** Course Overview
*** { @unit = “”, @title = “Instructor Introduction”, @lecture, @foldout }
*** { @unit = “”, @title = “Course Motivation”, @lecture, @foldout }
*** { @unit = “”, @title = “Syllabus and Course Structure”, @lecture, @foldout }
*** { @unit = “”, @title = “Community Analytics”, @reading, @foldout }
Neighborhoods Matter
Hundreds of studies have demonstrated that the odds of economic success vary across neighborhoods. The far more difficult question is whether that’s because neighborhoods nurture success (or failure), or whether they just attract those who would succeed (or fail) anyway.
Urban policy scholars have long made the case for the primacy of place:
Ellen, I. G., & Turner, M. A. (1997). Does neighborhood matter? Assessing recent evidence. Housing Policy Debate, 8(4), 833-866. [ pdf ]
Economists have more recently come to the conclusion that neighborhoods matter more than they expected. For example, see Justin Wolfers: Why the New Research on Mobility Matters: An Economist’s View; The New York Times, May 4, 2015. [ link ] [ pdf ]
There is growing evidence that neighborhoods can be used as a treatment to aid in social mobility, i.e. that programs which help low-income families move to stable and thriving neighborhoods have significant long-term impact on the mobility of the kids. See the Moving to Opportunity Study { Part 1 } and { Part 2 }.
The Quality of Neighborhoods Varies Significantly
The report shows how America’s yawning inequality extends beyond just money to wide discrepancies in health, knowledge and education, too. As Stanford economist Rebecca Diamond has suggested, inequality of well-being compounds earnings inequality. Her research finds that more well-off and high-skilled Americans accrue additional benefits from living in neighborhoods with better schools, less crime and enhanced public services. Meanwhile, the less skilled and moneyed Americans are shunted off to communities with low quality schools and services. America’s economic divide registers not just in what we can afford to buy, but in the education we have the opportunity to attain and, most basically, in how much time we have to live.
The Geography of Well-Being, CITYLAB, Richard Florida, APR 23, 2015 [ link ]
A Theory of Neighborhood Change
Neighborhoods don’t start out bad. They typically begin as vibrant middle-class developments that pass through various life-cycles over time. Why do some neighborhoods remain stable and thriving, and others experience drastic decline and stagnation? Theories of neighborhod change have been developed to answer that question.
Pitkin, B. (2001). Theories of neighborhood change: Implications for community development policy and practice. UCLA Advanced Policy Institute, 28. [ pdf ]
Data-Driven Approaches to Studying Neighborhoods
Data can help us better understand the impact that neighborhoods have on residents. This class will help you develop a framework around community analytics - using data science tools to identify and describe neighborhoods in cities, and predict how they might change over time.
We will specifically draw upon approaches described in:
Firschein, J. (2015). Putting data to work: data-driven approaches to strengthening neighborhoods. IFC Bulletins chapters, 38. Market Value Analysis: A Data-Based Approach to Understanding Urban Housing Markets, pp 41-60. [ pdf ]
Some data-driven models that help predict which neighborhoods are most likely to change over time.
And recent academic work that uses census data and machine learning to identify patterns in community development:
Delmelle, E. C. (2017). Differentiating pathways of neighborhood change in 50 US metropolitan areas. Environment and planning A, 49(10), 2402-2424. [ pdf ]
All three articles share a common approach of using census data and clustering techniques to classify neighborhoods by type, then examine how each type is likely to change over time.
![]()
** Week 1 - Measurement & The Theory of Neighborhoods
*** { @unit = “”, @title = “Unit Overview”, @reading, @foldout }
Description
This section introduces the field of measurement theory in psychology and social sciences, which is used to create scales or indices that allow us to observe and document things that are not easy to measure.
