Specifically this project examines the effectiveness of two larger federal block-grant programs that target low-income neighborhoods.
- New Market Tax Credits (NMTC)
- Low Income Housing Tax Credits (LIHTC)
The project uses Census data to model community change between the periods 2000 and 2010 (the data goes back as far as 1970).
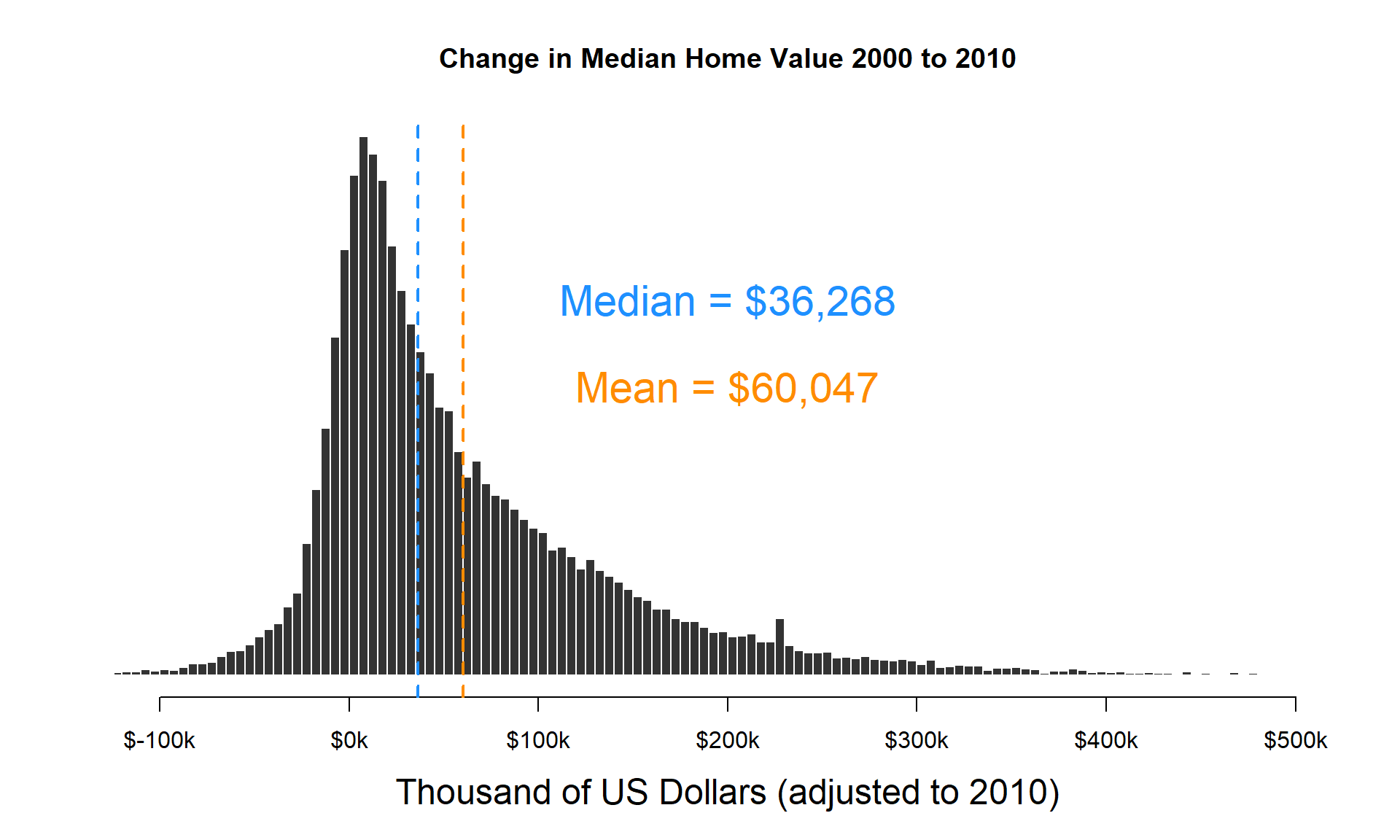
Tax credit dollars are then aggregated by Census Tracts and form the “treatment” in the study.
The project was designed to give students a big enough task that it was a realistic project, but provide enough resources for it to be manageable.
Causal Analysis With Non-Experimental Data (Counterfactual Reasoning)
The NMTC and LIHTC programs are also market-based developer-driven, which means there are likely selection issues (community development banks give out loans that need to be repaid, so they will target census tracts with high potential for success). These pose interesting estimation challenges that can be interesting to students studying program evaluation and applied econometrics.
Program participation is determined through some means-testing, which provides opportunities to leverage eligibility-criteria cut-off points to create interesting quasi-experimental counterfactuals in order to overcome selection problems that will most certainly bias estimates of program impact.
This allows for comparisons of estimation approaches using:
- Regular OLS model
- Metro-level fixed effects
- Difference-in-difference models
- Matched census tracts
- Regression discontinuity design
And finally, the data is complex enough that specification considerations will have a big impact on inferences. The comparison of program impact estimates under different specifications can illustrate the importance of variable construction (do you present home values in dollar amounts, or relative rank within metros?), measurement (how can we operationalize the construct of gentrification?), skew (which-variables are improved through log-transformations?), and outliers.
The Art of Data Analysis
Linear tasks are faily easy to teach. You start at the beginning and complete each step until you are done.
Non-linear tasks that involve ambiguity are hard to teach, because they involve critical thinking, iterative exploration, and judgement.
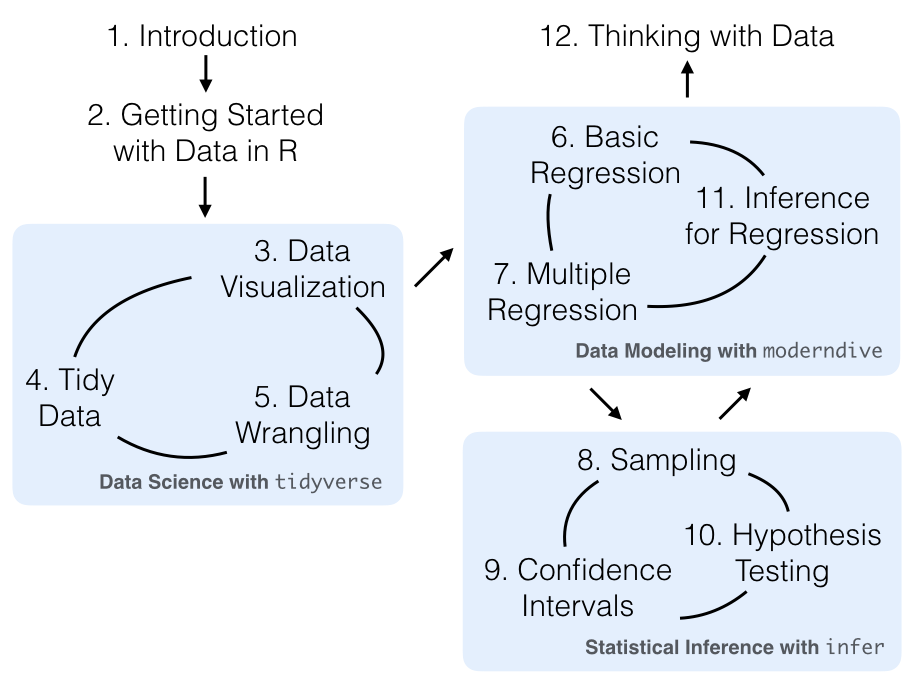 Diagram from the Modern Dive textbook (Ismay & Kim, 2019)
Diagram from the Modern Dive textbook (Ismay & Kim, 2019)
Data analysis falls into this category of tasks. Real world projects require exploratory analysis, iterative design of variables and models, and some ambiguity related to the best approach for any given problem.
Open Science Approaches
Analysts often explore the modeling space by iteratively trying lots of different specifications until they have stable models and generate reasonable results.
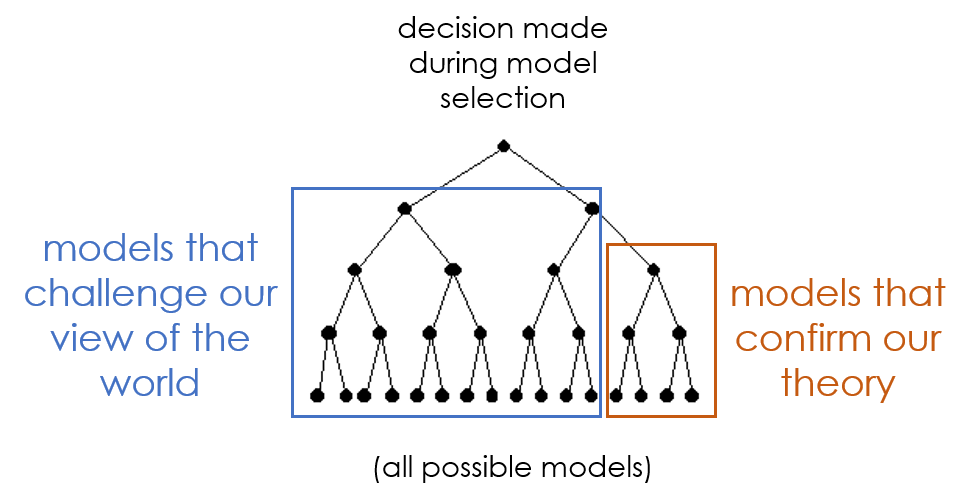
There is an art to this process, but it is rarely objective of devoid of actors that are incentivized gravitate toward models that support certain conclusions.
These examples are also an opportunity to teach students about the dangers of p-value hacking, proper tests for model robustness, and important open-science best practices to ensure the modeling process is transparent and reproducible.
This project attempts to model good open science principles by starting with raw data, providing code that demonstrates the construction of the research database, uses data-driven documents to present the code and analytical steps used to generate the models, and makes it all available through open source platforms and licensing.
Specifically:
- Data and code for this project are available on GitHub at DS4PS/nhood-change-project
- This website was built using free GitHub Pages (powered by Jekyll)
- The analysis is done using the open source data programming language R
- Data-driven documents are powered by R Markdown and Pandoc
- GIS tools were made possible by the R spatial analysis community and R Open Science
- The project uses open data available through the Census and the Federal DATA Act