1 VECTORS AND DATA TYPES
Vectors are the building blocks of data programming in R, so they are extremely important concepts.
This section will cover basic principles of working with vectors in the R language, including the different types of vectors (data types or “classes”), and common functions used on vectors.
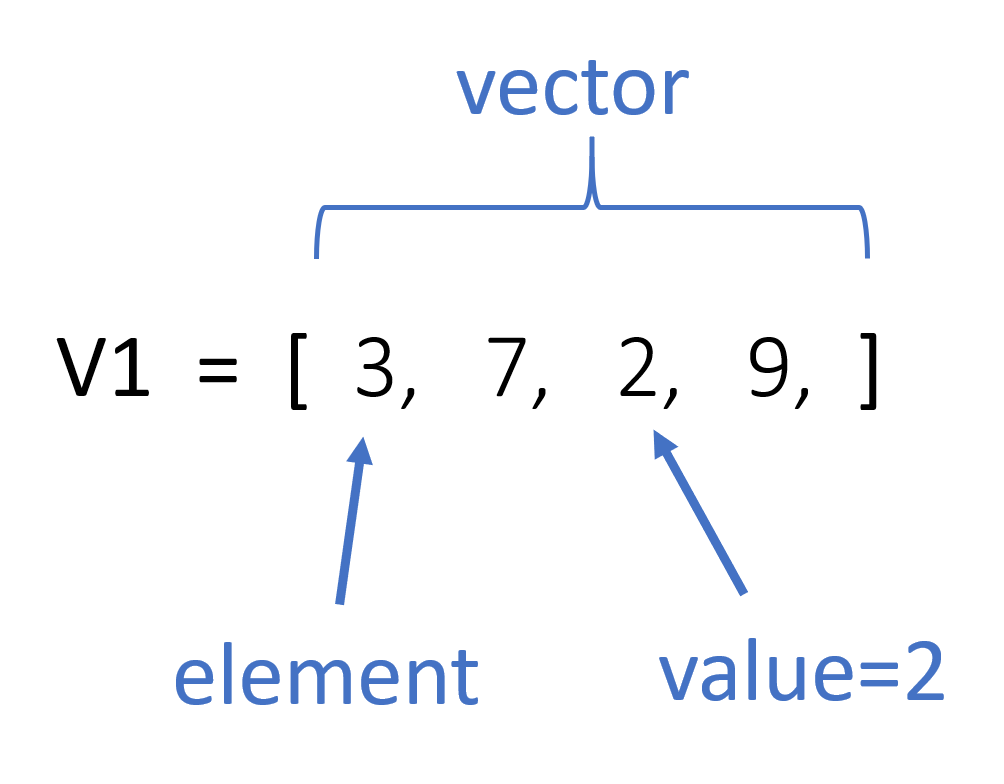
Figure 1.1: Components of a Vector
KEY CONCEPTS:
In this chapter, we’ll learn about the four main types of vectors:
- numeric
- character
- factor
- logical
TAKEAWAYS:
- All data in R is an object
- Objects have classes that specify what type of object it is
- Vectors can be numeric, character, factor or logical
- Vectors are the building blocks of data frames - the columns of a dataset
- They are created using constructors like the combine function c()
- You can change data types using casting
1.1 Key Concepts
Figure 1.2: Components of a Vector
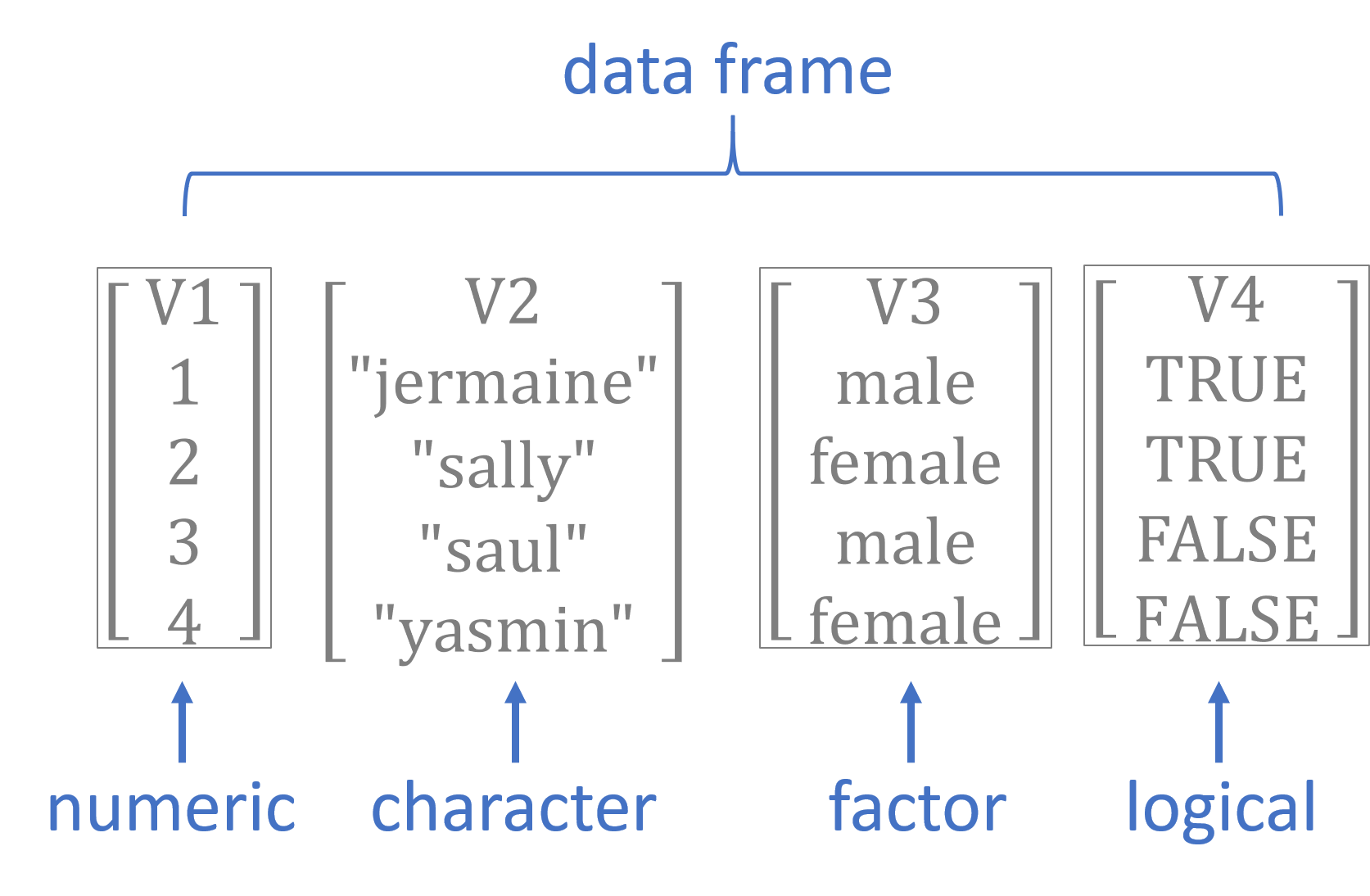
Figure 1.3: Basic data types in R
2 Vectors
Generally speaking a vector is a set of numbers, words, or other values stored sequentially:
- [ 1, 2, 3]
- [ apple, orange, pear ]
- [ TRUE, FALSE, FALSE ]
In social sciences, a vector usually represents a variable in a dataset, often as a column in a spreadsheet.
We might manually build a dataset by entering data as follows:
strength <- c( 167, 185, 119, 142 )
name <- c( "adam", "jamal", "linda", "sriti" )
sex <- factor( c( "male", "male", "female", "female" ) )
study.group <- c( "treatment", "control", "treatment", "control" )
is.treated <- study.group == "treatment"
dat <- data.frame( name, sex, study.group, is.treated, strength )| name | sex | study.group | is.treated | strength |
|---|---|---|---|---|
| adam | male | treatment | TRUE | 167 |
| jamal | male | control | FALSE | 185 |
| linda | female | treatment | TRUE | 119 |
| sriti | female | control | FALSE | 142 |
Here are the important things to pay attention to:
- Each vector was created with the combine c() function.
- Numbers do not require quotation marks around elements.
- Characters require quotation marks.
- The is.treated vector represents membership in a group.
3 Data Types
There are four primary vector types (“classes”) in R:
| Class | Description |
|---|---|
| numeric | Only numbers |
| character | A vector of letters or words, always enclosed with quotes |
| factor | Categorical variables |
| logical | TRUE or FALSE values |
Each type of vector serves different purposes:
- numeric: keep track of quantitative measures, counts, or orders of things
- character: store non-numeric data, typically unstructured text
- factor: represent distinct and mutually-exclusive categories
- logical: disignate cases that meet some criteria, usually group inclusion
Each vector in R is stored as an object, a technical term in computer science that we will discuss more later. For now know that each object has a class that represents the data type. We can ask R for the data types using the class() function:
class( name )## [1] "character"class( strength )## [1] "numeric"class( study.group )## [1] "character"class( is.treated )## [1] "logical"class( dat )## [1] "data.frame"3.1 Common Vectors Functions
You will spend a lot of time creating data vectors, transforming variables, generating subsets, cleaning data, and adding new observations. These are all accomplished through functions that act on vectors.
Here are some common vector functions:
3.1.1 vector length
We often need to know how many elements belong to a vector, which we find with the length() function.
length( strength )## [1] 43.1.2 combine
To combine several elements into a single vector, or combine two vectors to form one, use the c() function.
c( 1, 2, 3 ) # create a numeric vector## [1] 1 2 3c( "a", "b", "c" ) # create a character vector## [1] "a" "b" "c"Combining two vectors:
x <- 1:5
y <- 10:15
c( x, y )## [1] 1 2 3 4 5 10 11 12 13 14 15Combining two vectors of different data types:
x <- c( 1, 2,3 )
y <- c( "a", "b", "c" )
c( x, y )## [1] "1" "2" "3" "a" "b" "c"What happened to the numeric elements here?
3.2 Casting
You can easily move from one data type to another by casting a specific type as another type:
# character casting
x <- 1:5
x## [1] 1 2 3 4 5as.character(x) # numbers stored as text## [1] "1" "2" "3" "4" "5"The rules for casting vary by data type. Take logical vectors, for example. Re-casting them as character vectors produces an expected result. What about as a numeric vector?
y <- c( TRUE, FALSE, TRUE, TRUE, FALSE )
y## [1] TRUE FALSE TRUE TRUE FALSEas.character( y )## [1] "TRUE" "FALSE" "TRUE" "TRUE" "FALSE"as.numeric( y )## [1] 1 0 1 1 0If you are familiar with boolean logic or dummy variables in statistics, it actually makes sense that TRUE would be represented as 1 in numeric form, and FALSE as 0.
But in some cases it might not make sense to cast one variable type as another and we can get unexpected or unwanted behavior.
z <- c( "a", "b", "c" )
z## [1] "a" "b" "c"as.numeric( z )## [1] NA NA NAThe element NA is read as NOT AVAILABLE or NOT APPLICABLE, and is the value R uses to represent missing or deleted data.
NA’s are really important (and somewhat annoying). We will discuss missing values more in-depth later.
3.3 Care When Casting
Casting will often be induced automatically when you try to combine different types of data. For example, when you add a character element to a numeric vector, the whole vector will be cast as a character vector.
x1 <- 1:5
x1## [1] 1 2 3 4 5x1 <- c( x1, "a" ) # a vector can only have one data type
x1 # all numbers silently recast as characters## [1] "1" "2" "3" "4" "5" "a"If you consider the example above, when a numeric and character vector are combined all elements are re-cast as strings because numbers can be represented as characters but not vice-versa.
R tries to select a reasonable default type, but sometimes casting will create some strange and unexpected behaviors. Consider some of these examples.
Which data type will each step produce? Type the case# to see the results.
The answers to case1 and case2 are somewhat intuitive.
case1 # combine a numeric and logical vector## [1] 1 2 3 1 0 1Recall that TRUE and FALSE are often represented as 1 and 0 in datasets, so they can be recast as numeric elements. The numbers 2 and 3 have no meaning in a logical vector, so we can’t cast a numeric vector as a logical vector. This will default to numeric because we do not lose any information - the one’s and zero’s can always be re-cast back to logical vectors later if necessary.
case2 # combine a character and logical vector## [1] "a" "b" "c" "TRUE" "FALSE" "TRUE"Similarly characters have no meaning in the logical format, so we would have to replace them with NA’s if we converted the character vector to a logical vector.
as.logical( x2 )## [1] NA NA NASo converting the logical vector to characters allows us to retain all of the information in both vectors.
case3 and case4 are a little more nuanced. See the section on factors below to make sense of them.
case3 # combine a numeric and factor vector## [1] 1 2 3 1 2 3case4 # combine a character and factor vector## [1] "a" "b" "c" "1" "2" "3"TIP: When you read data in from outside sources, R will sometimes try to guess the data types and store numeric or character vectors as factors. To avoid corrupting your data see the section below on factors for special instructions on re-casting factors as numeric vectors.
3.4 Numeric Vectors
There are some specific things to note about each vector type.
Math operators will only work on numeric vectors.
Note that if we try to run this mathematical function we get an error:
Many functions in R are sensitive to the data type of vectors. Mathematical functions, for example, do not make sense when applied to text (character vectors). In many cases R will give an error.
In some cases R will silently re-cast the variable, then perform the operation. Be watchful for when silent re-casting occurs because it might have unwanted side effects, such as deleting data or re-coding group levels in the wrong way.
3.4.1 Integers
Integers are simple numeric vectors. The integer class is used to save memory since integers require less RAM space than numbers that contain decimals points (you need to allocate space for the numbers to the left and the numbers to the right of the decimal). Google “computer memory allocation” if you are interested in the specifics.
If you are doing advanced programming you will be more sensitive to memory allocation and the speed of your code, but in the intro class we will not differentiate between the two types of number vectors. In most cases they result in the same results, unless you are doing advanced numerical analysis where rounding errors matter!
n <- 1:5
n## [1] 1 2 3 4 5class( n )## [1] "integer"n[ 2 ] <- 2.01 # replace the second element with "2.01"
n # all elements converted to decimals## [1] 1.00 2.01 3.00 4.00 5.00class( n )## [1] "numeric"3.5 Character Vectors
The most important rule to remember with this data type: when creating character vectors, all text must be enclosed by quotation marks.
This one works:
c( "a", "b", "c" ) # this works## [1] "a" "b" "c"This one will not:
c( a, b, c )
# Error: object 'a' not foundWhen you type characters surrounded by quotes then R knows you are creating new text (“strings” of letters in programming speak).
When you type characters that are not surrounded by quotes, R thinks that you are looking for an object in the environment, like the variables we have already created. It gets confused when it doesn’t find the object that you typed.
In general, you will use quotes when you are creating character vectors and for arguments in functions. You do not use quotes when you are referencing an active object.
An active object is typically a dataset or vector that you have imported or created. You can print a list of all active objects with the ls() function.
3.5.1 Quotes in Arguments
When you first start using R it can be confusing about when quotes are needed around arguments. Take the following example of the color argument (col=) in the plot() function.
group <- factor( sample( c("treatment","control"), 100, replace=TRUE ) )
strength <- rnorm(100,100,30) + 50 * as.numeric( group=="treatment" )
par( mfrow=c(1,2) )
plot( strength, col="blue", pch=19, bty="n", cex=2 )
plot( strength, col=group, pch=19, bty="n", cex=2 )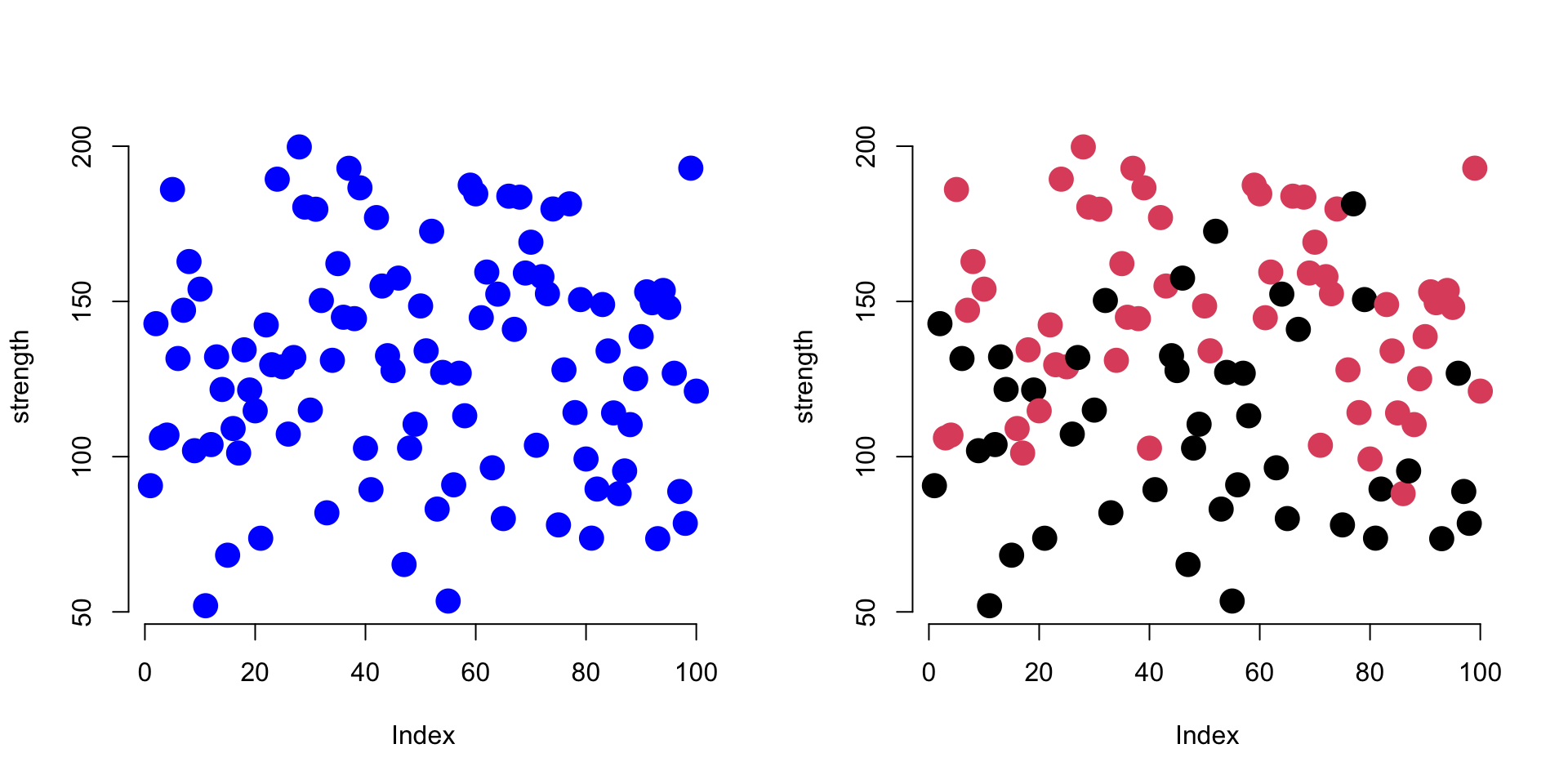
These graphs show patterns in the strength measures from our study. The first plots all subjects as blue, and the second plots subjects in the treatment group as red, control group as black.
In the first plot we are using a text argument to specify a color (col="blue"), so it must be enclosed by quotes.
In the second example R selects the color based upon group membership specified by the factor called ‘group’. Since the argument is now referencing an object (col=group), we do not use quotes.
The exception here is when your argument requires a number. Numbers are not passed with quotes, or they would be cast as text. For example, (bty="n") tells the plot to not draw a box around the graph, and the cex argument controls the dot size: (cex=2).

I know. I’m with you.
3.6 Factors
When there are categorical variables within our data, or groups, then we use a special vector to keep track of these groups. We could just use numbers (1=female, 0=male) or characters (“male”,“female”), but factors are useful for two reasons.
First, it saves memory. Text is very “expensive” in terms of memory allocation and processing speed, so using simpler data structure makes R faster.
Second, when a variable is set as a factor, R recognizes that it represents a group and it can deploy object-oriented functionality. When you use a factor in analysis, R knows that you want to split the analysis up by groups.
height <- c( 70, 68, 69, 74, 72, 69, 68, 73 )
strength <- c(167,185,119,142,175,204,124,117)
sex <- factor( c("male","male","female","female","male","male","female","female" ) )
par( mfrow=c(1,2) )
plot( height, strength, # two numeric vectors: scatter plot
pch=19, cex=3, bty="n" )
plot( sex, strength ) # factor + numeric: box and whisker plot 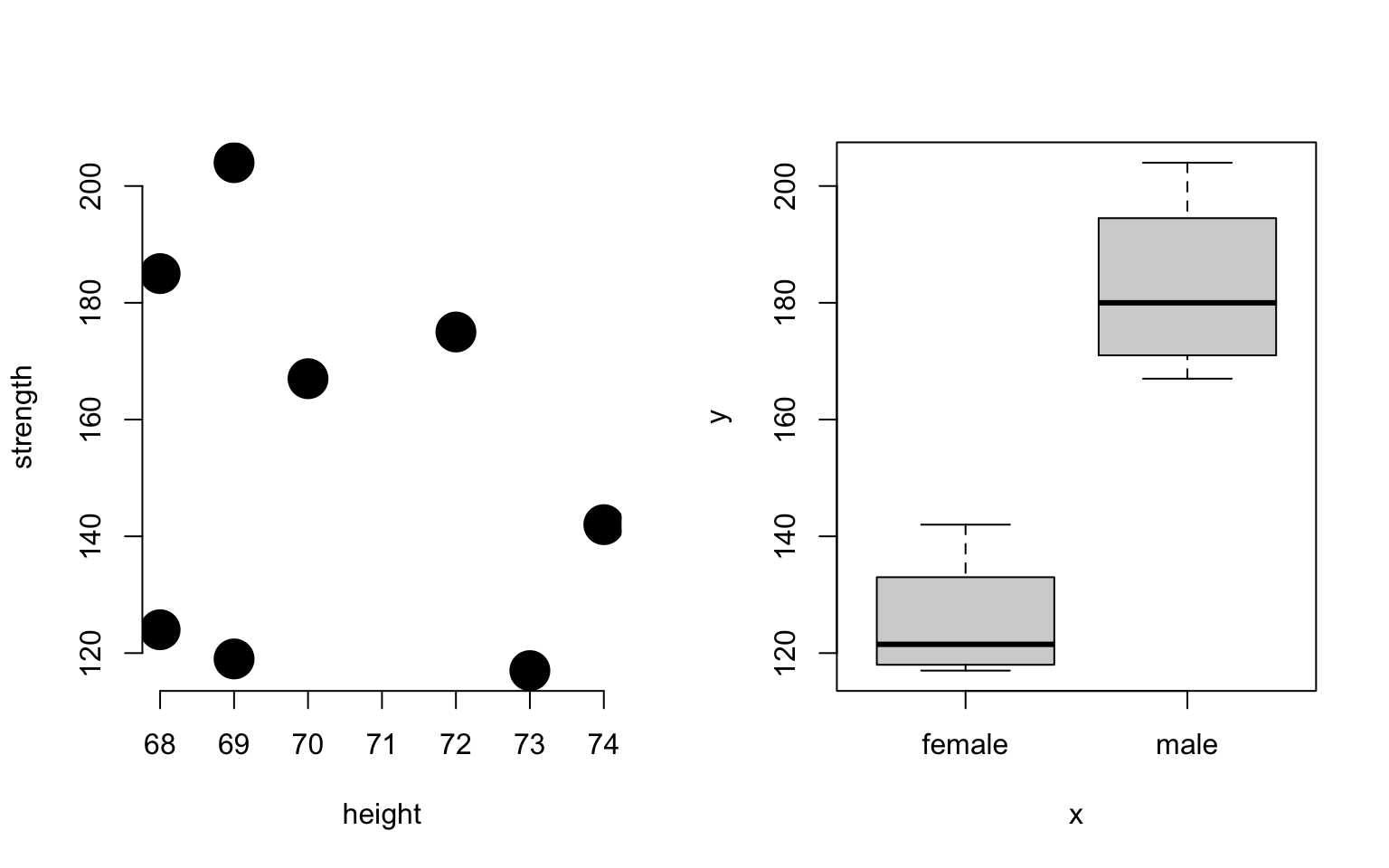
Note in this example the same plot() function produced two different types of graphs, a scatterplot and a box and whisker plot. How does this work?
R uses the object type to determine behavior: * If input vectors are both numeric, then produce scatterplot * If input vectors are factor + numeric, then produce a box and whisker.
This is called object-oriented programming - the functions adapt based upon the type of object they are working with.
It makes the process of creating data recipes much faster! We will revisit this concept later.
Factors are more memory efficient than character vectors because they store the underlying data as a numeric vector instead of a categorical (text) vector. Each group in the data is assigned a number, and when printing items the program only has to remember which group corresponds to which number:
as.numeric( sex )## [1] 2 2 1 1 2 2 1 1# male = 2
# female = 1If you print a factor, the computer just replaces each category designation with its name (2 would be replaced with “male” in this example). These replacements can be done in real time without clogging the memory of your computer as they don’t need to be saved.
In some instances a categorical variable might be represented by numbers. For example, grades 9-12 for high school kids. These can be tricky to re-cast.
grades <- sample( x=9:12, size=10, replace=T )
grades## [1] 9 11 12 12 11 11 11 10 9 11grades <- as.factor( grades )
grades## [1] 9 11 12 12 11 11 11 10 9 11
## Levels: 9 10 11 12as.numeric( grades )## [1] 1 3 4 4 3 3 3 2 1 3as.character( grades )## [1] "9" "11" "12" "12" "11" "11" "11" "10" "9" "11"# proper way to get back to the original numeric vector
as.numeric( as.character( grades ))## [1] 9 11 12 12 11 11 11 10 9 11The very important rule to remember with factors is you can’t move directly from the factor to numeric using the as.numeric() casting function. This will give you the underlying data structure, but will not give you the category names. To get these, you need the as.character casting function.
TIP: When reading data from Excel spreadsheets (usually saved in the comma separated value or CSV format), remember to include the following argument to prevent the creation of factors, which can produce some annoying behaviors.
dat <- read.csv( "filename.csv", stringsAsFactors=F )3.7 Logical Vectors
Logical vectors are collections of a set of TRUE and FALSE statements.
Logical statements allow us to define groups based upon criteria, then decide whether observations belong to the group. A logical statement is one that contains a logical operator, and returns only TRUE, FALSE, or NA values.
Logical vectors are important because organizing data into these sets is what drives all of the advanced data analytics (set theory is at the basis of mathematics and computer science).
| name | sex | treat | strength |
|---|---|---|---|
| adam | male | treatment | 167 |
| jamal | male | control | 185 |
| linda | female | treatment | 119 |
| sriti | female | control | 142 |
dat$name == "sriti"## [1] FALSE FALSE FALSE TRUEdat$sex == "male"## [1] TRUE TRUE FALSE FALSEdat$strength > 180## [1] FALSE TRUE FALSE FALSEWhen defining logical vectors, you can use the abbreviated versions of T for TRUE and F for FALSE.
z1 <- c(T,T,F,T,F,F)
z1## [1] TRUE TRUE FALSE TRUE FALSE FALSETypically logical vectors are used in combination with subset operators to identify specific groups in the data.
# isolate data on all of the females in the dataset
dat[ dat$sex == "female" , ]## name sex treat strength
## 3 linda female treatment 119
## 4 sriti female control 142See the next chapter for more details on subsets.
3.8 Generating Vectors
You will often need to generate vectors for data transformations or simulations. Here are the most common functions that will be helpful.
3.8.1 Repeated Values
3.8.2 Sequence of Values
3.8.3 Random Sample
3.8.4 Draw From a Normal Distribution
3.9 Recycling
When we create a new variable from existing variables, it is called a “transformation”. This is very common in data science. Crime is measures by the number of assaults per 100,000 people, for example (crime / pop). A batting average is the number of hits divided by the number of at bats.
In R, mathematical operations are vectorized, which means that operations are performed on the entire vector all at once. This makes transformations fast and easy.
x <- 1:10
x + 5## [1] 6 7 8 9 10 11 12 13 14 15x * 5## [1] 5 10 15 20 25 30 35 40 45 50R uses a convention called “recycling”, which means that it will re-use elements of a vector if necessary. In the example below the x vector has 10 elements, but the y vector only has 5 elements. When we run out of y, we just start over from the beginning. This is powerful in some instances, but can be dangerous in others if you don’t realize that that it is happening.
x <- 1:10
y <- 1:5
x + y## [1] 2 4 6 8 10 7 9 11 13 15x * y## [1] 1 4 9 16 25 6 14 24 36 50# the colors are recycled
plot( 1:5, 1:5, col=c("red","blue"), pch=19, cex=3, bty="n" )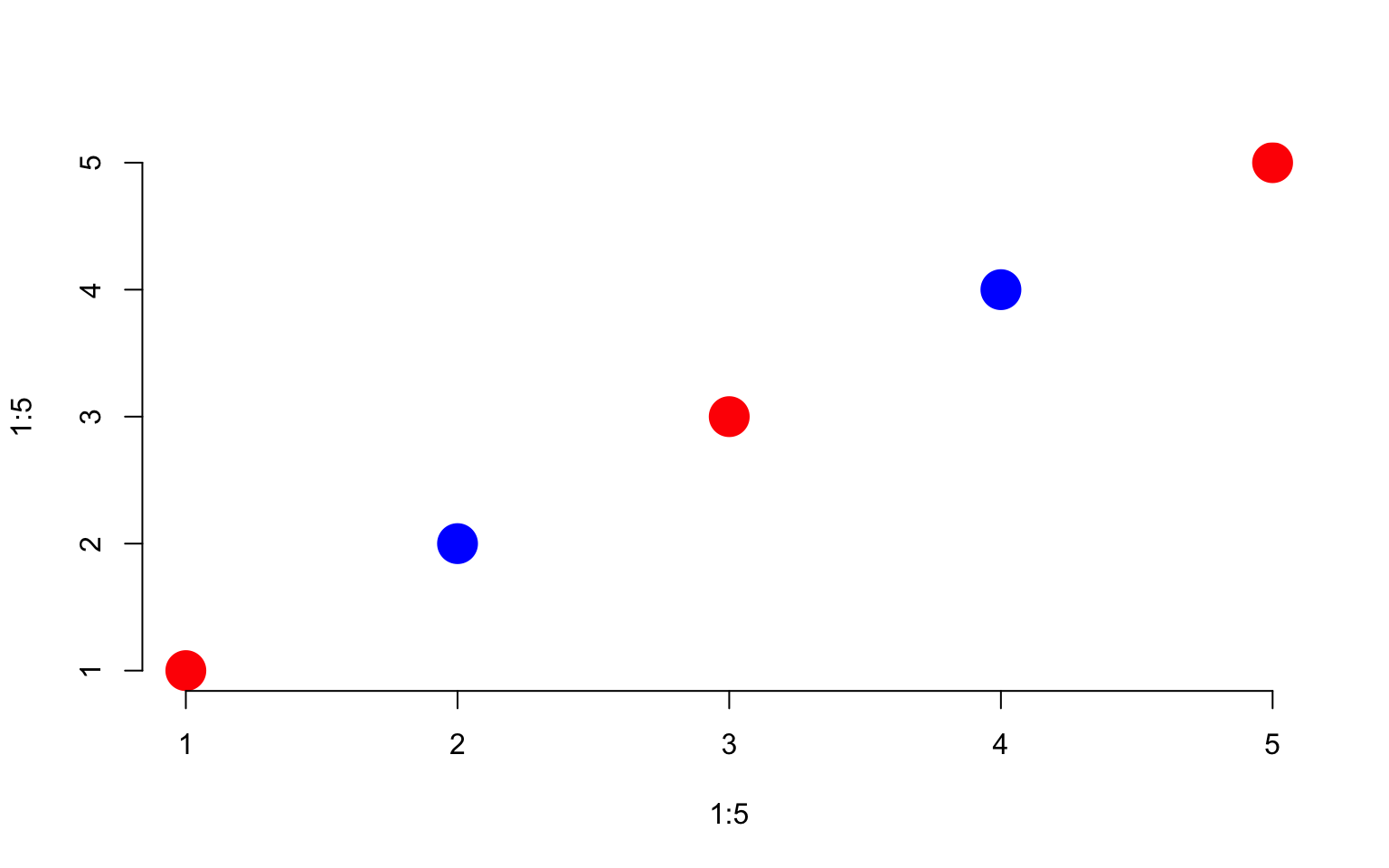
Here is an example of recycling gone wrong:
| name | sex | treat | strength |
|---|---|---|---|
| adam | male | treatment | 167 |
| jamal | male | control | 185 |
| linda | female | treatment | 119 |
| sriti | female | control | 142 |
# create a subset of data of all female study participants
dat$sex == "female"## [1] FALSE FALSE TRUE TRUEthese <- dat$sex == "female"
dat[ these, ] # correct subset## name sex treat strength
## 3 linda female treatment 119
## 4 sriti female control 142# same thing with a mistake
# whoops! should be double equal for a logical statement
# the female element is recycled
# just wrote over my raw data!
dat$sex = "female"
these <- dat$sex == "female"
dat[ these , ]## name sex treat strength
## 1 adam female treatment 167
## 2 jamal female control 185
## 3 linda female treatment 119
## 4 sriti female control 1423.10 Missing Values: NA’s
Missing values are coded differently in each data analysis program. SPSS uses a period, for example. In R, missing values are coded as “NA”.
The important thing to note is that R wants to make sure you know there are missing values if you are conducting analysis. As a result, it will give you the answer of “NA” when you try to do math with a vector that includes a missing value. You have to ask it explicitly to ignore the missing value.
You cannot use the == operator to identify missing values in a dataset. There is a special is.na() function to locate all of the missing values in a vector.