Many variables studied by psychologists are straightforward and simple to measure. These include sex, age, height, weight, and birth order. You can often tell whether someone is male or female just by looking. You can ask people how old they are and be reasonably sure that they know and will tell you. Although people might not know or want to tell you how much they weigh, you can have them step onto a bathroom scale. Other variables studied by psychologists—perhaps the majority—are not so straightforward or simple to measure. We cannot accurately assess people’s level of intelligence by looking at them, and we certainly cannot put their self-esteem on a bathroom scale. These kinds of variables are called latent CONSTRUCTS (pronounced CON-structs) and include personality traits (e.g., extraversion), emotional states (e.g., fear), attitudes (e.g., toward taxes), and abilities (e.g., athleticism). [ Understanding Psychological Measurement ]
We are less interested in psychological measures as in constructs of neighborhood quality. But we will use some of the tools developed in psychometrics to help us develop a reliable measure of neighborhood quality.
Learning Objectives
Once you have completed this section you will be able to:
- Define a construct
- Operationalize measurement reliability
- List theories of neighborhood change
- Begin to develop reliable measures of neighborhood quality
Assigned Reading
REQUIRED:
Schäffer, U. (2007). Management accounting & control scales handbook. Springer Science & Business Media. [ 2-page PDF ]
Pitkin, B. (2001). Theories of neighborhood change: Implications for community development policy and practice. UCLA Advanced Policy Institute, 28. [ pdf ]
FOR REFERENCE:
Impact of Neighborhoods on Families
Ellen, I. G., & Turner, M. A. (1997). Does neighborhood matter? Assessing recent evidence. Housing Policy Debate, 8(4), 833-866. [ pdf ]
Measurement Theory
Measurement Theory and Practice, from: Smith, F. (2002). Research methods in pharmacy practice. Pharmaceutical Press. [ pdf ]
Schäffer, U. (2007). Management accounting & control scales handbook. Springer Science & Business Media. [ full text ]
MacKenzie, S. B., Podsakoff, P. M., & Podsakoff, N. P. (2011). Construct measurement and validation procedures in MIS and behavioral research: Integrating new and existing techniques. MIS quarterly, 35(2), 293-334. [ pdf ]
*** { @unit = “”, @title = “Measurement”, @lecture, @foldout }
On your lab you will be practicing with index development using census data and the following app:
https://jdlecy.shinyapps.io/measurement-lab/#section-warmup
*** { @unit = “Due Oct 23nd”, @title = “Lab 01”, @assignment, @foldout }
Brief Video Instruction
Lab-01 - Measurement
Submit Solutions to Canvas:
** Week 2 - Intro to Census Data and Mapping
*** { @unit = “”, @title = “Unit Overview”, @reading, @foldout }
Description
This unit will focus on covering two exciting data science topics: (1) Working with Census Data; and (2) Creating choropleth (i.e. color-coded) maps. The U.S. Census Bureau is the premier source of data about US people, places and economy, making the Bureau a natural source of information for data analysts.
In general, data scientists using R often run into two problems related to this topic. First, it can be extremely challenging to understand and find what are the actual data that the Census Bureau publishes. Second, it can also be challenging to understand what packages in R can be used to efficiently analyze census data.
This unit will teach students how to resolve both problems, as well as learn mapping tools to effectively transform raw census data into visually appealing choropleth (i.e. color-coded) maps. This unit includes 4 videos: (1) introduction to Census and Census data; (2) Introduction to Mapping; (3) Mapping Census Data in R; and (4) Mapping Census Data in R with TidyCensus.
The lecture notes accompanying the videos can be found at the following links: HTML
Assigned Reading
REQUIRED:
Florida, R. (2018). Where the House-Price-to-Income Ratio Is Most Out of Whack. Citylab report
*** { @unit = “”, @title = “Introduction to Census Data”, @lecture, @foldout }
*** { @unit = “”, @title = “Introduction to Mapping”, @lecture, @foldout }
*** { @unit = “”, @title = “Mapping Census Data in R”, @lecture, @foldout }
*** { @unit = “”, @title = “Mapping Census Data in R w/ TidyCensus”, @lecture, @foldout }
*** { @unit = “Due Oct 30th”, @title = “Discussion Assignment: How local governments ensure an accurate census”, @assignment, @foldout }
Every 10 years, the U.S. Census Bureau conducts a census to determine the number of people living in the United States.
