1 Merging Data
library( dplyr )
library( pander )This chapter demonstrates the process of joining two datasets through a merge() function. This is one of the most common and most important processes in data science, because it allows you to combine multiple datasets to link observations that pertain to the same individuals / cases. The deepest insights often come from bringing data together in this way.
2 Overview of Joins
2.1 Inner, Outer, Left and Right
There are two things to remember when conducting joins. The first is that when you merge two datasets it is rare for them both to contain the exact same observations. As a result, you need to make decisions about which data to keep and which data to drop post-merge. There are four options:
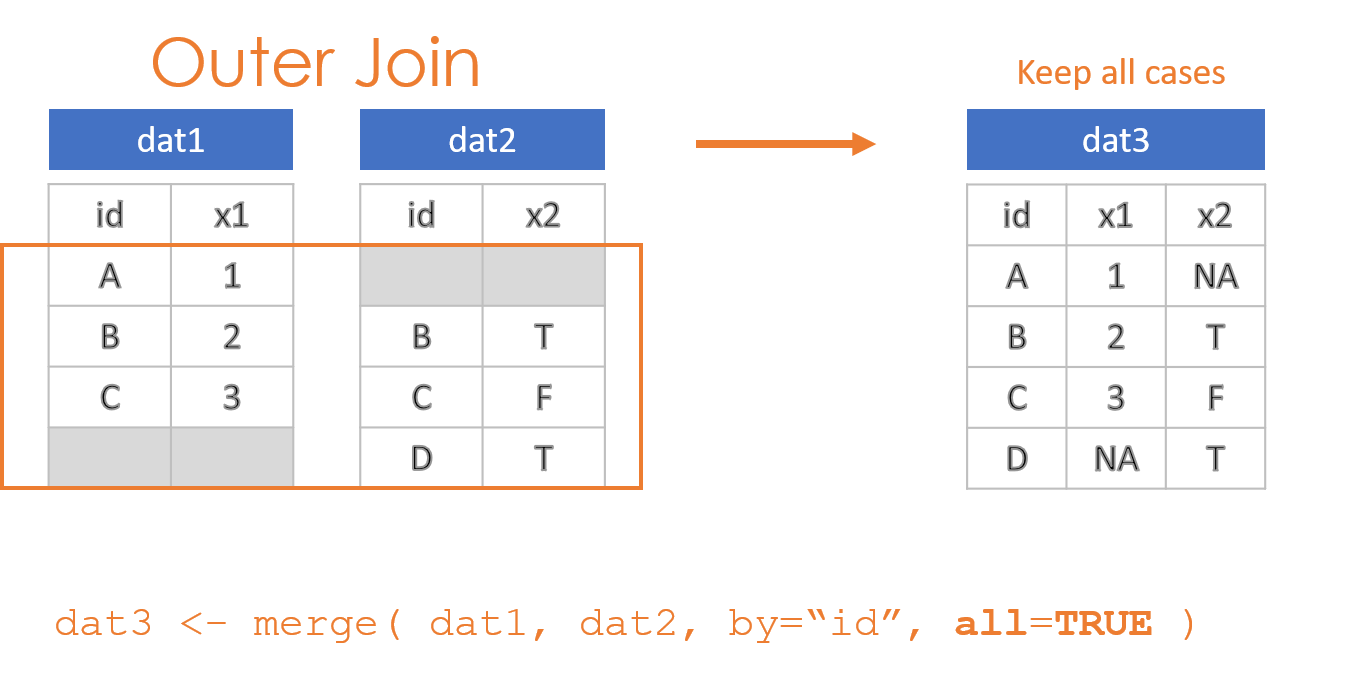
- Keep everything: “Outer Join”
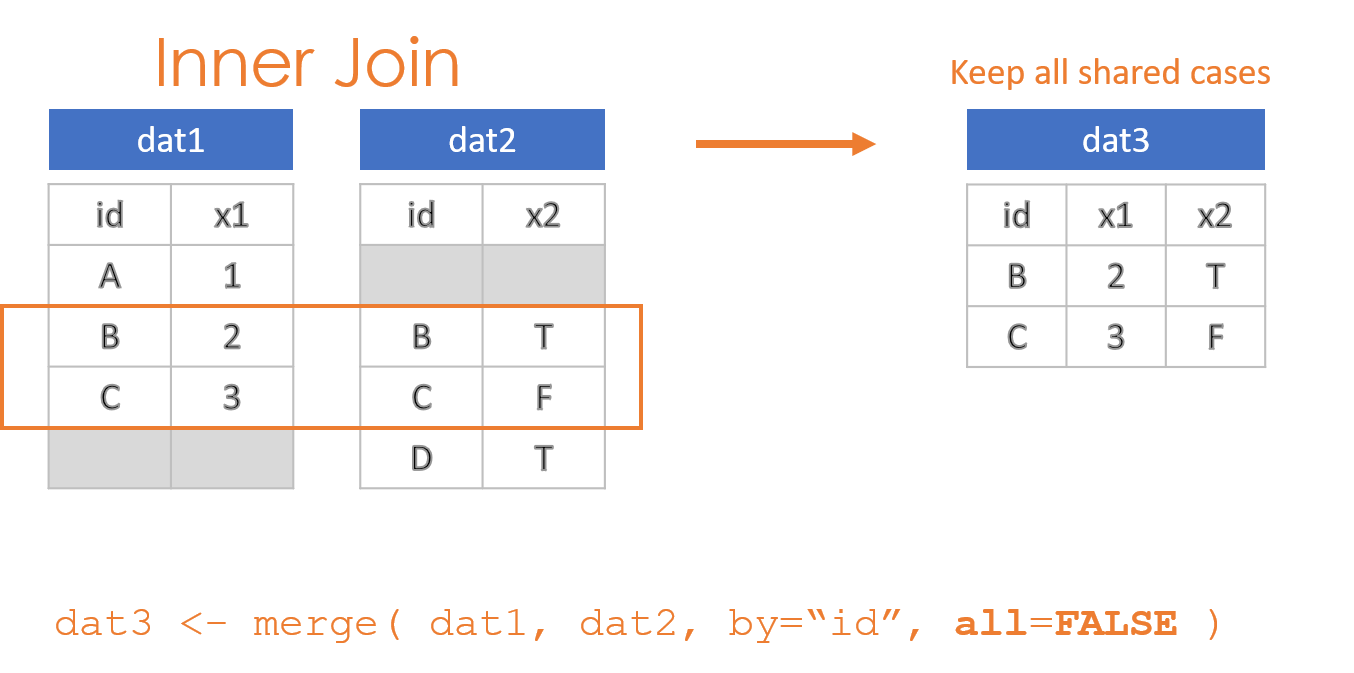
- Keep only observations in both datasets: “Inner Join”
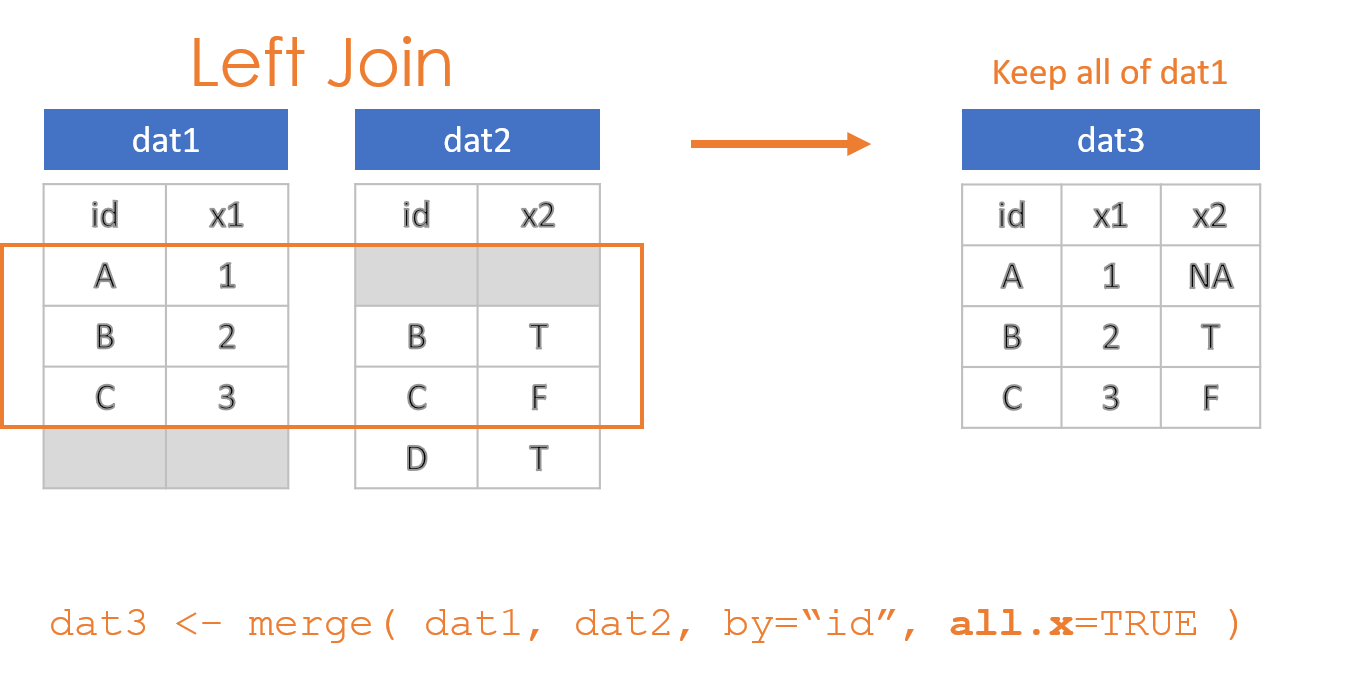
- Keep all observations from dat1: “Left Join”
