Review Sessions
Live review sessions will be held each week in order to:
- Discuss solutions to labs from the previous week
- Introduce new topics
- Answer questions on the the current week’s lab
Wednesdays
4pm AZ time
Add to your calendar:

To make the best use of sessions I recommend starting labs ahead of time so that you can come with questions.
For those that cannot attend recordings of each session will be posted below.
Feel free to schedule virtual office hours as well.
Week 1 - Wed Aug 26

Passcode: ?wsk2Xx1
SAMPLE CODE
SESSION CODE
Week 2 - Wed Sept 2
Passcode: ?#7z@Hwq
SAMPLE CODE
SESSION CODE

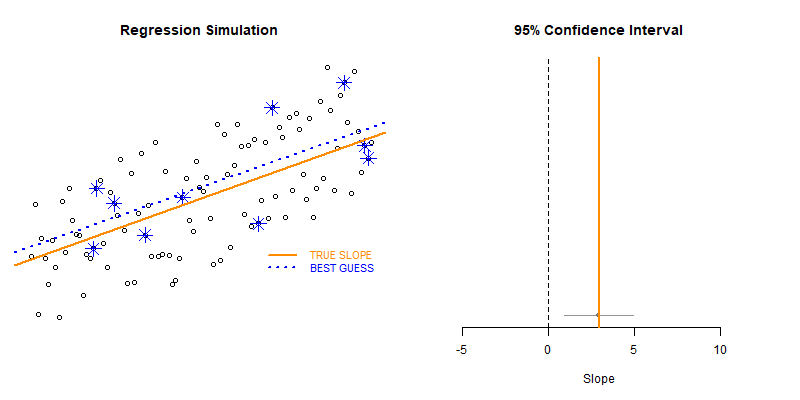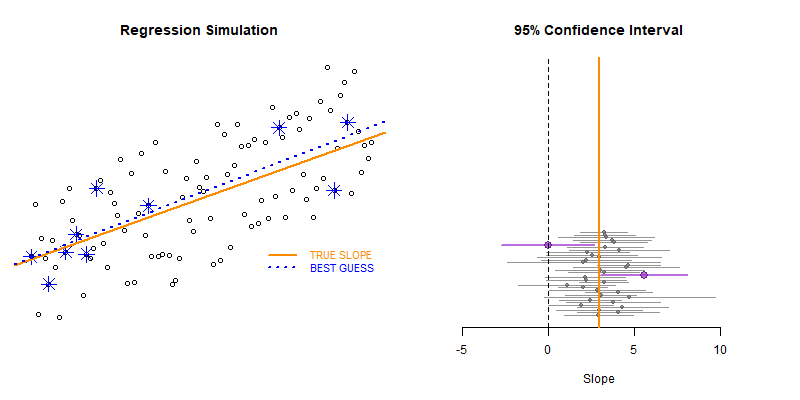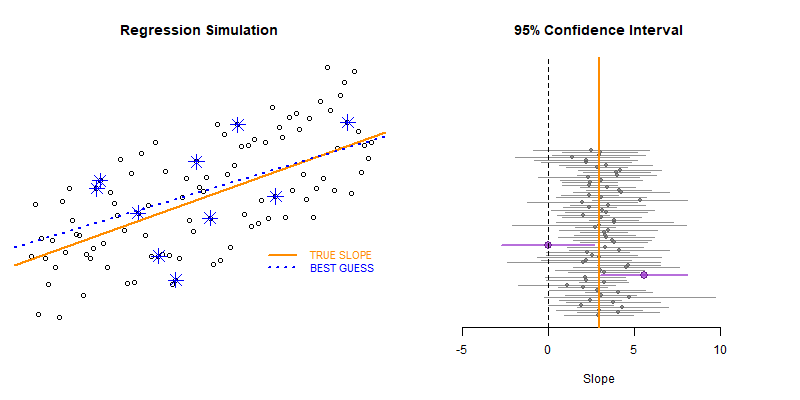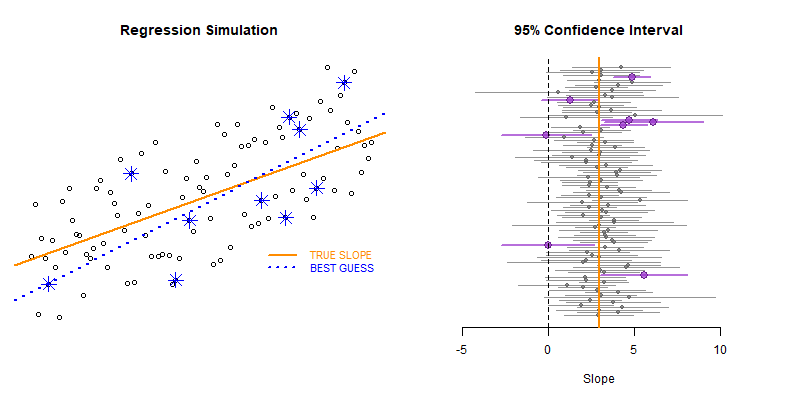
# BOOTSTRAPPING TYPE II ERRORS
# Examine Type II Errors
# as a function of sample size
# load data and helper functions
source( "https://raw.githubusercontent.com/DS4PS/cpp-527-fall-2020/master/lectures/loop-example.R" )
head( d ) # data frame with X and Y
get_sample_slope( d, n=10 ) # returns a single value
test_for_null_slope( d, n=10 ) # returns a one-row data frame
## EXAMINE SLOPES
## sample size = 10
slopes <- NULL # collector vector
for( i in 1:1000 ) # iterator i
{
b1 <- get_sample_slope( d, n=10 )
slopes[ i ] <- b1
}
# descriptives from 10,000 random draws, sample size 10
head( slopes )
[1] 2.246041 3.979462 1.714822 4.689032 1.763237 3.107451
summary( slopes )
# Min. 1st Qu. Median Mean 3rd Qu. Max.
# -2.194 1.596 2.176 2.088 2.600 4.868
summary( slopes )
# Min. 1st Qu. Median Mean 3rd Qu. Max.
# -2.194 1.596 2.176 2.088 2.600 4.868
hist( slopes, breaks=25, col="gray20", border="white" )
## EXAMINE CONFIDENCE INTERVALS
## sample size = 10
# build the
# results data frame
# using row binding
results <- NULL
for( i in 1:50 )
{
null.slope.test <- test_for_null_slope( d, n=10 )
results <- rbind( results, null.slope.test )
}
head( results )
# confidence intervals from 50 draws, sample size 10
# b1 ci.b1.lower ci.b1.upper null.slope
# x -0.9783359 -4.5757086 2.619037 TRUE
# x1 2.3897431 0.4295063 4.349980 FALSE
# x2 2.0781628 -0.6677106 4.824036 TRUE
# x3 2.9178206 0.7080918 5.127549 FALSE
# x4 2.3702949 0.5238930 4.216697 FALSE
# x5 1.9701996 0.5513491 3.389050 FALSE
plot_ci( df=results )
Week 3
Passcode: aAtw83!V
SAMPLE CODE
SESSION CODE
### REGULAR EXPRESSION EXAMPLES
strings <- c("^ab", "ab", "abc", "abd", "abe", "ab 12", "ab$")
# match anything that starts with ab followed by any character
grep("ab.", strings, value = TRUE)
# search for abc OR abd
grep("abc|abd", strings, value = TRUE)
# match abc OR abd OR abe
grep("ab[c-e]", strings, value = TRUE)
# match anything that is NOT abc
grep("ab[^c]", strings, value = TRUE)
# match any string where ab occurs at the beginning
grep("^ab", strings, value = TRUE)
# match any string where ab occurs at the end
grep("ab$", strings, value = TRUE)