The data collected by the decennial census are used to determine the number of seats each state has in the U.S. House of Representatives as well as used to inform federal spending and other important federal and state functions. The task of the census is simple to state yet difficult to execute: count everyone once (no undercount), only once (no overcount), and in the right place (no location errors).
ASSIGNMENT:
For your discussion topic this week, please read and provide general reflection based on the following two articles article 1 and article 2. Discuss also what are some of the challenges faced and new innovations adopted by federal and state governments to ensure an accurate census.
Please post your reflection as a new pin on YellowDig.
*** { @unit = “Due Oct 30th”, @title = “Lab 02”, @assignment, @foldout }
Brief Video Instruction
Lab Instructions
Please download the Rmarkdown file (.RMD) below. In steps 1-4, you can input your R code chunk in the areas that say #edit me. In Questions 1-3, you can simply answer the questions (i.e. you do not need to show or include any additional code needed to answer the questions).
Access Lab 2 here: RMD
Please submit both the .RMD file and .Html file.
Submit Solutions to Canvas:
—————————————————————————————————
** Week 3 - Identifying Neighborhood Types with Cluster Analysis
*** { @unit = “”, @title = “Unit Overview”, @foldout }
Description
In this unit, we will be learning how to implement cluster analysis in R as a data reduction technique. We will classify census tracts in the Pheonix area into group (or neighborhoods) that can be defined on the basis of certain characteristics. Before we get into the application portion of this unit, it is important to first understand what is cluster analysis and what are some common methods and applications.
Assigned Reading
Required:
Temkin, K., & Rohe, W. (1996). Neighborhood change and urban policy. Journal of planning education and research, 15(3), 159-170. [ pdf ]
Grigsby, W., Baratz, M., Galster, G., & Maclennan, D. (1987). The dynamic of neighborhood change and decline. Progress in Planning, 28, 1. [ pdf ]
Schwirian, K. P. (1983). Models of neighborhood change. Annual review of Sociology, 9(1), 83-102. [ pdf ]
*** { @unit = “”, @title = “Cluster Analysis: Overview”, @lecture, @foldout }
The first video below introduces cluster analysis and a simple partitioning algorithm used to segment data into specific partitions or groups. The second video below introduces other popular clustering methods – Hierarchical and model-based clustering. Model-based clustering is the method we will use in R with the MClust package. The lecture notes can be found here (PPT).
*** { @unit = “Due Nov 6th”, @title = “Lab 03”, @assignment, @foldout }
Overview
The purpose of Lab 3 is to show you how to apply model-based clustering to classify Phoenix neighborhoods into meaningful groups. Lab 3 is a code-through only and will not require you to modify any code as was the case in Lab 2.
Lab Instructions
You may access Lab 3 instructions by clicking on the LAB-03 Instructions below. First view the instructions and see some of the code chunks and output that you will create yourself. Next, download the Rmardown file (RMD) and execute each code chunk step-by-step to understand each stage of the process.
Reminder: Name your files according to the convention: Lab-##-LastName.xxx
After you have completed Lab 3 you can submit it via Canvas using the link below. Upload your RMD and your HTML files to the appropriate lab submission link.
Submit Solutions to Canvas:
*** { @unit = “Due Nov 6th”, @title = “Yellowdig Discussion Assignment: Labeling Phoenix Neighborhood Groups”, @assignment, @foldout }
Nice job! You have successfully completed lab assignment 3 that relies on a host of census variables and employs model-based clustering (mclust) to group Phoenix neighborhoods into 8 unique categories. You are now ready for the fun part – giving a label for each neighborhood grouping that adequately represents that particular grouping. To do this, you need to visually inspect carefully how the census varaibles relate to each neighborhood group and make an informed opinion about what type of label to apply.