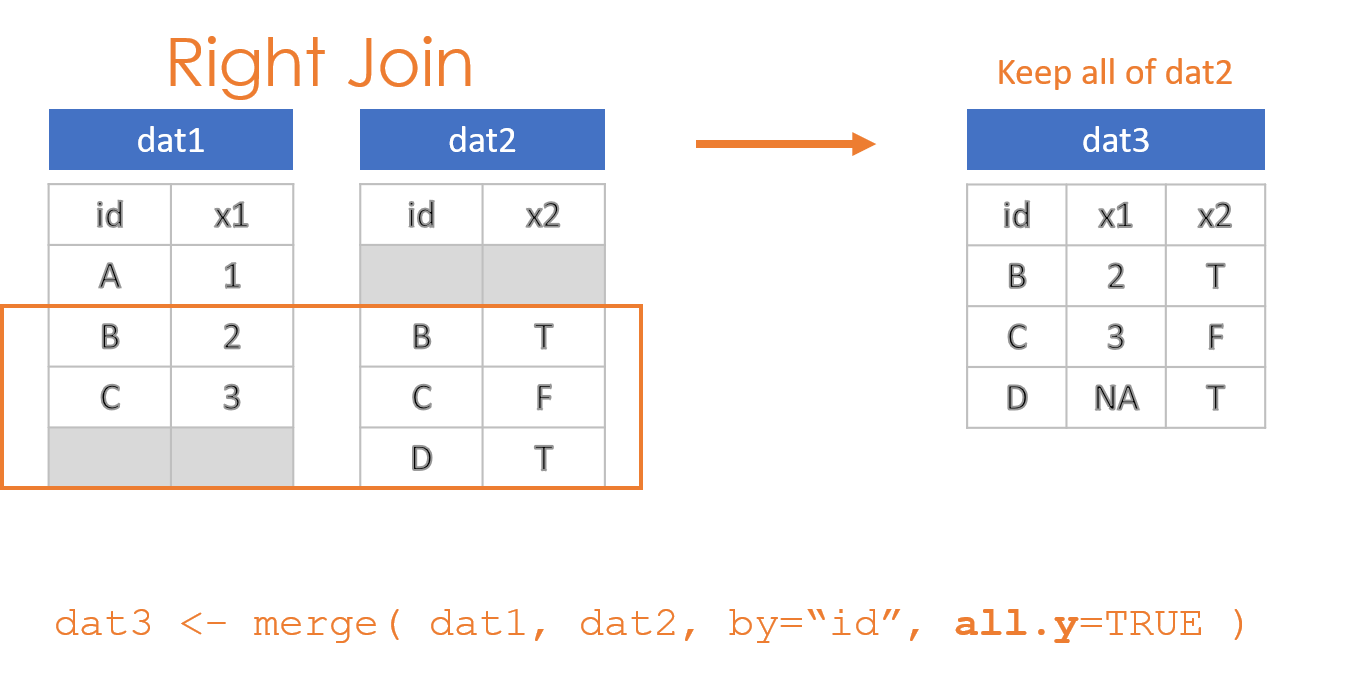
- Keep all observations from dat2: “Right Join”
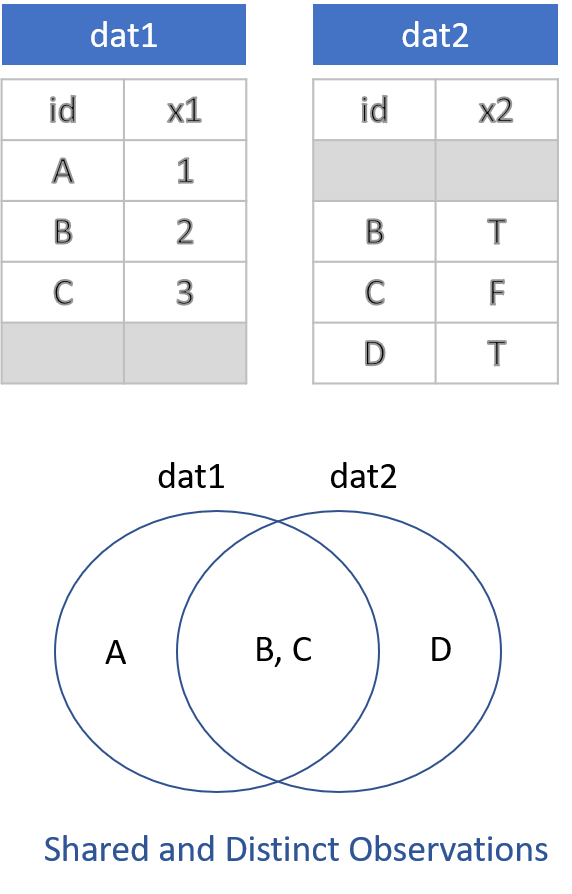
These options are specified through the all=, all.x=, and all.y= arguments in the merge() function, where the arguments all.x stands for observations in dat1, and all.y stands for observations in dat2 in this example.
2.2 Compound IDs
It is often the case where a single ID does not uniquely specify observations needed to join data. For example, if you are looking at the relationship between employee eye color and their height, these are both variables that can only have one value per employee, so the employee ID would be sufficient to merge the eye color and height datasets.
If we want to look at the relationship between employee sick days in a given year and their performance, we now might have multiple years of data for each employee. To merge these two datasets we need to use both ID and YEAR. This is an example of a compound ID - two or more variables are needed to create a unique key for the join.

Consider an example where sales representatives get a bonus if they sell over $100,000 in subscriptions each year. We have one database generated by the sales department, and another generated by HR. We want to merge them to ensure bonuses have been properly issued. The data tables are structured as follows:
| id | year | sales |
|---|---|---|
| A | 2001 | 54000 |
| A | 2002 | 119000 |
| B | 2001 | 141000 |
| B | 2002 | 102000 |
| C | 2001 | 66000 |
| C | 2002 | 68000 |
| id | year | bonus |
|---|---|---|
| A | 2001 | FALSE |
| A | 2002 | TRUE |
| B | 2001 | TRUE |
| B | 2002 | TRUE |
| C | 2001 | FALSE |
| C | 2002 | FALSE |
The RIGHT way to merge these tables is to specify the set of IDs that allow you to identify unique observations. The employee ID is not sufficient in this case because there are separate observations for each year. As a result:
merge( dat1, dat2, by=c("id","year") ) %>% pander()| id | year | sales | bonus |
|---|---|---|---|
| A | 2001 | 54000 | FALSE |
| A | 2002 | 119000 | TRUE |
| B | 2001 | 141000 | TRUE |
| B | 2002 | 102000 | TRUE |
| C | 2001 | 66000 | FALSE |
| C | 2002 | 68000 | FALSE |
The WRONG way to merge these two datasets is to use only the employee ID. In this case, since the rows are now no longer unique, the only choice the merge() function has is to join EVERY instance on the right to each instance on the left. It has the effect of blowing up the size of the database (notice we have increased from 6 to 12 rows), as well as duplicating fields and incorrectly aligning data.
Row number 2, for example, reports that employee A received a bonus on $54,000 in sales.
merge( dat1, dat2, by="id" ) %>% pander()| id | year.x | sales | year.y | bonus |
|---|---|---|---|---|
| A | 2001 | 54000 | 2001 | FALSE |
| A | 2001 | 54000 | 2002 | TRUE |
| A | 2002 | 119000 | 2001 | FALSE |
| A | 2002 | 119000 | 2002 | TRUE |
| B | 2001 | 141000 | 2001 | TRUE |
| B | 2001 | 141000 | 2002 | TRUE |
| B | 2002 | 102000 | 2001 | TRUE |
| B | 2002 | 102000 | 2002 | TRUE |
| C | 2001 | 66000 | 2001 | FALSE |
| C | 2001 | 66000 | 2002 | FALSE |
| C | 2002 | 68000 | 2001 | FALSE |
| C | 2002 | 68000 | 2002 | FALSE |
The solution is to ensure you are using the combination of keys that ensures each observation is correctly specified.
2.3 Merge Keys
Your “keys” are the shared IDs across your datasets used for the join. You can check for shared variable names by looking at the intersection of names in both:
intersect( names(dat1), names(dat2) )## [1] "id" "year"This works when the datasets were generated from a common system that uses standardized and identical ID names. In other cases, the same key may be spelled differently (‘year’ vs. ‘YEAR’) or have completely different names.
The check above at least allows you to catch instances where variable names would be repeated, and thus duplicated in the merged file. When this happens, like the ‘year’ variable in the example above, the merge operation will add an ‘x’ and ‘y’ to the end of the variable names to specify which dataset they originated from (‘year.x’ and ‘year.y’ in the example above).
In instances where variable names differ, you can specify the names directly using “by.x=” and “by.y=”:
merge( dat1, dat2, by.x="fips", by.y="FIPS" ) 2.4 In Summary
You will be using the merge() function in this lab to join datasets. You need to specify two arguments in each merge call.
merge( dat1, dat2, by="", all="" )Your IDs used to join dataset:
- Use “by=” when variable names are identical
- Use “by.x=” and “by.y=” when the variable names are spelled differently
- Remember the c() when you have a compound key: by=c(“FIPS”,“YEAR”)
Specify an outer, inner, left, or right join:
- all=TRUE creates an outer join
- all=FALSE creates an inner join
- all.x=TRUE creates a left join
- all.y=TRUE creates a right join