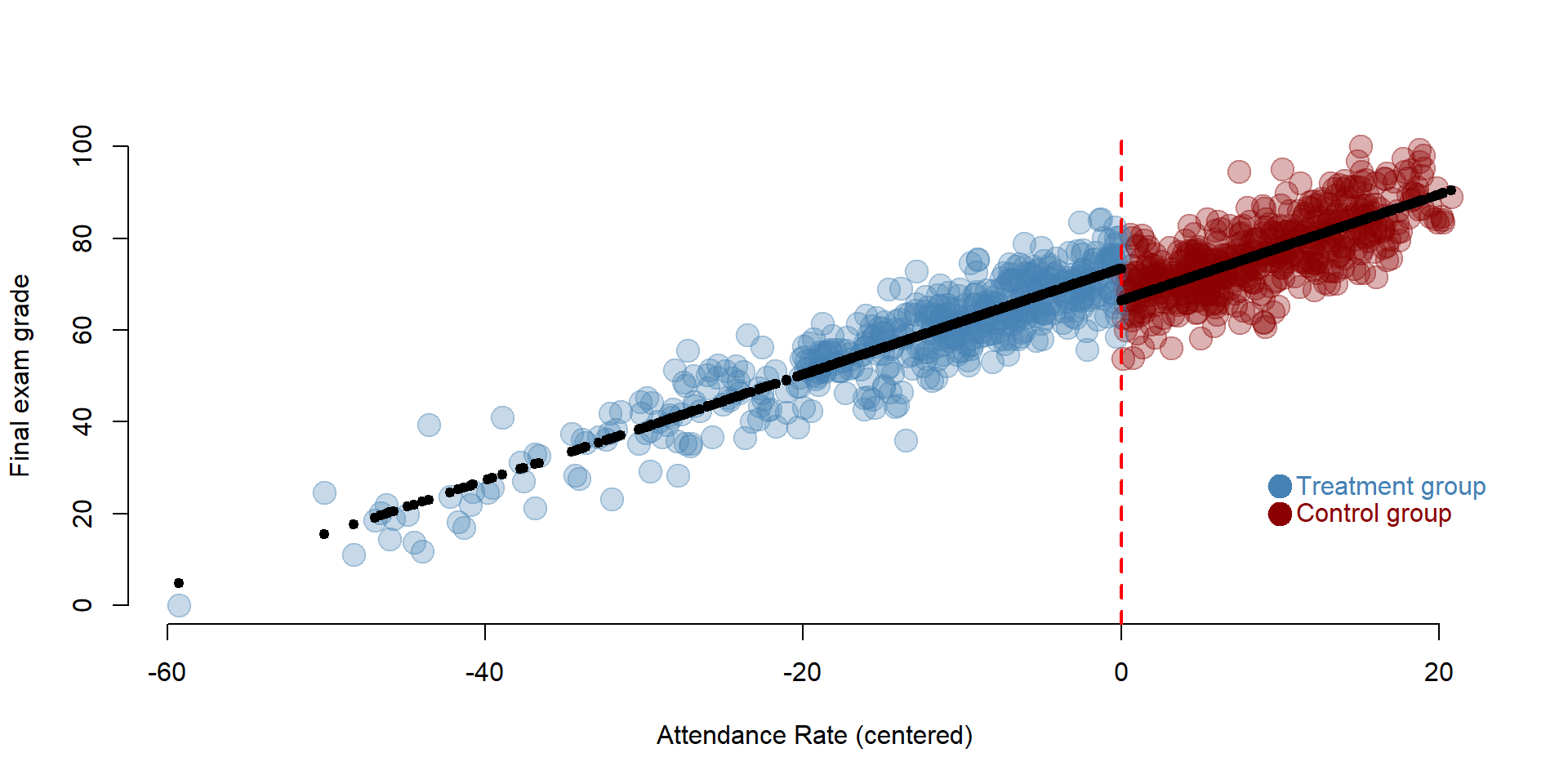
2.4 The counterfactual
The discontinuity is easier to understand if we plot the counterfactual using the formula (1.2):
The counterfactual represents the final exame grades, had the policy of mandatory attendance not been implemented. It’s the yellow group in the graph. Students in the treatment group would have performed worse without the policy. The yellow dots are - on average - in a lower position than the blue ones (which represent the score after the treatment).
## We create a new dataset where the variable Treatment is only equal to 0 as no student has been part of the intervention
data2 <- data.frame( Performance=data$Performance,
Treatment=rep(0),
Attendance_c=data$Attendance_c )
## Based on our previous model we predict the final grades, had the intervention not occured
predfit2 <- predict( reg, data2 )
data2$predfit2 <- predfit2
## We set a new color for representing the counterfactual
counterfactual <- adjustcolor("darkorange2", alpha.f=0.2 )
## Plot the observed valies
plot( Attendance_c, Performance, cex=2,
col=data$Treatment2, pch=19, bty="n",
xlab="Attendance Rate (centered)",
ylab="Final exam grade")
# Plot a line at the cutoff
abline( v=0, col="red", lwd=2, lty=2 )
# Plot the counterfactual
# Note that we add a bit of noise in the data to facilitate visualization
points( Attendance_c[ Attendance_c < 0 ],
predfit2[ Attendance_c < 0 ] + rnorm(500,0,5),
col=counterfactual, lwd=2, pch = 19, cex = 2 )
# Add a legend
## Add a legend
points( 10, 20, col="steelblue", pch=19, cex=2 )
text( 10, 20, "Treatment group", col="steelblue", pos=4 )
points( 10, 26, col="darkred", pch=19, cex=2 )
text( 10, 26, "Control group", col="darkred", pos=4 )
points( 10, 14, col="darkorange2", pch=19, cex=2 )