ASSIGNMENT:
For your discussion topic this week, you will propose labels for Groups 1-8 constructed during Lab 3 using cluster analysis Image 1 below. In order to provide an appropriate label, you must do a careful inspection of how the census variables overall relate to a particular group Image 2. A good label will be catchy and descriptive of the population within the neighborhood cluster.
Please post your reflection as a new pin on YellowDig.
Image 1:
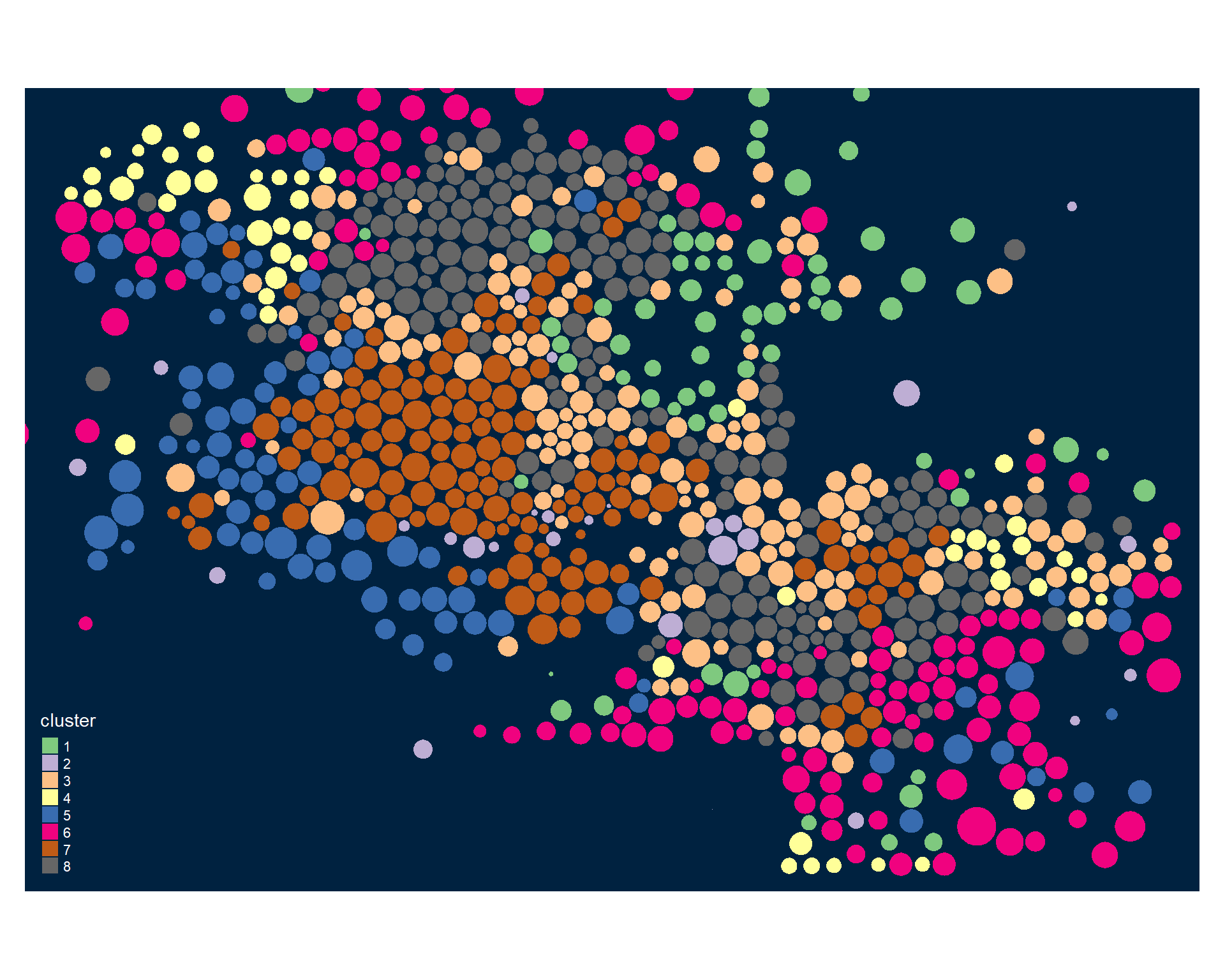
Image 2:

** Week 4 - More Practice Clustering
*** { @unit = “”, @title = “Unit Overview”, @reading, @foldout }
Description
Neighborhood change is a complicated concept with a lot of loaded terminology. We might think about neighborhoods that are “revitalized”, “gentrified”, that are “stable”, or that “decline”. We could spend an entire semester unpacking all of these constructs, but that is out of scope of the lab. Here we are more interested in how we might make sense of our data, and then once we have meaningful groups how we might use them to make predictions with the data. Can a city forecast how it’s current neighborhoods are likely to change over the next decade, and can that help with urban planning processes?
Assigned Reading
REQUIRED:
Market Value Analysis: A Data-Based Approach to Understanding Urban Housing Markets. pp 49-59 [ PDF ]
Delmelle, E. C. (2017). Differentiating pathways of neighborhood change in 50 US metropolitan areas. Environment and planning A, 49(10), 2402-2424. [ PDF ]
We are interesting in understanding neighborhood change. These data-driven approaches to the phenomenon use machine-learning algorithms to “discover” coherent communities within the city by grouping census tracks into groups that minimize within-group differences and maximize between-group differences.
You can explore one of these algorithms by looking at examples of how botanists might create “species” based upon characteristics of flowers:
A data-driven approach to understanding neighborhood change requires use to (1) define “neighborhoods”, or groups of census tracks in the data that are very similar, and (2) use those group characteristics at a point in time to predict how the “neighborhood” might change in the future. Both of the papers present variations on Step (1) above.
*** { @unit = “Due Nov 6th”, @title = “Reading Assignment”, @assignment, @foldout }
Read the two papers from Neighborhood Types section above (Links provided again here: ([ PDF 1 ]; [ PDF 2 ]), then answer the following questions:
- How did each author identify coherent “neighborhoods” (or groups) in each model?
- Would these “neighborhoods” line up with neighborhoods that are defined on a city’s zoning maps (Links to an external site.)?
- Did the two models use the same data to create the groups?
- How do the labels and descriptions of the groups differ in each model and why?
Please copy these questions, along with your answers, at the beginning of your .rmd file used for Lab 4 (See Lab 4 assignment below).
*** { @unit = “”, @title = “Geography and Economic Success”, @lecture, @foldout }
A new study by the Harvard economists Raj Chetty and Nathaniel Hendren, when read in combination with an important study they wrote with Lawrence Katz, makes the most compelling case to date that good neighborhoods nurture success… they are the most powerful demonstration yet that neighborhoods — their schools, community, neighbors, local amenities, economic opportunities and social norms — are a critical factor shaping your children’s outcomes. It’s an intuitive idea, although the earlier evidence for it had been surprisingly thin.
I discuss Chetty’s work in the video lecture below.
(Note: Audio begins at the 10 second mark.)
*** { @unit = “Due Nov 13th”, @title = “Lab 04”, @assignment, @foldout }
Overview
The purpose of Lab 4 is to replicate the work you did for the previous lab, but instead of using the Phoenix data you will select a city of your choice to use for this lab, and the final project.
Lab Instructions
You may access Lab 4 instructions by clicking on the LAB-04 Instructions below.
Reminder: Include the four questions, along with your answers from the reading assignment (see above) at the beginning of your RMD file.
