Forecasting Gentrification
Ken Streif at Urban Spatial has introduced an interesting predictive model that cities can adopt to anticipate development intensity and gentrification patterns.
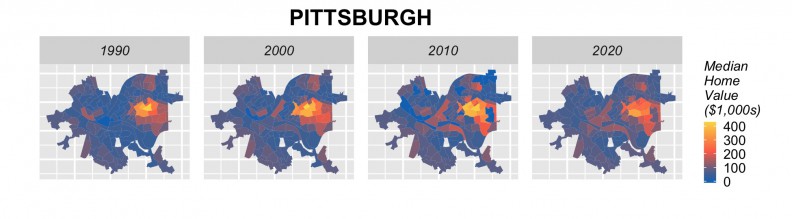
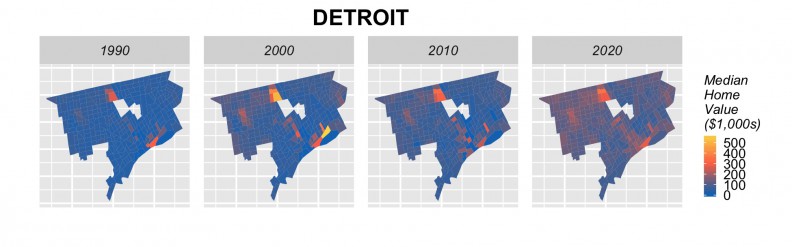
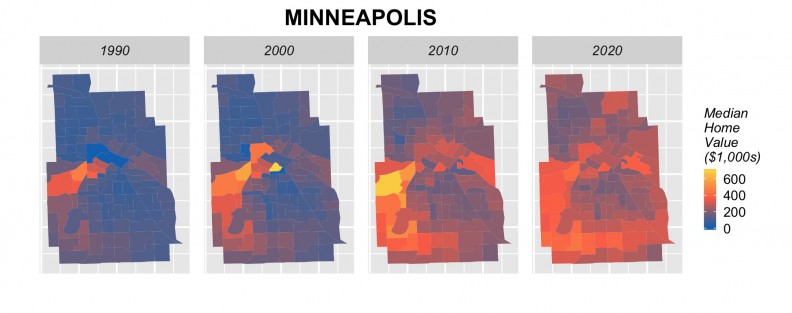
Tract-level forecasts in 3 cities
In their own words:
Our major methodological contribution is the adoption of endogenous gentrification theory in the development of spatial features that are effective for predicting prices in a machine learning context without overfitting.
Our training models use 1990 and 2000 data to predict for 2010 yielding an average prediction error of just 14% across all tracts. When this error is considered on a city-by-city basis, the median error is around 8%. It is important to note that our endogenous feature approach does not overfit the model.
We think these results are admirable given the limitations of our time series; that our unit of analysis, census tracts, rarely if ever conform to true real estate submarkets and that neighborhood decline is still the predominate dynamics in these Legacy Cities.
These algorithms and technological innovations such as the information system described above, can play a pivotal role in how community stakeholders allocate their limited resources across space.