text( 10, 14, "Counterfactual", col="darkorange2", pos=4 )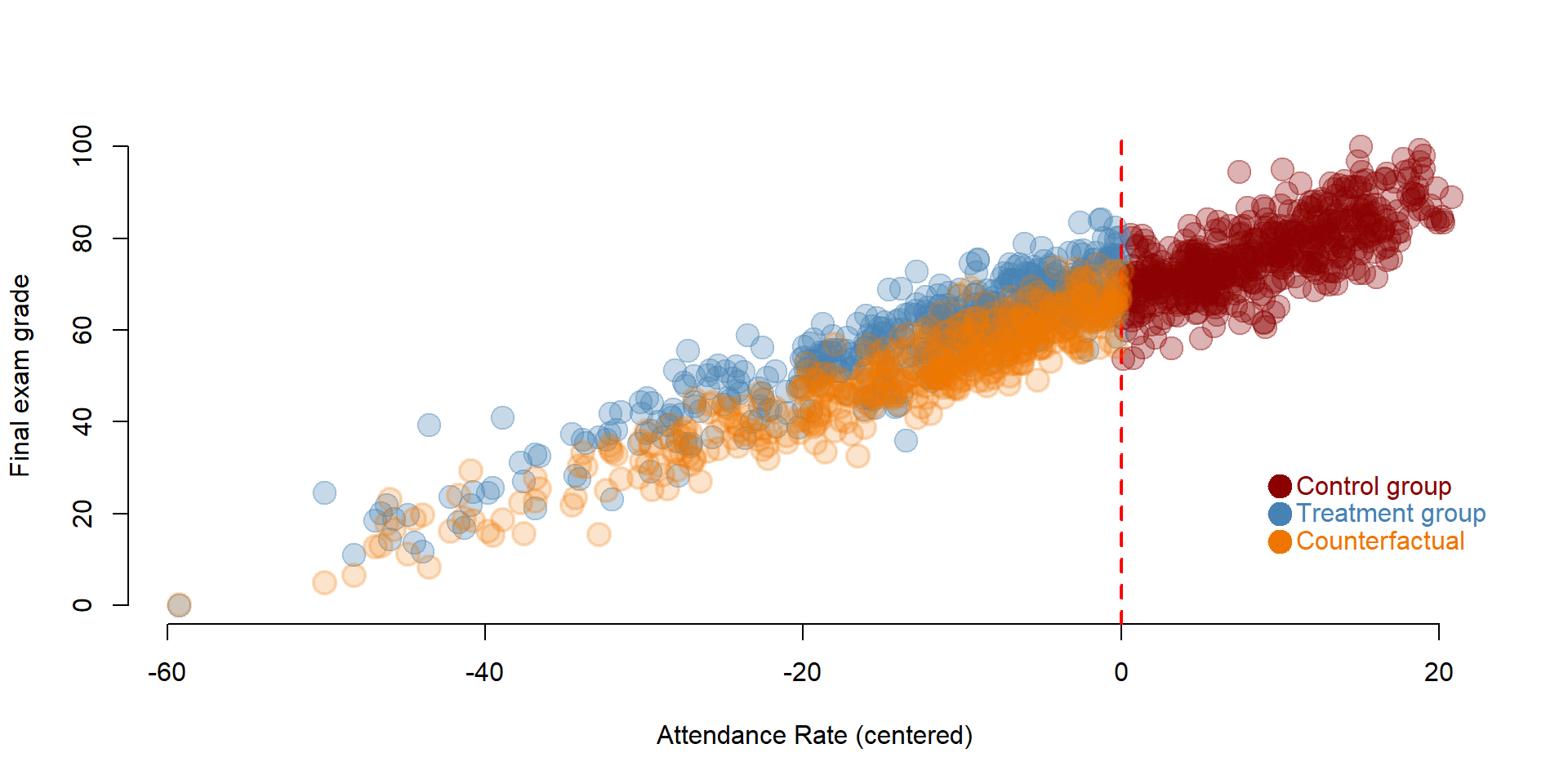
3 Replication of a study

We are going to replicate a study conducted by Carpenter and Dobkin (2009) on the effect of alcohol consumption on mortality rates. Statistics related to the effect of alcohol consumption are worrisome, from high mortality rates due to car accidents to health realted problems, especially among young adults.
Regression discontinuity is an appropriate design to study this issues as young adults are “naturally” selected in two groups based on their age: young adults who are below the age of 21 are not legally allowed to drink while young adults above the age of 21 are allowed to drink. We can compare the mortality rate between these two group.
Data are made available by Josh Angrist and Steve Pischke here: http://masteringmetrics.com/resources/.
Research question: Does alcohol consumption increase mortality rate?
Hypothesis: Young adults who consume alcohol have a higher mortality rate.
URL <- "https://raw.githubusercontent.com/DS4PS/pe4ps-textbook/master/data/RegDisc2.csv"
data <- read.csv( URL, stringsAsFactors=F )3.1 Data
We can have a look at the first 10 rows of the data and summary statistics for the variables included.
head( data ) %>% pander()| agecell | all | alcohol | homicide | suicide | mva | drugs | externalother |
|---|---|---|---|---|---|---|---|
| 19.07 | 92.83 | 0.6391 | 16.32 | 11.2 | 35.83 | 3.872 | 8.534 |
| 19.15 | 95.1 | 0.6774 | 16.86 | 12.19 | 35.64 | 3.237 | 8.656 |
| 19.23 | 92.14 | 0.8664 | 15.22 | 11.72 | 34.21 | 3.202 | 8.514 |
| 19.32 | 88.43 | 0.8673 | 16.74 | 11.28 | 32.28 | 3.281 | 8.258 |
| 19.4 | 88.7 | 1.019 | 14.95 | 10.98 | 32.65 | 3.548 | 8.418 |
| 19.48 | 90.19 | 1.171 | 15.64 | 12.17 | 32.72 | 3.212 | 7.973 |
Variables include:
| Variable name | Description |
|---|---|
| agecell | Age of individual (the study focuses on adults between 19-22 year) |
| all | Overall mortality rate |
| alcohol | Mortality rate for alcohol-related causes |
| homicide | Mortality rate for homicides |
| suicide | Mortality rate for suicide |
| mva | Mortality rate for car accidents |
| drugs | Mortality rate for drug-related causes (alcohol excluded) |
| externalother | Mortality rate for other external causes |
stargazer( data,
type = "html",
omit.summary.stat = c("p25", "p75"),
digits = 2 )| Statistic | N | Mean | St. Dev. | Min | Max |
| agecell | 50 | 21.00 | 1.13 | 19.07 | 22.93 |
| all | 48 | 95.67 | 3.83 | 88.43 | 105.27 |
| alcohol | 48 | 1.26 | 0.35 | 0.64 | 2.52 |
| homicide | 48 | 16.91 | 0.73 | 14.95 | 18.41 |
| suicide | 48 | 12.35 | 1.06 | 10.89 | 14.83 |
| mva | 48 | 31.62 | 2.38 | 26.86 | 36.39 |
| drugs | 48 | 4.25 | 0.62 | 3.20 | 5.56 |
| externalother | 48 | 9.60 | 0.75 | 7.97 | 11.48 |
Before running our model we need to create two variables. One variable indicating young adults over than 21 (=1) and younger than 21 (=0). A second variable indicating the centered rating score, which in this case is age.
# First we create a dummy Treatment variable, where individuals older than 21 are = 1 and younger than 21 = 0
data$Treatment <- ifelse( data$agecell > 21, 1, 0 )
# Second we create a centered age variable, which will be the rating variable in our model.
data$age_c <- data$agecell - 21
stargazer( data,
type = "html",
omit.summary.stat = c("p25", "p75"),
keep = c("Treatment", "age_c"),
digits = 2 )| Statistic | N | Mean | St. Dev. | Min | Max |
| Treatment | 50 | 0.48 | 0.50 | 0 | 1 |
| age_c | 50 | -0.0000 | 1.13 | -1.93 | 1.93 |
3.2 Analysis
We specify the model based on the equation (1.1). We estimate the effect of alcohol consumption on four outcomes: mortality rate for all causes, car accidents, alcohol-related causes, and drug-related causes.
reg1 <- lm( all ~ Treatment + age_c, data = data )
reg2 <- lm( mva ~ Treatment + age_c, data = data )
reg3 <- lm( alcohol ~ Treatment + age_c, data = data )
reg4 <- lm( drugs ~ Treatment + age_c, data = data )
stargazer( reg1, reg2, reg3, reg4,
type = "html",
dep.var.labels = c("All causes", "Car accidents",
"Alcohol", "Drugs"),
column.labels = "",
covariate.labels = c("Treatment", "Age"),
omit.stat = "all",
digits = 3 )| Dependent variable: | ||||
| All causes | Car accidents | Alcohol | Drugs | |
| (1) | (2) | (3) | (4) | |
| Treatment | 7.663*** | 4.534*** | 0.442*** | 0.218 |
| (1.440) | (0.768) | (0.157) | (0.181) | |
| Age | -0.975 | -3.149*** | 0.004 | 0.378*** |
| (0.632) | (0.337) | (0.069) | (0.080) | |
| Constant | 91.841*** | 29.356*** | 1.036*** | 4.141*** |
| (0.805) | (0.429) | (0.088) | (0.101) | |
| Note: | p<0.1; p<0.05; p<0.01 | |||
We interpret the results based on our question and hypothesis: does alcohol consumption increase mortality rate?
- In three models we observe a significant and positive difference between the control and treatment group.
- The Treatment coefficient is significant in the first model, showing that young adults who consume alcohol have a higher mortality rate compared to young adults below the drinking age.
- The Treatment coefficient is significant in the second model, showing that young adults who consume alcohol have a higher mortality rate for car accidents compared to young adults below the drinking age.
- The Treatment coefficient is significant in the third model, showing that young adults who consume alcohol have a higher mortality rate for alcohol-related causes compared to young adults below the drinking age.
- The Treatment coefficient is not significant in the fourth model, showing that young adults who consume alcohol do not have a higher mortality rate for drug-related causes compared to young adults below the drinking age.
3.3 Plotting results
As before we can plot the results on a graph, so that we can visualize the discontinuity. We plot results car accidents model.
# We first predict the final exam grades based on our regression discontinuity model.
predfit <- predict( reg2, data )
# We set colors for the graph
palette( c( adjustcolor( "steelblue", alpha.f=1 ),
adjustcolor( "darkred", alpha.f=1) ) )
# To differently color the treatment and control group
# we need to create a new Treatment variable that where the Control group = 2.
data$Treatment2 <- ifelse(data$Treatment==0,2,1)
# Plot our observed value
plot(data$age_c, data$mva, col=data$Treatment2, pch=19, bty="n",
xlab="Age (centered)", ylab="Car accidents", cex=2)
# Plot a line at the cutoff point
abline( v=0, col="red", lwd=2, lty=2 )
# Plot our predicted values
points( data$age_c, predfit, col="black", lwd=5, pch = 20 )
## Add a legend
points( 1.5, 36, col="steelblue", pch=19, cex=2 )
text( 1.5, 36, "Treatment group", col="steelblue", pos=4 )
points( 1.5, 33, col="darkred", pch=19, cex=2 )
text( 1.5, 33, "Control group", col="darkred", pos=4 )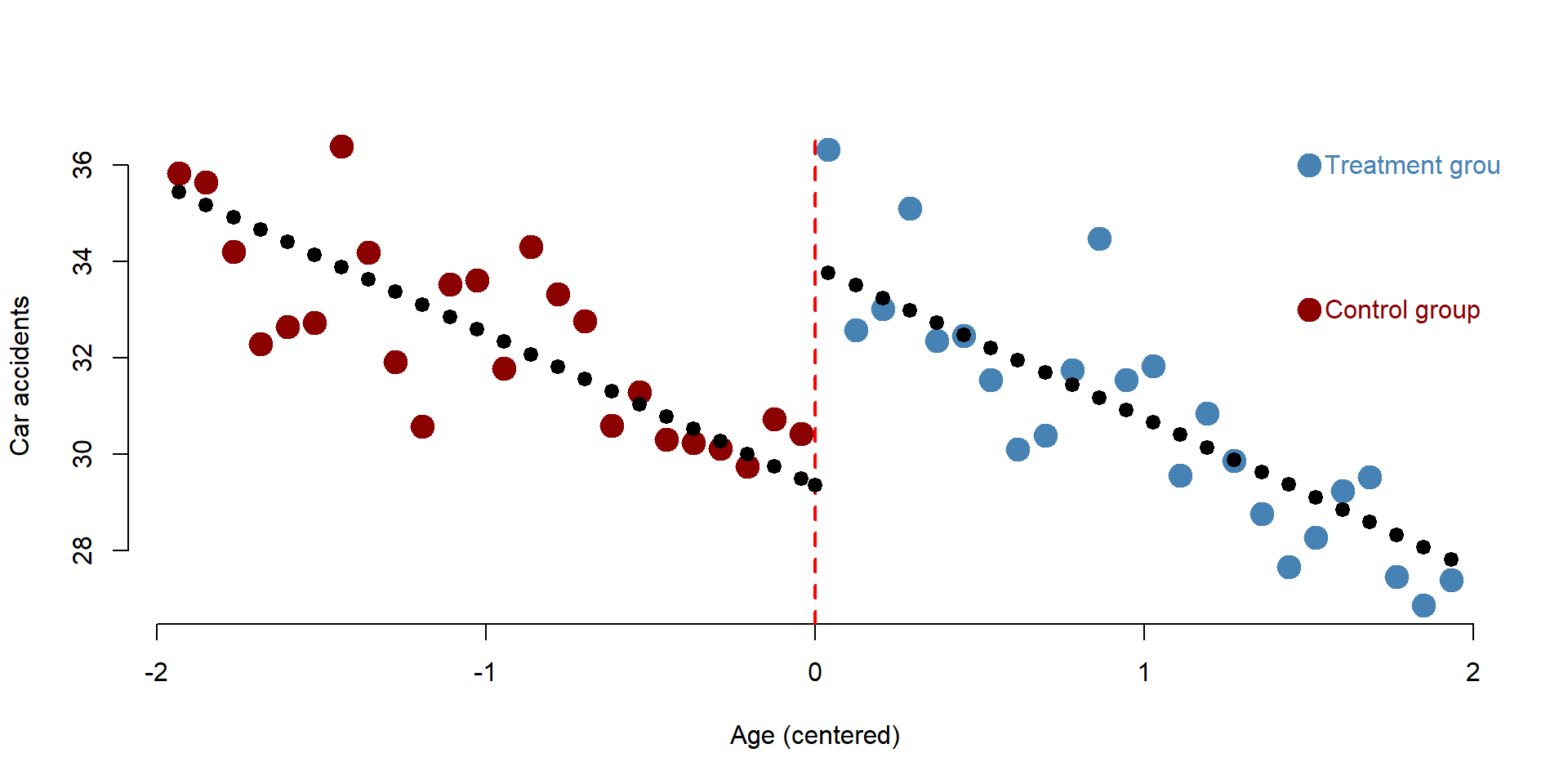
4 Additional notes
There are two main threats to validity in a regression discontinuity design.
First, we assumed that the the relationship between the rating variable and the outcome variable is linear.
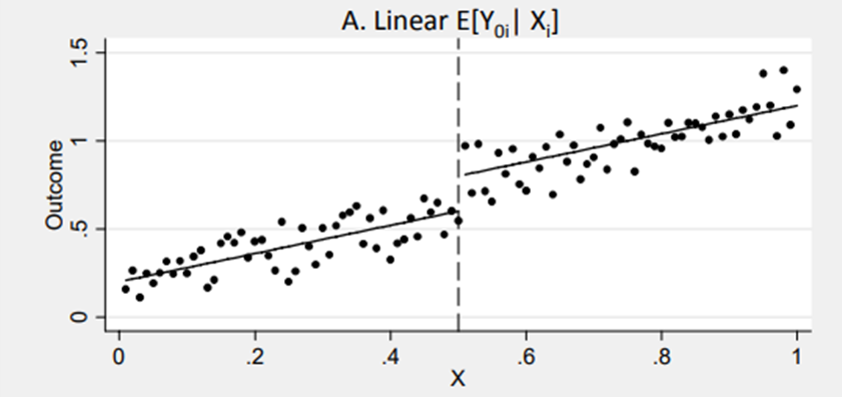
Figure 4.1: Source: http://econ.lse.ac.uk/staff/spischke/mhe/ex_ch6.pdf
Yet this assumption might not be met. It might happen that the relationship between the rating and the outcome variable is non linear. If this is case you need to properly model it in your formula. For instance, you might need to include quadratic term or more complex polymers if the relationship is curvilinear.
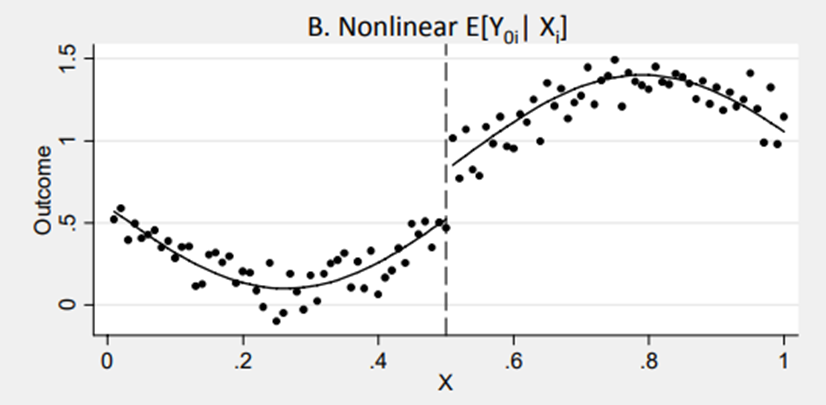
Figure 4.2: Source: http://econ.lse.ac.uk/staff/spischke/mhe/ex_ch6.pdf
It could also happen that once a nonlinear relationship is modelled correctly, the “discontinuity” disappears as it was caused by a misspecification in the model. You can see this case in figure 4.3. The correct relationship is specified by the curve. But if we model it as a linear relationship, we might observe a discontinity that is not in the data.
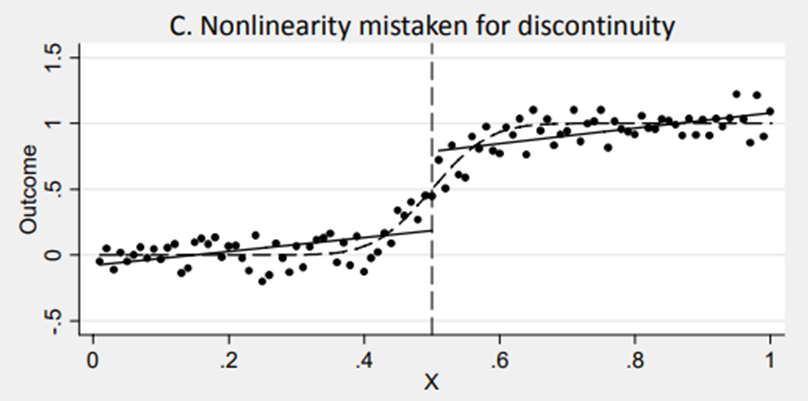
Figure 4.3: Source: http://econ.lse.ac.uk/staff/spischke/mhe/ex_ch6.pdf
The second threat is the diffusion of the treatment.
Regression discontinuity assumes that all individuals below (or above) the cutoff point received the treatment and none of the individuals above (or below) the cutoff received it. This might occur in some cases where the rating variable deterministically defines who receives the treatment and who does not (e.g., programs based on income).
However, in some circumstances the treatment and the control group might be contaminated. For instance, despite the mandatory attendance policy some students might have decided not to regularly attend classes. When enforcing a law at the international level, some countries might not implement it right away, despite being eligible. In some other cases, individuals below (or above) the cutoff might be allowed to attend special classes or programs.
Contamination of the control group or crossovers of the treatment group might affect the estimation of the main effect. In this case, the regression discontinuity is defined as “fuzzy” as the cut off is not deterministic but probabilistic (we assume that individuals who should receive the treatment are actually receiving it and viceversa). To solve the problem, you can:
- acknowledge possible issues related to contamination and crossover but still run your regression discontinuity comparing eligible vs ineligible individuals
- use eligibility as an instrumental variable. First you estimate you receive the treatment and then use regression discontinuity to estimate the treatment on the treated.
5 Additional resources
Additional resources are made available to help you to explore more advanced topics. In some cases, additional resources might also help you to better understand the topic by reading additional explanations and examples.
Additional slides on regression discontinuity can be found here, here or here.
Little explanation, but nice graphs: here.
More on nonlinear relationships and fuzzy regression discontinuity.
A complete guide to regression discontinuity for practitioners