Lab Instructions
Submit Solutions to Canvas:
** Week 5 - Visualizing Neighborhood Changes
*** { @unit = “”, @title = “Unit Overview”, @foldout }
Description
In this unit, a brief video introduction is given related to neighborhood change and gentficication, serving as important foundation for our data science work using census data to visualize changes in neighborhoods over time. The second goal of this unit is to offer a set of “good practices” when creating maps to display spatial information.
*** { @unit = “”, @title = “Neighborhood Change and Gentficication”, @lecture, @foldout }
The first video below provides a general overview of neighborhood change and gentrification, including: defintions, debates, policies, and a case study example. The lecture notes can be found here (PDF).
*** { @unit = “”, @title = “Visualization Recap”, @lecture, @foldout }
The video below describes the importance of creating maps that accurately conveys spatial information contained in the underlying data. Far too often, maps are used incorrectly to advocate a certain narrative that does not accurately reflect underlying data. As data scientists, it is important that we are careful of how we map spatial information. The lecture notes can be found here (PDF).
*** { @unit = “Due Nov 20th”, @title = “Lab 05”, @assignment, @foldout }
Lab Instructions
There are 3 parts to this week’s lab. The first two parts are largely a review and a primer of what we’ve done already and where we are heading. The Rmarkdown file and HTML file is below.
Access Parts 1 and 2 of Lab 5 here: RMD; HTML
After you go through Parts 1 and 2, please download part 3 of the lab, which focuses on using dot density maps to display changes in demographics, in this case with respect to education levels. There are several questions for you to consider at the bottom of the file that pertain to all parts of the lab. The Rmarkdown file and HTML file is below.
Access Part 3 Lab 2 here: RMD; HTML
Please submit your .rmd and .html files for Part 3 of the lab only, including your answers to the questions.
Submit Solutions to Canvas:
*** { @unit = “Due Nov 20th”, @title = “Yellowdig Discussion Assignment: Predicting Neighborhood Change”, @assignment, @foldout }
Required Readings
-
Using Algorithms To Predict Gentrification (Link)
-
How Machine Learning and AI Can Predict Gentrification (Link)
Questions
-
Provide a 2-3 sentence summary of the above two articles (research topic, data, method, findings).
-
What are the main variables used to predict gentrification in the above studies?
-
What other information would you like to have that you think would be an important predictor of gentrification?
** Week 6 - OLS Regression and Models of Neighborhood Change
*** { @unit = “”, @title = “Unit Overview”, @foldout }
Description
In this unit, a set of brief videos are provided to give an introduction and overview of employing model regressions in R. In the lab, we will then use regression analysis to explore how changes in certain demographic variables influence change in house prices over time.
The second theme of this unit is to continue working with cluster analysis to classify neighborhoods (at the tract or county level) into groups and provide appropriate labels for those groups based on how the demographic information relates to them. We will then extent our cluster analysis to predict clusters using the same set of demographic variables for a different time period, and then track how counties (or tracts) transition from one cluster grouping to another over time.
*** { @unit = “”, @title = “Regression Overview”, @lecture, @foldout }
This set of videos provide a general overview of Ordinary Least Squares (OLS) model regression. The lecture notes can be found here (HTML).
OLS Introduction
OLS Graphical Example
OLS Assumptions
Manual OLS with Matrix Algebra
OLS Example using Crime Data
*** { @unit = “Due Nov 27th”, @title = “Lab 06”, @assignment, @foldout }
Lab Instructions
This will be the last lab for the semester and will serve as the primary foundation for your final city project. There are two parts to the lab.
In the first part, you will download census information from the 2008-2012 ACS 5-year estimates and the 2013-2017 ACS 5-year estimates, calculate change over time for each variable, and then run OLS regression to explore how changes in demographic variables relate to changes in house prices at the county level.