# search for matches that contain the character ^
grep("^", strings, value = TRUE)
# try again
grep("\\^", strings, value = TRUE)
Week 4
Passcode: iTU78!JC
SAMPLE CODE
SESSION CODE
######################################
###
### TITLE DATA
###
######################################
URL <- "https://raw.githubusercontent.com/DS4PS/cpp-527-fall-2020/master/labs/data/medium-data-utf8-v2.csv"
d <- read.csv( URL )
# replace weird spaces with regular spaces
d$title <- gsub( " ", " ", d$title )
d$title <- gsub( "\\s", " ", d$title )
# note the use of single-quote marks since double-quotes appear in the text
d$title <- gsub( '<strong class=\"markup--strong markup--h3-strong\">', "", d$title )
d$title <- gsub( '</strong>', "", d$title )
# must use double-escape in front of the plus sign
# since it is an operator in reg-ex
# <U+200A>—<U+200A>
d$title <- gsub( "<U\\+200A>—<U\\+200A>", "", d$title )
######################################
###
### WORKING WITH LISTS
###
######################################
titles <- tolower( d$title ) # convert to lower case
titles <- gsub( "[0-9]", "", titles ) # remove numbers
words <- strsplit( titles, " " )
head( titles )
head( words )
length( titles ) == length( words )
one.sentence <- words[[1]]
first.word <- one.sentence[1]
last.word <- one.sentence[ length(one.sentence) ]
one.sentence <- words[[2]]
first.word <- one.sentence[1]
last.word <- one.sentence[ length(one.sentence) ]
one.sentence <- words[[3]]
first.word <- one.sentence[1]
last.word <- one.sentence[ length(one.sentence) ]
######################################
###
### COUNT WORDS (SENTENCE LENGTH)
###
######################################
# LOOP VERSION
results <- NULL
for( i in 1:length(words) )
{
# extract vector from list position i
one.sentence <- words[[i]]
# analysis with one sentence at a time
num.words <- length( one.sentence )
# save results
results[i] <- num.words
}
# APPLY VERSIONS
apply( list, function )
results <- lapply( words, length )
results <- unlist( results )
results <- sapply( words, length )
####################################
###
### GET FIRST AND LAST WORDS
###
####################################
results <- NULL
for( i in 1:length(words) )
{
# extract vector from list position i
one.sentence <- words[[i]]
# analysis with one sentence at a time
first.word <- one.sentence[1]
# save results
results[i] <- first.word
}
# CUSTOM FUNCTIONS
get_first_word <- function( x )
{
first.word <- x[1]
return( first.word )
}
get_last_word <- function( x )
{
last.word <- x[ length(x) ]
return( last.word )
}
one.sentence <- words[[2]]
get_first_word( one.sentence )
get_last_word( one.sentence )
results <- sapply( words, get_last_word )
Week 5
Useful Vocabulary:
- GitHub Pages
- “static” pages
- jekyll framework (coded with ruby)
- can use liquid tags
- Basic HTML Page Elements
- head.html
- header.html
- body
- footer.html
- Style Elements
- Cascading Style Sheets (CSS)
- Templates
Week 6
Passcode:
SAMPLE CODE
SESSION CODE