COURSE CONTENT:
- Semester Overview
- Week 1 - Nuts and Bolts of Regression Models
- Week 2 - Effect Size and Confidence Intervals
- Week 3 - Control Variables
- Week 4 - Omitted Variable Bias
- Week 5 - Dummy Variables
- Week 6 - Specification Bias
- Review Material
- Final Exam
Semester Overview
These courses are designed to be interactive, and a lot of learning occurs by practicing the technical jargon from the field and learning how to talk about data and models.
Course Cadence
Please note the organizatin of assignments for class.

Labs are due Saturday, mini assessments covering the previous lab are on Tuesday.
Get started early on labs so you have time to ask questions on the discussion board if you get stuck.
Labs are graded pass-fail. The criteria is that you demonstrate an understanding of the topics covered, which is typically operationalized as getting over half of the questions on the assignment correct.
The mini assessments typically consist of three multiple-choice or matching questions to guage your understanding of the previous week’s lectures and lab. If you understood everything on the labs you should do fine on the mini assessments.
Mini-assessments open on Saturday and close Tuesday at 11:59pm (AZ time). You have 30 minutes to complete an assessment once they start. You can take it at any time Sat-Tues.
Tips for Success
There is no way to learn and retain all of this material in one course.
It is completely normal for this material to not click the first time you see it. We will try to repeat concepts and build on them through the semester, and the Evaluation sequence in this program (CPP 523, 524, and 525) offer reinforcement.
You are investing in a skill-set that you will build over time. You will find some material organized for quick reference on the Resources page.
You are encouraged to build your own library of sources you find useful and keep them for future reference.
Getting Help
Learning how to seek help and use discussion boards will accelerate learning and facilitate collaboration. Social coding tools like GitHub use these features extensively.
We are going to throw a lot at you, but also provide a lot of support. Over these first couple of weeks feel free to reach out for anything you might need.
If you find something confusing let us know (likely others will find it confusing as well).
- You can post a question to the homework discussion board.
- You can schedule a Zoom call to do a screen share if you want to walk through anything.
- Or you can request a walk-through of a problem. The instructor will provide an example with the solution.
As a general rule of thumb, if you are stuck on the math or code for a problem, need clarification about what the question is asking, want to make sure you understand a formula, or are having similar issues then the help discussion page is the easiest and quickest way to get help.
If you are confused about concepts or having a hard time even formulating your question then virtual office hours are your best option.
Note that the discussion board is hosted by the GitHub issues feature. It is a great forum because:
- You can format code and math using standard markdown syntax.
- You can cut and paste images directly into the message.
- You can direction responses using @username mentions.
Please preview your responses before posting to ensure proper formatting. Note that you format code by placing fences around the code:
```
# your code here
lm( y ~ x1 + x2 )
# formulas
y = b0 + b1•X1 + b2•X2 + e
b1 = cov(x,y) / var(x)
```
The fences are three back-ticks. These look like quotation marks, but are actually the character at the top left of your keyboard.
Week 1 - Nuts and Bolts of Regression Models
Overview
This section provides a review of the basic building blocks of a bivariate regression model:
- sample variance and standard deviation
- slope
- intercept
- regression line
- the “error term” or “residual”
- standard errors
Learning Objectives:
Once you have completed this section you will be able to conceptually understand what a regression slope represents (the conditional mean), the formulas for regression coefficients, and the tabulation of residuals.
Review:
Test your baseline knowledge of regression models model with the regression review handout.
This review will be useful to benchmark your knowledge about regression models, and offers a good reference for the concepts that you should focus on over the first three weeks of class. On the final exam you will be expected to demonstrate an understanding of:
- Variance and covariance
- The sampling distribution
- Standard deviation
- Standard error
- Confidence intervals
- Slope
- “Explained” variance
Readings:
Reichardt, C. S., & Bormann, C. A. (1994). Using regression models to estimate program effects. Handbook of practical program evaluation, 417-455. [ pdf ]
For reference:
Diez, D. M., Barr, C. D., & Cetinkaya-Rundel, M. (2012). OpenIntro statistics (pp. 174-175). OpenIntro. CH-08 Introduction to Linear Regression
Multiple Regression overview chapter [pdf]
Lecture
Is caffeine good for you? [ in the news ]
Is caffeine a treatment in this study? How do we know caffeine is the cause of the outcomes we see in this study?
Before we can understand causal impact we must first create a regression model that tells us about the RELATIONSHIP between caffeine intake and heart rate. We will then add nuance to our understanding of when the relationship can be interpretted as casual, and when it is simply correlational.
LECTURE: [ BUILDING A REGRESSION MODEL ]
Data Used in this Section
Caffeine and Heart Rates based off of this caffeine study:
# paste this code into R
url <- "https://raw.githubusercontent.com/DS4PS/cpp-523-fall-2020/master/lectures/data/caffeine.csv"
dat <- read.csv( url, stringsAsFactors=F )
summary( dat )
plot( dat$caffeine, dat$heart.rate )
model.01 <- lm( heart.rate ~ caffeine, data=dat )
summary( model.01 )
Lab 01
Due Saturday, August 29th
The first lab is meant as a review of some important regression formulas to either shake out the cobwebs if you have covered this material before, or get everyone on the same page if it is new. It will review the following topics:
- Calculating a bivariate regression slope (
b1) - Basic interpretation of the slope
- Intercept (
b0) - What is a residual?
- residual (or error) sum of squares
- regression (or explained) sum of squares
- R-squared: the measure of variance explained
The lecture notes needed for the lab are available on the course shell:
[ Building a regression model ]
And the first chapter from Lewis-Beck serves as a reference for specific formulas if needed:
Lewis-Beck, C., & Lewis-Beck, M. (2015). Applied regression: An introduction (Vol. 22). Sage publications. [ pdf ]
This first lab is designed as a review (or getting up to speed) assignment to direct your attention on a handful of important regression formulas we will use this semester. For the most part we will rely on the computer the do the math for us, but these formulas are important for our conceptual understanding of the regressions, so there is value in working through a simple example (five data points) by hand.
For THIS ASSIGNMENT ONLY all of the work is done by hand so you can type your answers right into the Lab 01 word document. For future assignments we will be using R Markdown documents so that you can run models and submit the results directly.
Please show the steps for each calculation. You can check your results in R or on a calculator when you are done.
If you have questions, please post them to the Assignment Discussion Board.
Save it using the naming convention:
Lab-##-LastName.doc
And submit via Canvas.
Mini-Assessment 01
Open Sat Aug 29 - Tues Sept 01
This mini-assessment consists of three multiple-choice questions. You have 30 minutes to complete the assessment from the time you start the assessment. You can take it any time over the 4 days it is open.
The assessment covers the definition of a regression line, and the concept of sums of squares from the first chapter:
This first assessment is not graded. All others are worth 2 points each.
Week 2 - Effect Size and Confidence Intervals
Overview
This week covers the topic of building confidence intervals around our estimates of program impact. We use the CIs to conduct hypothesis-testing to see if our program has the impact we expected.
- Confidence intervals are built using standard errors
- Standard errors are creaed from residuals
- Residuals are generated through regression models (as we learned last week).
Learning Objectives:
Once you have completed this section you should be able to build a confidence interval around a slope estimate of program impact, and interpret a table with several regressions.
Assigned Reading:
There are no assigned readings this week.
Key Take-Aways:
The lecture notes in this section cover the mechanics of standard errors and confidence intervals. These two important topics can be summed up in these animations of the sampling distribution of the mean.
Our model estimate for the slope is our best guess of the real statistic. It will always be pretty good, but not exact.

If we would repeatedly draw samples from a population and calculate slope estimates over and over, they would look like the distribution on the right. The “standard error” describes the average amount all of these guesses (statistics) are off from the true slope.
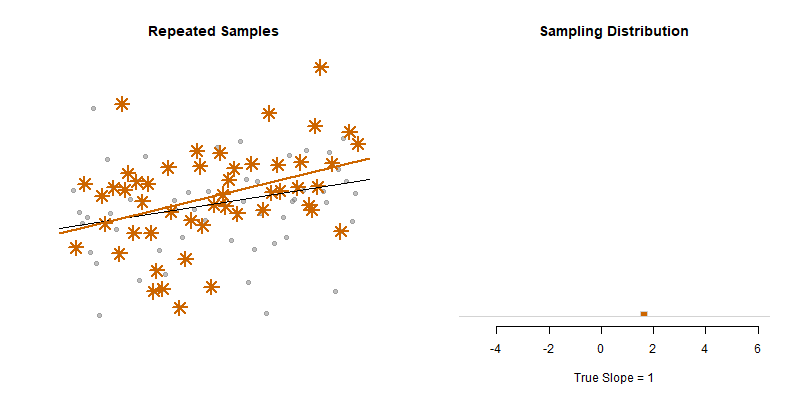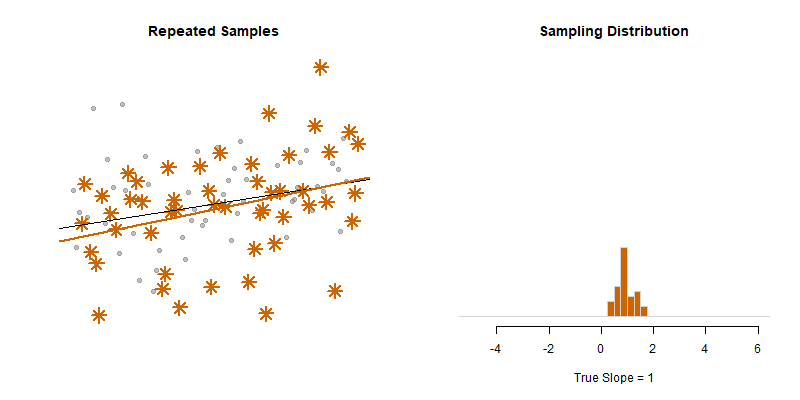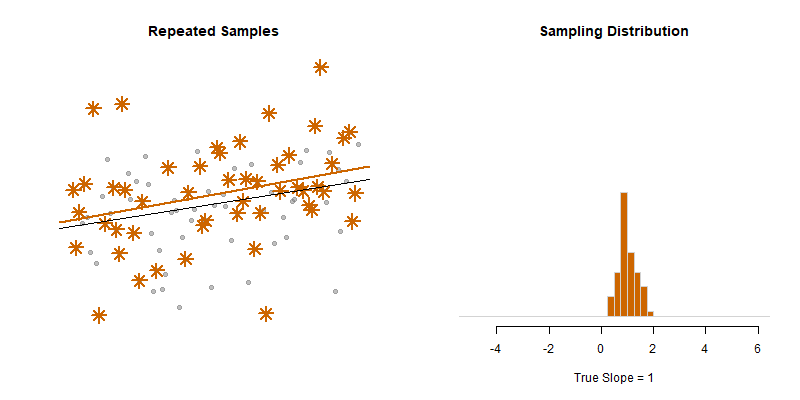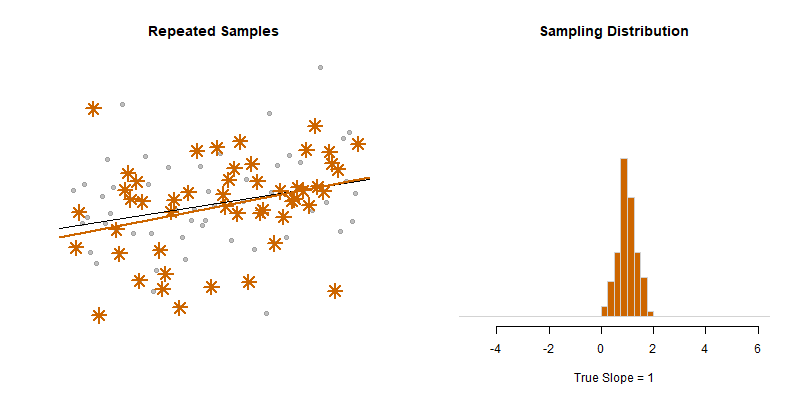
If we create 95% confidence intervals around these guesses, we can see that approximately 95 out of 100 of the CIs will contain the true slope (set to 3 here).
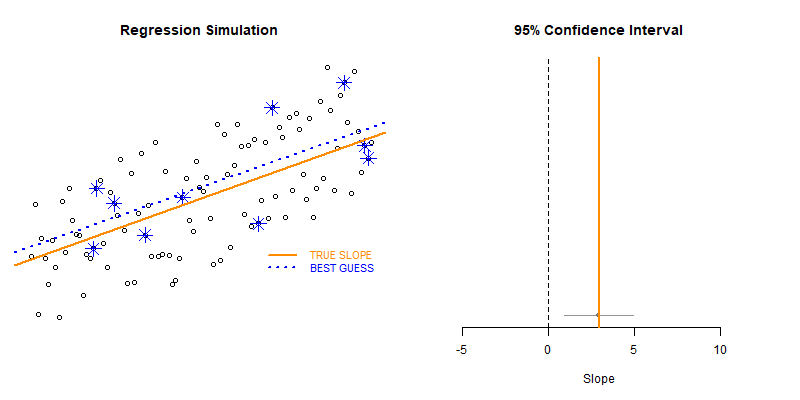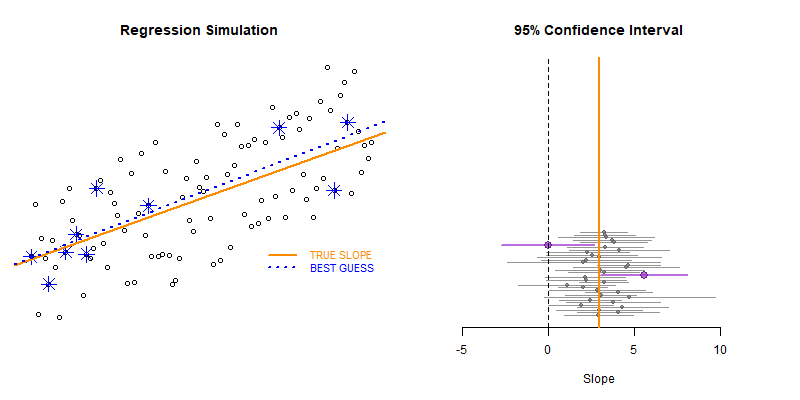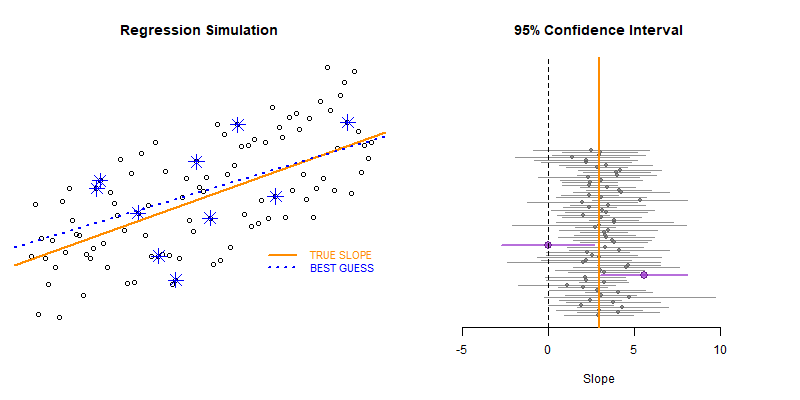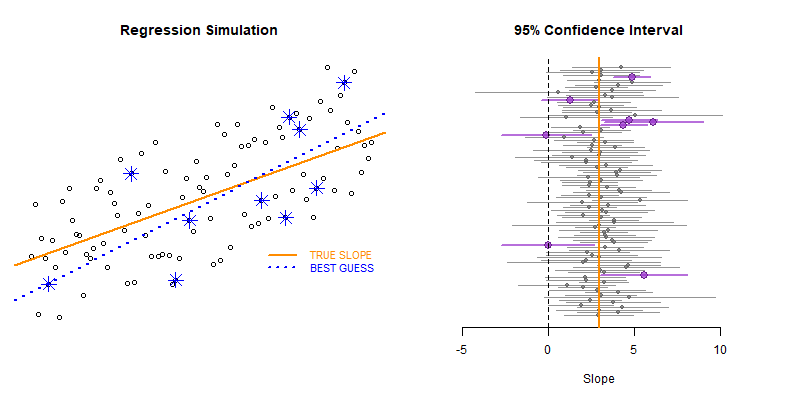
Lecture
Please review the following lecture notes:
- Variance and Covariance
- Partitioning the Variance of Y
- Standard Errors
- Confidence Intervals
- Effect Size
You might find this summary of notation helpful pdf
Lab 02
Due Saturday, September 5th
This lab introduces a case study on education policy that we will be using for the remainder of the semester to demonstrate the importance and impact of control variables, and consequences of their omissions.
You will need the formula for confidence intervals, and the concept of visual hypothesis-testing with coefficient plots.
When you are complete:
Mini Assessment 02
Open Sat Sept 05 - Tues Sept 08
This mini-assessment tests your understanding of the interpretation of statistical significance using confidence intervals.
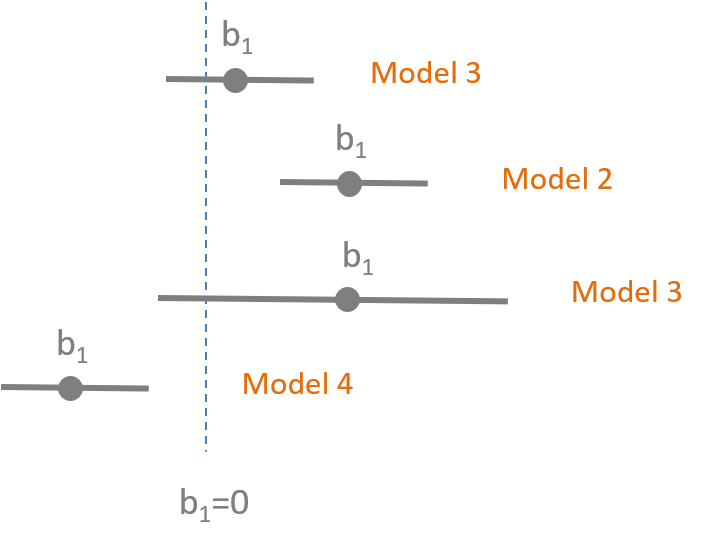
Week 3 - Control Variables
Overview
This lecture introduces you to two distinctive types of control variables, and how the different ways they change our models. We will also start using Ballentine Venn Diagrams to compare models.
Learning Objectives
Once you have completed this section you will be able to explain how adding specific control variables to a model (or leaving them out) will impact (1) the slopes and (2) the standard error of your model.
“Bivariate regression” means 2 variables:
Y = b0 + b1•X + e
“Multiple regression” or “Multivariate regression” means one DV and multiple independent variables:
Y = b0 + b1•X1 + b2•X2 + e
In the lecture notes X1 will always be the policy variable, or intervention of interest. The additional variables X2, X3, X4, etc. are all “control variables” that are meant to improve models.
Recommended Reading:
Skim: Multiple Regression
Baily CH5: Section 5.1-Multivariate OLS
Bailey, M. A. (2016). Real Stats: Using Econometrics for Political Science and Public Policy. Oxford University Press.
Lecture
Lecture 06 on Control Variables
Additional Material:
Nice explanation of the importance of control variables as competing hypotheses:
Tufte, E. R. (1974). Data analysis for politics and policy. Prentice Hall. CH4 Multiple Regression
Lab 03
Due Saturday, September 12th
This lab introduces the important role of control variables in our models. They can be used to reduce standard errors of the model and thus increase model efficiency, or they can be used to to adjust slopes in the model. The lab draws on material from the lecture 06 notes.
I have provided the code for the regression models and scatterplots. This lab focuses on interpretation of results. You do need to create an RMD document, and knit an HTML file to submit your results.
When you are complete:
Mini Assessment 03
Open Sat Sept 12 - Tues Sept 15
This mini-assessment tests your understanding of the differences between the two types of control variables (those correlated with the policy or intervention, i.e. classroom size and socio-economic status, and those that are uncorrelated with the policy but correlated with the outcome, i.e. teacher quality).
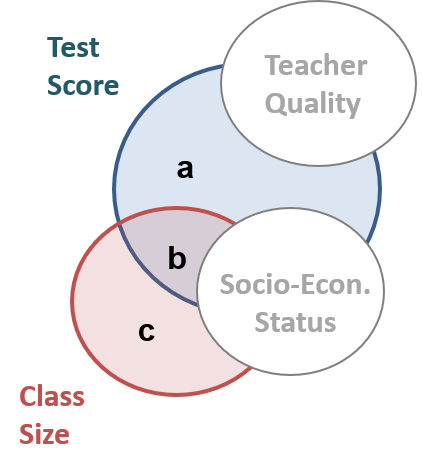
These differences are summarized on some of the review notes for the final exam:
Week 4 - Omitted Variable Bias
Overview
This week introduces the concept of omitted variable bias, and how it can impact our inferences in observational studies.
Learning Objectives
Once you have completed this section you should be able to:
- identify variables the have the potential to cause omitted variable bias
- calculate the size of bias that results from omitting a variable from a study
Required Reading:
‘Crack baby’ study ends with unexpected but clear result [ link ]
- A 1989 study in Philadelphia found that nearly one in six newborns at city hospitals had mothers who tested positive for cocaine. Troubling stories were circulating about the so-called crack babies. They had small heads and were easily agitated and prone to tremors and bad muscle tone, according to reports, many of which were anecdotal. Worse, the babies seemed aloof and avoided eye contact. Some social workers predicted a lost generation - kids with a host of learning and emotional deficits who would overwhelm school systems and not be able to hold a job or form meaningful relationships. The “crack baby” image became symbolic of bad mothering, and some cocaine-using mothers had their babies taken from them or, in a few cases, were arrested.
The study in the article was commissioned because of anedcotal evidence of a strong relationship between exposure to crack in the womb and poor development of a child, cognitively and socially.
If crack was the policy variable in this study, what was the omitted variable?
How did the understanding of the DIRECT impact of crack on child development change once the omitted variable was added to the models?
When are omitted variables a problem? What makes a variable a competing hypothesis?
Lecture
Lecture Notes: Omitted Variable Bias [ pdf ] [ example ]
Lecure Notes: A Taxonomy of Control Variables [ pdf ]
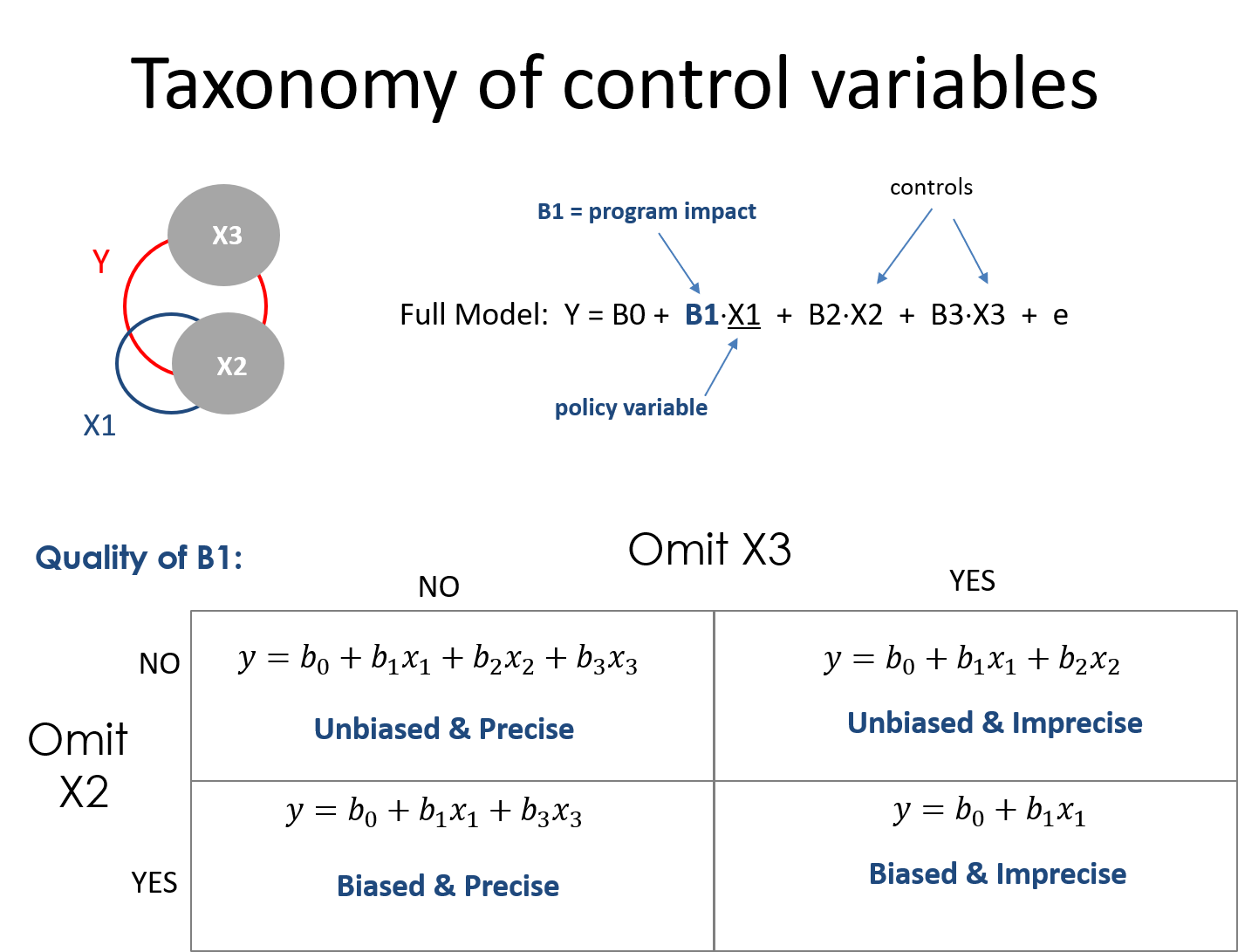
Lab 04
Due Saturday, September 19th
This lab examines the impact of omitted variable bias on our inferences.
Example of How to Calculate Bias [ PDF ]
A lab solutions RMD template has been provided. Submit your knitted files via Canvas.
When you are complete:
Omitted Variable Bias Calculations:
What happens when we omitt SES from the Classroom Size model?
# full regression: TS = B0 + B1*CS + B2*SES
# naive regression: TS = b0 + b1*CS
Recall when *B1 is used for the slope it represents the correct slope and b1 represents the slope that comes from an incomplete model or from a small sample and thus will likely be biased.
Calculations for bias:
URL <- "https://raw.githubusercontent.com/DS4PS/cpp-523-fall-2019/master/labs/class-size-seed-1234.csv"
dat <- read.csv( URL )
# naive regression in the example: TS = b0 + b1*CS
m.naive <- lm( test ~ csize, data=dat )
summary( m.naive )
# Coefficients:
# ----------------------------------
# Estimate Std. Error t value Pr(>|t|)
# (Intercept) 738.3366 4.8788 151.34 <2e-16 ***
# csize -4.2221 0.1761 -23.98 <2e-16 ***
# ----------------------------------
# full regression: TS = B0 + B1*CS + B2*SES
m.full <- lm( test ~ csize + ses, data=dat )
summary( m.full )
# Coefficients:
# ----------------------------------
# Estimate Std. Error t value Pr(>|t|)
# (Intercept) 665.289 76.574 8.688 <2e-16 ***
# csize -2.671 1.632 -1.637 0.102
# ses 16.344 17.098 0.956 0.339
# ----------------------------------
# auxiliary regression to get a1: SES = a0 + a1*CS
m.auxiliary <- lm( ses ~ csize, data=dat )
summary( m.auxiliary )
# lm(formula = ses ~ csize, data = dat)
# Coefficients:
# ----------------------------------
# Estimate Std. Error t value Pr(>|t|)
# (Intercept) 4.469458 0.009033 494.8 <2e-16 ***
# csize -0.094876 0.000326 -291.0 <2e-16 ***
# ----------------------------------
# b1 = B1 + bias
# b1 - B1 = bias
b1 <- -4.22
B1 <- -2.67
b1 - B1
# bias = a1*B2
a1 <- -0.0949
B2 <- 16.34
a1*B2
Mini-Assessment 04
Open Sat Sept 19 - Tues Sept 22
This mini-assessment tests your understanding of the interpretation of the impact of control variables on statistical significance.
Note that the lecture on control variables covers cases where we add variables to a model:
Y = b0 + b1 X1 + e # add controls
>>>
Y = b0 + b1(X1) + b2(X2) + b3(X3) + e
And the lecture on omitted variable bias is the exact same concepts, but now in reverse:
Y = b0 + b1(X1) + b2(X2) + b3(X3) + e # full model
>>>
Y = b0 + b1 X1 + e # omit variables
We are interested in how these operations impact (1) the slope of our policy variable and (2) the standard errors (i.e. confidence intervals) of our policy variable. Statistical significance is determined by the combination of slope and SE.
Week 5 - Dummy Variables
Overview
This week introduces modeling group differences within the data using dummy variables and interaction terms.
Dummy variables are binary 0/1 variables where 1 means the observation belongs to a group, 0 means the observation does not. We need one dummy variable for each level of a categorical variable.
y = b0 + b1(X) + b2(D) + e
Interactions are created by multiplying a covariate by a dummy variable.
y = b0 + b1(X) + b2(D) + b3(X)(D) + e
Adding dummy variables to models allows us to test several hypotheses about differences between groups.
Learning Objectives:
Once you have completed this section you will be able to run and interpret regression models with dummy variables and interaction effects.
Lecture
Groups in Regression Models
Hypothesis-Testing With Groups Part-01
Hypothesis-Testing With Groups Part-02
Lab Preview
Lab 05
Due Saturday, September 26th
This lab examines tests your understanding of constructing groups and conducting hypothesis tests using dummy variables.
When you are complete:
Mini-Assessment 05
Open Sat Sept 26 - Tues Sept 29
This mini-assessment tests your understanding of the interpretation of dummy variables in regression models.
# test of group means
y = b0 + b1(female) + e
# test of slope differences
y = b0 + b1(X) + b2(female) + b3(female•X) + e
Week 6 - Specification Bias
Overview
This week introduces the concept of specification bias, problems that arise when you run a regression without actually looking at the data to ensure your model makes sense.
Outliers, non-linearities, and other data problems need to be addressed if the model is to accurately describe the data and provide meaningful inferences.
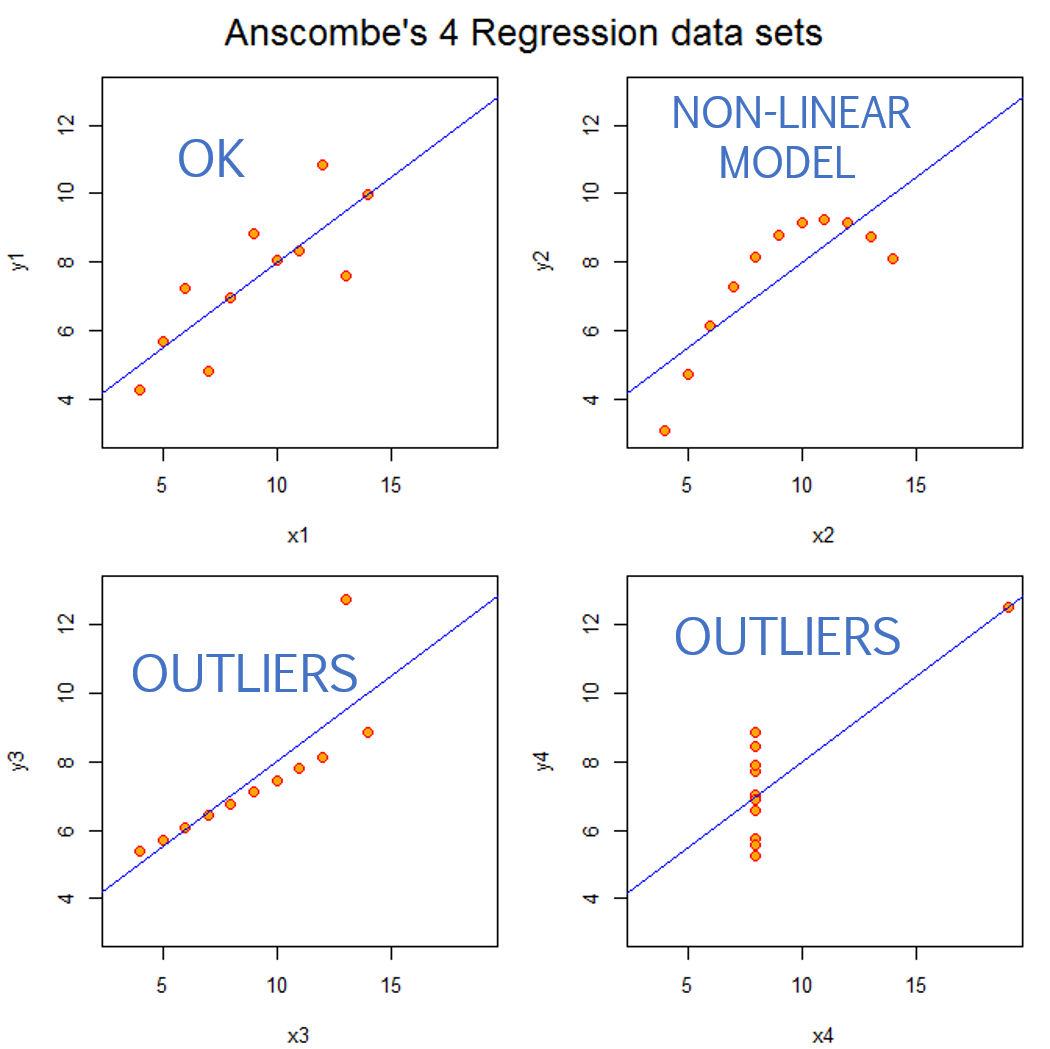
Specification Bias
Specification bias refers to incorrect slopes that arise from using an improper functional form for your model (for example, trying to model the relationship between X and Y with a straight line when a non-linearity is present), or situations where highly-leveraged outliers shift the slope.
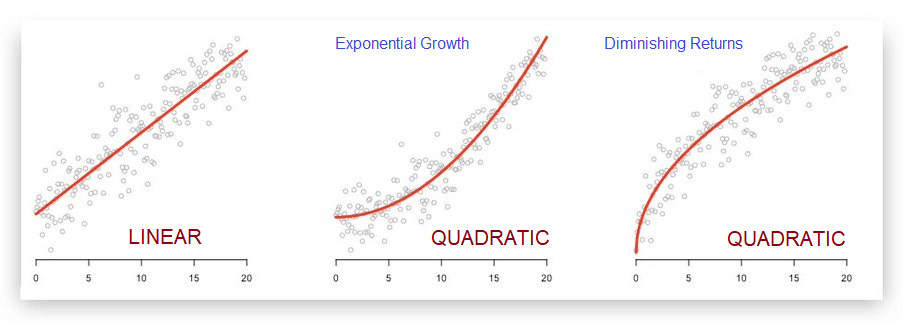
There are lots of reasons why the relationship between X and Y might not be linear. In ecology and in finance there are many processes that can lead to exponential growth. In economics it is very common to experience diminishing returns to investment, or diminishing marginal utility as more of a good is consumed (the 10th piece of cake eaten in one sitting is less enjoyable than the 1st piece).
We use quadratic regression equations to allow the model to capture non-linear relationships.
Linear specification:
Y = b0 + b1(X) + e
Quadratic specification:
Y = b0 + b1(X) + b2(X^2) + e
Log Regression Models
In certain circumstances the log transformations can be used to simplify regression models when:
- We want to model rates of growth instead of changes in levels.
- Our data is highly-skewed and we want to mitigate the impact of outliers.
In these instances, depending upon the variable(s) of interest, we can use one of the following log regression models:
# log-linear model
# one-unit change in X is associated with a b1 % change in Y
log(Y) = b0 + b1(X) + e
# linear-log model
# a 1% change in X is associated with a b1 unit change in Y
Y = b0 + b1(log(X)) + e
# log-log model
# a 1% change in X is associated with a b1 % change in Y (an elasticity)
log(Y) = b0 + b1(log(X)) + e
The log is a simple transformation in R:
log.x <- log( x )
Outliers
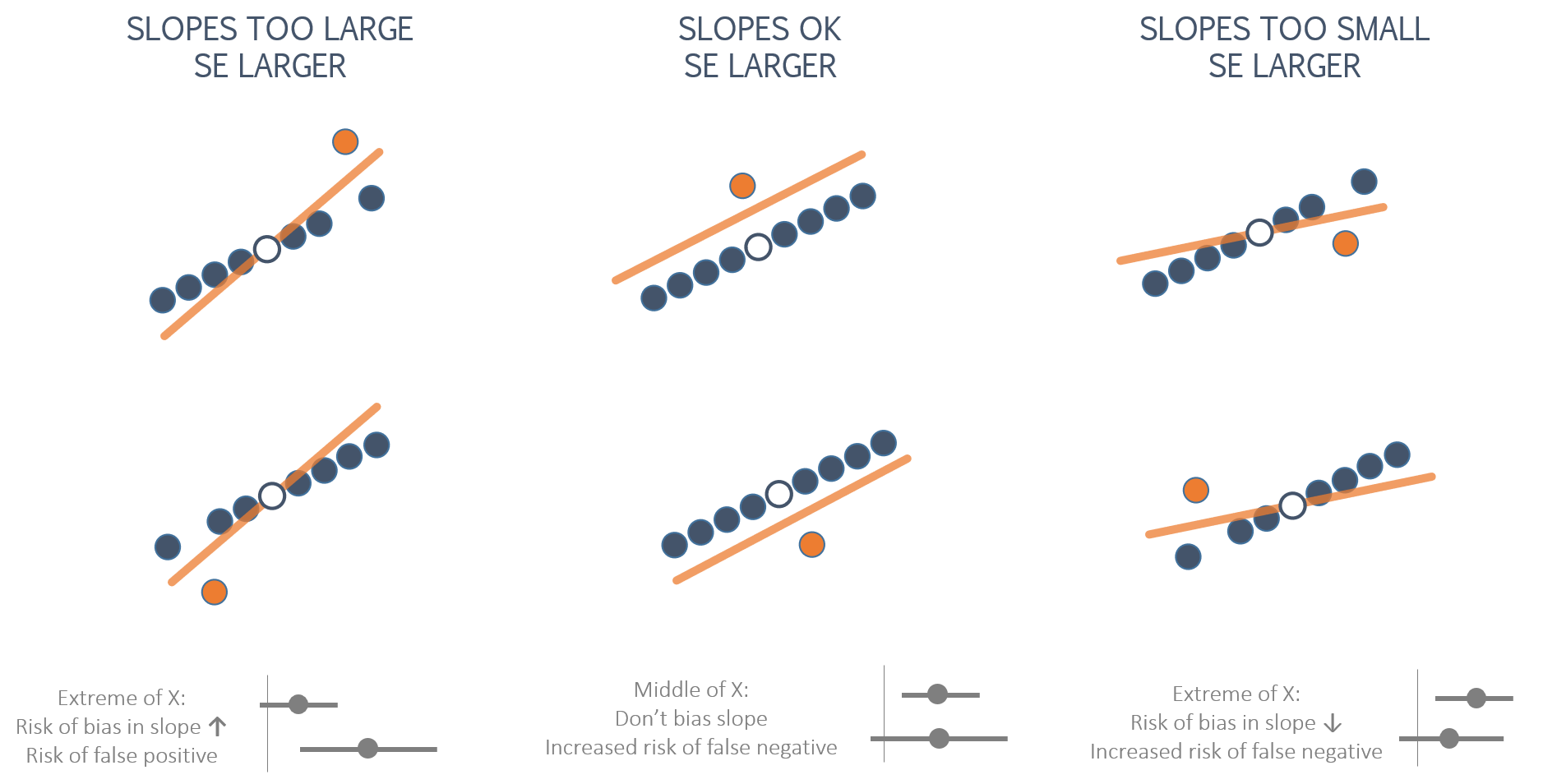
Outliers that occur near the min or max of X have the biggest impact on slopes because they will generate the largest residual term. The OLS regression technique tries to minimize squared residuals (sum of squared errors or SSE), so larger residuals have outsized influence.
For example, increase the size of a residual and note how much it then increases the SSE in the model:
2: 2^2 = 4
4: 4^2 = 16 (twice as large, 4 times as much influence)
2: 2^2 = 4
6: 6^2 = 36 (three times as large, 9 times as much influence)
2: 2^2 = 4
8: 8^2 = 64 (four times as large, 16 times as much influence)
As a result, the model that minimizes squared error terms will be disproportionately impacted by outliers.
When they occur in the extremes of X they bias the slope. When they occur near the mean of X they bias the intercept, and in doing so also increase standard errors.
Learning Objectives
Once you have completed this section you will be able to:
- Diagnose specification bias when it occurs
- Be able to identify outliers and conduct sensitivity analysis to check their impact
- Specify a quadratic model for non-linear relationships
- Interpret a logged regression
Lecture
Specification Bias I [ html ]
Specification Bias II [ pdf ]
For this lab you will run and interpret a quadratic regression and a logged regression model.
Lab 06
Due Saturday, October 3rd
This lab gives you a chance to practice non-linear regression models.
When you are complete:
Mini-Assessment 06
Open Thurs Oct 01 - Tues Oct 06
This mini assessment covers material from the Taxonomy of Controls.
And on Measurement Error. See the animated simulations below for examples of the effects of measurement error in the DV versus IVs. And see questions 3 and 4 on the review sheet for the same examples explained as Venn diagrams.
This mini assessment should give you an idea of the types of questions you might expect on the final exam.
THE IMPACT OF MEASUREMENT ERROR
Measurement Error in the DV:
Increase in standard errors. No slope bias.
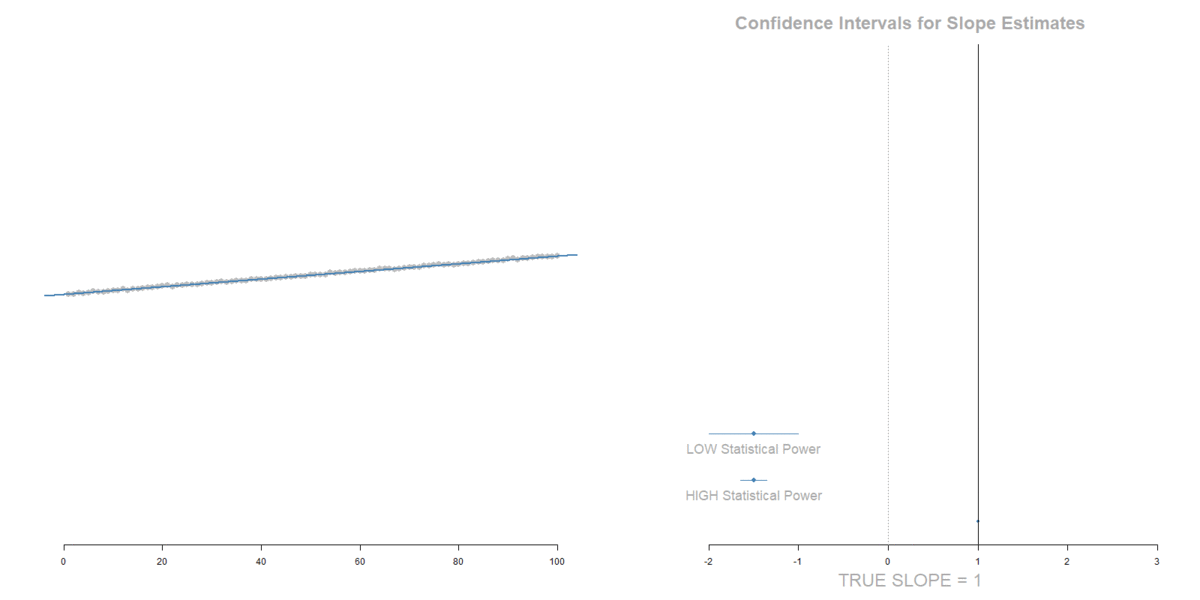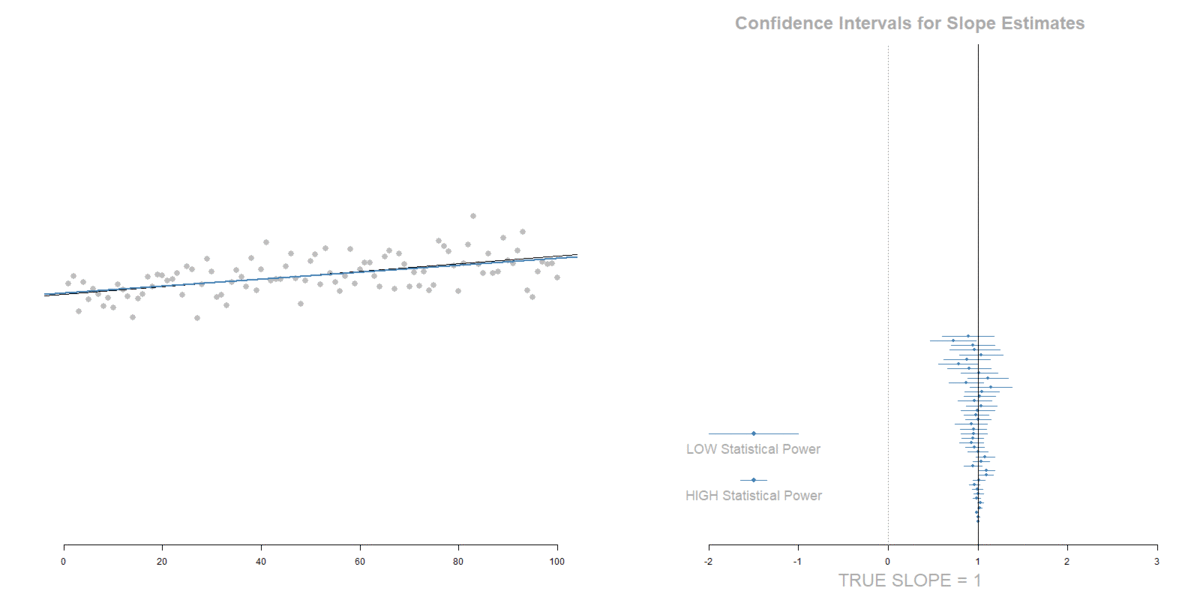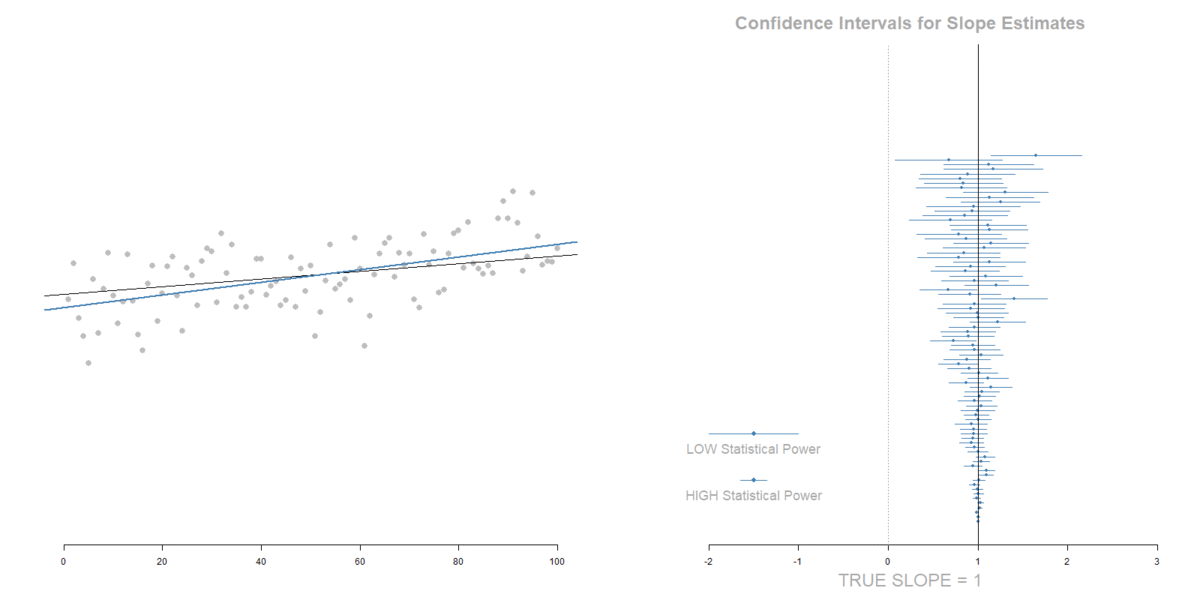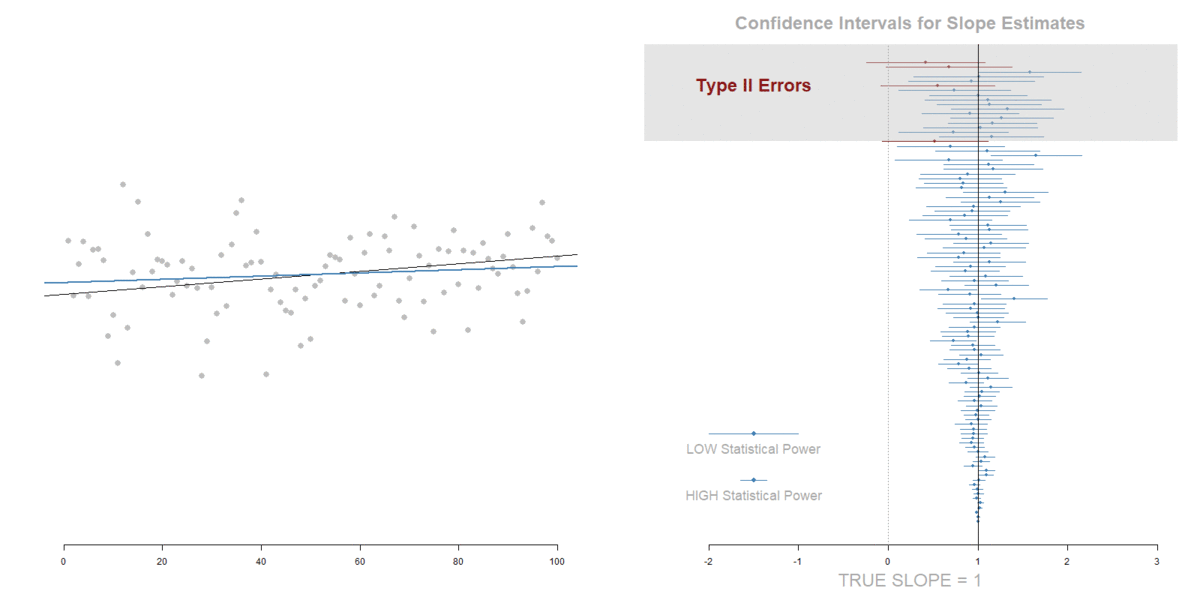
Measurement Error in the IV:
Attenuation of the slope (tilts toward zero), but also a decrease in standard errors that offset the shift of the slope toward zero.


Review Material
Please post questions on the discussion board if you are not sure of the correct solutions for questions on lectures or practice exams.
Practice Exams
Useful Summaries or Examples
The Seven Deadly Sins of Regression
Concise summary of the seven most common issues that will corrupt your regression inferences [ pdf ]
- Selection
- Omitted variable bias
- Measurement error
- Specification
- Group Heterogeneity
- Multi-collinearity
- Simultenaeity
Some longer notes: Seven Sins of Regression [ pdf ]
Measurement Error
Measurement Error in the DV:
Increase in standard errors. No slope bias.
Measurement Error in the IV:
Attenuation of the slope (tilts toward zero), but also a decrease in standard errors that offset the shift of the slope toward zero.
Final Exam
The exam is open Sat Oct 3rd - Fri Oct 9th.
The final exam is on Canvas. You have 4 hours to complete it once it is started.
You are NOT allowed to pause and return. The 4 hour limit starts once you begin the exam.
You are allowed to look back over your notes and use a calculator for help with math.
You are NOT allowed to work together on the final exam. Do NOT discuss questions after you have take it.