In the second part, you will perform cluster analysis, as in previous labs, but this time grouping all US counties into unique groups based on variables from the 2013-2017 ACS 5-year estimates. As before, you will visualize how demographic information relates to each group and provide an appropriate label.
What’s new in this part 2 of the lab is that you will then combine the cluster model output performed for counties during the 2013-2017 period, and predict what cluster groups those counties would have been in during the 2008-2012 time period. Next, you will track transitions of counties from one cluster group to another over the 2008-2012 and 2013-2017 time period, and see how those changes relate to house prices. From here you will attempt to detect which cluster groups gentrified over the time period.
Access the lab here: RMD; HTML
Please submit your .rmd and .html files on Canvas, including your answers to the questions.
Submit Solutions to Canvas:
*** { @unit = “Due Nov 27th”, @title = “Yellowdig Discussion Assignment: Predicting Neighborhood Change”, @assignment, @foldout }
Required Readings
- Gentrification Has Virtually No Effect on Homeowners (Link)
Questions
-
Summarize the main debate about gentrification and what your stance is after reading the article.
-
How does the study by Martin and Beck define gentrification? What are the limits/advantages of using this definition?
-
How does our approach taken in the lab to identify potential clusters of counties that gentrified compare to Martin and Beck’s definition of gentrification? Is our approach better? What other variables should we like to include in our cluster anlaysis to better describe gentrified areas?
** Week 7 - Final Project
*** { @unit = “Due Dec 2nd”, @title = “Explainer Assignment”, @assignment, @foldout }
Code-Through
Submit to Canvas:
Post on Yellowdig
Publish your code-through as an RPub or shiny app. Share you link on YellowDig.
*** { @unit = “Due Dec 6th”, @title = “DASHBOARD”, @assignment, @foldout }
For the final project, you will extend the work you’ve done over the course of the semester by creating a dynamic dashboard that will be used to detect neighborhood change and gentrification at the census tract level for your metroplitan statistical area (MSA) of choice.
To this end, you will combine aspects into your final project from Lab 4 that focuses on your selected MSA to perform cluster analysis and create a dorling map of your 2010 cluster and Lab 6 (descriptives, regression, clustering, clustering prediction, and sankey charting).
The goal of your dynamic dashboard is to empower members of the City Council to better understand economic and demographic trends impacting the communities they govern.
As part of the final project, you will also record a video presentation of 15-20 minutes and give an oral presentation of your dynamic dashboard. Be sure to highlight your findings, and policy implications and recommendations. You may record the video presentation on your computer and then upload it to youtube.
Submission: You will submit the .rmd file, the .html file, and the link to your youtube video to Canvas.
Instructions
The skeleton for the final project using flex_dashboard can be downloaded here (LINK to FINAL PROJECT .RMD). The first thing you should do after downloading the file, is to open it and then knit it in order to make sure it compiles properly. If it does not, check that all R packages are updated.
You have two major coding tasks denoted as edit me in R chunks: (1) subset all census data from Lab 6 to your chosen MSA from Lab 4; and (2) merge spatial information from Lab 4 to census data from Lab 6.
In addition to the two coding task you must also describe your research project and interpret the results. Specifically, when viewing the knitted dashboard, you should notice latin placeholder text in some areas. The latin placeholder text is created using r lorem::ipsum(paragraphs = 1) that you can see in the .rmd file, followed by some instructions enclosed within notes () that are commented out.
You will need to delete each instance of r lorem::ipsum(paragraphs = 1) placeholder text in the .rmd file and provide your own answers based on the instructions contained within notes (). There are 11 instances of latin placeholder text that you need to remove and provide answers.
Once you have completed the final project, you should record a well-rehearsed presentation of 15-20 minutes targeting local government and community leaders. You may post the video on youtube. When uploading to youtube, you can select the unlisted option to keep the video from being found via search, rather it can only be viewed if you have the link.
Submission: You will submit the .rmd file, the .html file, and the link to your youtube video to Canvas.
Submit Solutions to Canvas: